Gezien de toenemende cyberdreigingen en de implementatie van dataprivacywetgeving zoals de GDPR in de EU of CCPA in de VS, moeten bedrijven ervoor zorgen dat privégegevens zo min mogelijk worden gebruikt. Data masking biedt een manier om het gebruik van privégegevens te beperken en tegelijkertijd bedrijven in staat te stellen hun systemen te testen met gegevens die zo dicht mogelijk bij echte gegevens liggen.
De gemiddelde kosten van een datalek bedroegen in 2019 4 miljoen dollar. Dit creëert een sterke stimulans voor bedrijven om te investeren in informatiebeveiligingsoplossingen, waaronder data masking, om gevoelige gegevens te beschermen. Data masking is een must-have oplossing voor organisaties die willen voldoen aan de GDPR of realistische data willen gebruiken in een testomgeving.
- Wat is data masking?
- Waarom is data masking nu belangrijk?
- Hoe werkt data masking?
- Wat zijn de soorten data masking?
- Wat zijn de technieken van data masking?
- Geschikt voor het beheer van testgegevens
- Substitutie
- Shuffling
- Nummer- en datumvariantie
- Encryptie
- Character Scrambling
- Geschikt voor het delen van gegevens met onbevoegde gebruikers
- Null out or Deletion
- Masking out
- Wat is het verschil tussen data masking en synthetische data?
- Voor welke soorten gegevens is data-afscherming nodig?
- Hoe bevordert GDPR het maskeren van gegevens?
- Wat zijn enkele voorbeelden van data masking case studies?
- Independence Health Group
- Samsung
- Wat zijn de beste praktijken van gegevensmaskering?
- Wat zijn de toonaangevende tools voor gegevensafscherming?
Wat is data masking?
Data masking wordt ook wel data obfuscation, data anonymization, of pseudonymization genoemd. Het is het proces waarbij vertrouwelijke gegevens worden vervangen door functionele fictieve gegevens, zoals tekens of andere gegevens. Het hoofddoel van data masking is het beschermen van gevoelige, privé-informatie in situaties waarin de onderneming gegevens deelt met derden.
Waarom is data masking nu belangrijk?
Het aantal datalekken neemt elk jaar toe (Vergeleken met halverwege 2018 is het aantal geregistreerde inbreuken in 2019 met 54% gestegen) Daarom moeten organisaties hun gegevensbeveiligingssystemen verbeteren. De behoefte aan datamaskering neemt toe vanwege de volgende redenen:
- Organisaties hebben een kopie van productiedata nodig wanneer ze besluiten deze te gebruiken voor niet-productieredenen, zoals het testen van applicaties of het modelleren van bedrijfsanalyses.
- Het dataprivacybeleid van uw onderneming wordt ook bedreigd door insiders. Daarom moeten organisaties nog steeds voorzichtig zijn met het verlenen van toegang aan werknemers met insiders. Volgens 2019 Insider Data Breach survey,
- 79% van de CIO’s denkt dat werknemers in de afgelopen 12 maanden per ongeluk bedrijfsgegevens in gevaar hebben gebracht, terwijl 61% denkt dat werknemers op kwaadwillende wijze bedrijfsgegevens in gevaar hebben gebracht.
- 95% erkent dat beveiligingsrisico’s van binnenuit een gevaar zijn voor hun organisatie
- GDPR en CCPA dwingen bedrijven om hun gegevensbeschermingssystemen te versterken, anders moeten organisaties fikse boetes betalen.
Hoe werkt data masking?
Data masking proces is eenvoudig, maar, het heeft verschillende technieken en soorten. In het algemeen beginnen organisaties met het identificeren van alle gevoelige gegevens die uw onderneming bezit. Vervolgens gebruiken ze algoritmen om gevoelige gegevens te maskeren en te vervangen door structureel identieke, maar numeriek verschillende gegevens. Wat bedoelen we met structureel identiek? Paspoortnummers bestaan in de VS bijvoorbeeld uit 9 cijfers en personen moeten hun paspoortgegevens meestal delen met luchtvaartmaatschappijen. Wanneer een luchtvaartmaatschappij een model maakt om de bedrijfsomgeving te analyseren en te testen, maakt ze een andere 9-cijferige lange paspoort-ID of vervangt ze sommige cijfers door tekens.
Hier vindt u een voorbeeld van hoe data masking werkt:
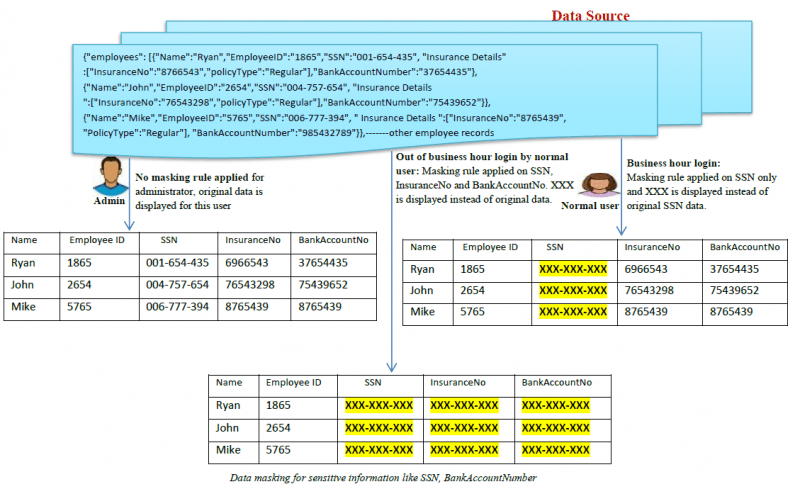
Wat zijn de soorten data masking?
- Statische data-afscherming (SDM): Bij SDM worden de gegevens in de oorspronkelijke database afgeschermd en vervolgens in een testomgeving gedupliceerd, zodat bedrijven de testgegevensomgeving kunnen delen met externe verkopers.
- Dynamische gegevensafscherming (DDM): Bij DDM is er geen behoefte aan een tweede gegevensbron om de afgeschermde gegevens dynamisch op te slaan. De oorspronkelijke gevoelige gegevens blijven in de opslagplaats en zijn toegankelijk voor een
toepassing wanneer die door het systeem is geautoriseerd. Gegevens worden nooit blootgesteld aan onbevoegde gebruikers, de inhoud wordt on-demand in real-time geschud om de inhoud te maskeren. Alleen geautoriseerde gebruikers kunnen de authentieke gegevens zien. Over het algemeen wordt een reverse proxy gebruikt om DDM tot stand te brengen. Andere dynamische methoden om DDM te bereiken worden over het algemeen on-the-fly data masking genoemd.
Wat zijn de technieken van data masking?
Er zijn talrijke technieken om gegevens te maskeren en wij hebben ze ingedeeld volgens hun gebruik.
Geschikt voor het beheer van testgegevens
Substitutie
In de substitutiebenadering, zoals de naam aangeeft, vervangen bedrijven de oorspronkelijke gegevens door willekeurige gegevens uit verstrekte of aangepaste lookup-bestanden. Dit is een efficiënte manier om gegevens te verhullen aangezien de bedrijven het authentieke blik van gegevens behouden.
Shuffling
Shuffling is een andere gemeenschappelijke gegevens maskerende methode. Bij de shuffling-methode vervangen bedrijven, net als bij substitutie, de oorspronkelijke gegevens door een ander authentiek uitziend gegeven, maar ze husselen de entiteiten in dezelfde kolom willekeurig.
Nummer- en datumvariantie
Voor financiële en datumgestuurde datasets verandert het toepassen van dezelfde variantie om een nieuwe dataset te maken niets aan de nauwkeurigheid van de dataset terwijl de gegevens worden afgeschermd. Het gebruik van variantie om een nieuwe dataset te maken wordt ook vaak gebruikt bij het genereren van synthetische gegevens. Als u van plan bent de privacy van gegevens met deze techniek te beschermen, raden wij u aan onze uitgebreide gids voor het genereren van synthetische gegevens te lezen.
Encryptie
Encryptie is het meest complexe algoritme voor het afschermen van gegevens. Gebruikers hebben alleen toegang tot de gegevens als ze de decoderingssleutel hebben.
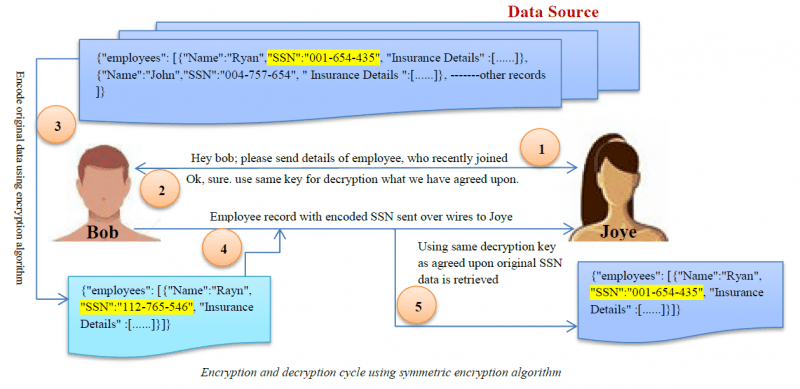
Character Scrambling
Bij deze methode wordt de volgorde van karakters willekeurig herschikt. Dit proces is onomkeerbaar, zodat de oorspronkelijke gegevens niet uit de vervormde gegevens kunnen worden verkregen.
Geschikt voor het delen van gegevens met onbevoegde gebruikers
Null out or Deletion
Het vervangen van gevoelige gegevens door een null-waarde is ook een aanpak die bedrijven kunnen verkiezen bij hun pogingen om gegevens te maskeren. Hoewel het de nauwkeurigheid van de testresultaten vermindert, die bij andere benaderingen meestal worden gehandhaafd, is het een eenvoudiger aanpak wanneer bedrijven niet afschermen vanwege modelvalidatiedoeleinden.
Masking out
In de afschermmethode wordt slechts een deel van de oorspronkelijke gegevens afgeschermd. Het is vergelijkbaar met nulling out, omdat het niet effectief is in de testomgeving. Bij online winkelen worden bijvoorbeeld alleen de laatste 4 cijfers van het creditcardnummer aan klanten getoond om fraude te voorkomen.
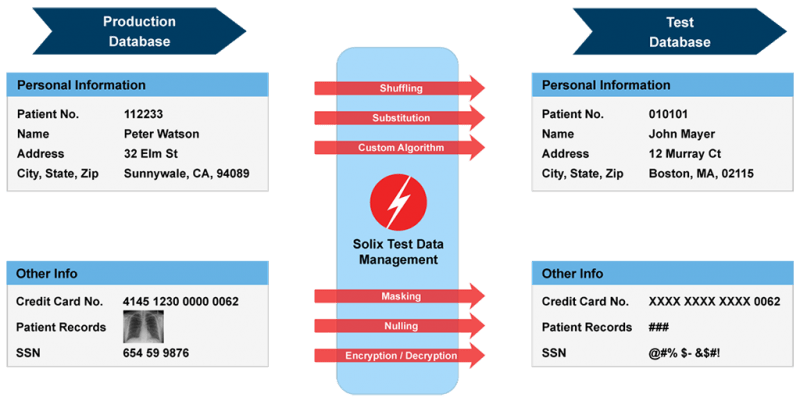
Bron: Solix Technologies
Wat is het verschil tussen data masking en synthetische data?

Om testgegevens te creëren die voldoen aan de GDPR-voorschriften, hebben organisaties twee opties: synthetische data genereren of data maskeren met verschillende algoritmen. Hoewel deze twee testtechnieken hetzelfde doel dienen, heeft elke methode verschillende voordelen en risico’s.
Data masking is het proces waarbij een kopie van real-world gegevens wordt gemaakt die in specifieke velden binnen een dataset worden verborgen. Maar zelfs als de organisatie de meest complexe en uitgebreide technieken voor gegevensafscherming toepast, is er een kleine kans dat iemand individuele personen kan identificeren op basis van trends in de afgeschermde gegevens. Daarom bestaat het risico dat informatie wordt vrijgegeven aan derden.
Aan de andere kant zijn synthetische gegevens gegevens die kunstmatig zijn gecreëerd in plaats van door werkelijke gebeurtenissen te zijn gegenereerd. Zij bevatten geen echte informatie over personen, maar worden gecreëerd op basis van het gegevensmodel of de berichtenmodellen die een bedrijf voor zijn productiesystemen gebruikt. In gevallen waarin een bedrijf een geheel nieuwe toepassing test of van mening is dat hun data-afscherming niet voldoende is, is het gebruik van synthetische gegevens het antwoord.
Voor welke soorten gegevens is data-afscherming nodig?
- Persoonlijk identificeerbare informatie (PII): Alle gegevens die mogelijk kunnen worden gebruikt om een bepaalde persoon te identificeren. Bijvoorbeeld volledige naam, sofi-nummer, rijbewijsnummer en paspoortnummer.
- Beschermde gezondheidsinformatie (PHI): PHI omvat demografische informatie, medische voorgeschiedenis, test- en laboratoriumresultaten, geestelijke gezondheidstoestanden, verzekeringsinformatie en andere gegevens die een beroepsbeoefenaar in de gezondheidszorg verzamelt om de juiste zorg vast te stellen.
- Betaalkaartinformatie (PCI-DSS): Er is een informatiebeveiligingsnorm die organisaties moeten volgen bij het omgaan met merkcreditcards van de grote kaartsystemen.
- Intellectueel eigendom (IP): IP verwijst naar creaties van de geest, zoals uitvindingen; literaire en artistieke werken; ontwerpen; en symbolen, namen en afbeeldingen die in de handel worden gebruikt.
Hoe bevordert GDPR het maskeren van gegevens?
Data masking wordt door GDPR geaccepteerd als een techniek om de gegevens van individuen te beschermen. Hier zijn de gerelateerde artikelen waar GDPR bedrijven aanmoedigt om pseudonimisering te gebruiken:
Artikel 6 (4-e): ” het bestaan van passende waarborgen, waaronder eventueel encryptie of pseudonimisering.”
Artikel 25 (1): “Rekening houdend met de stand van de techniek, de kosten van de tenuitvoerlegging en de aard, de omvang, de context en de doeleinden van de verwerking, alsmede met de aan de verwerking verbonden risico’s die qua waarschijnlijkheid en ernst kunnen verschillen voor de rechten en vrijheden van natuurlijke personen, treft de voor de verwerking verantwoordelijke, zowel bij de vaststelling van de middelen voor de verwerking als bij de verwerking zelf, passende technische en organisatorische maatregelen treffen, zoals pseudonimisering, die gericht zijn op een doeltreffende toepassing van de beginselen inzake gegevensbescherming, zoals gegevensminimalisering, en op de integratie van de nodige waarborgen in de verwerking, teneinde aan de vereisten van deze verordening te voldoen en de rechten van de betrokkenen te beschermen”
Artikel 32, onder a): “De voor de verwerking verantwoordelijke en de verwerker treffen passende technische en organisatorische maatregelen om een op het risico afgestemd beveiligingsniveau te waarborgen, waaronder in voorkomend geval: pseudonimisering en versleuteling van persoonsgegevens.”
Artikel 40, lid 2: “Verenigingen en andere organen die categorieën voor de verwerking verantwoordelijken of verwerkers vertegenwoordigen, kunnen gedragscodes opstellen of deze wijzigen of uitbreiden, teneinde de toepassing van deze verordening nader te bepalen, bijvoorbeeld met betrekking tot:
- d) de pseudonimisering van persoonsgegevens
Artikel 89, lid 1: “Verwerking ten behoeve van archivering in het algemeen belang, wetenschappelijk of historisch onderzoek of statistische doeleinden, is onderworpen aan passende waarborgen, waaronder het minimaliseren van gegevens en pseudonimisering”
Wat zijn enkele voorbeelden van data masking case studies?
Independence Health Group
Independence Health Group is de toonaangevende ziektekostenverzekeraar die een breed scala aan diensten aanbiedt, waaronder commerciële, Medicare- en Medicaid-medische dekking, beheer van uitkeringen door derden, beheer van apotheekuitkeringen en werknemerscompensatie. Independence Health wilde interne en externe ontwikkelaars in staat stellen applicaties te testen met echte data, maar moest wel PHI en andere persoonlijk identificeerbare informatie afschermen. Ze besloten Informatica Dynamic Data Masking te gebruiken om namen, geboortedata, sofinummers (SSN’s) en andere gevoelige data van leden in real-time te verhullen terwijl ontwikkelaars datasets ophalen.
Met een oplossing voor data-afscherming kan Independence Health gevoelige data van klanten beter beschermen, waardoor de potentiële kosten van een datalek afnemen.
Samsung
Samsung werkt aan de analyse en productie van mobiele en smart-tv-producten over de hele wereld. Tijdens het uitvoeren van productanalyses op miljoenen Samsung Galaxy Smartphone-apparaten, moet het bedrijf persoonlijke privégegevens beschermen in overeenstemming met de regels en procedures van de lokale regelgeving.
Om de wettelijke naleving van de persoonlijke levenssfeer te waarborgen, is Samsung een samenwerking aangegaan met Dataguise. Dataguise’s tool voor Hadoop ontdekt automatisch privacygegevens van consumenten en versleutelt deze voordat de gegevens naar AWS-analysetools worden gemigreerd, zodat alleen geautoriseerde gebruikers toegang hebben tot en analyses kunnen uitvoeren op echte gegevens.
Wat zijn de beste praktijken van gegevensmaskering?
- Zorg ervoor dat u alle gevoelige gegevens in de database van de onderneming hebt ontdekt voordat u deze naar de testomgeving overbrengt.
- Begrijp uw gevoelige gegevens en identificeer dienovereenkomstig de meest geschikte techniek voor gegevensafscherming.
- Gebruik onomkeerbare methoden, zodat uw gegevens niet kunnen worden teruggevormd naar de oorspronkelijke versie.
Wat zijn de toonaangevende tools voor gegevensafscherming?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (voor DDM)
- Informatica Persistent Data Masking (voor SDM)
- Mentis
- Oracle Advanced Security (voor DDM)
- Oracle’s Data Masking and Subsetting Pack (voor SDM)
- Privacy Analytics
- Solix Data Masking
Als u geïnteresseerd bent in andere beveiligingsoplossingen om uw bedrijfsgegevens te beschermen tegen cyberdreigingen, volgt hieronder een aanbevolen leeslijst voor u:
- Endpoint Security: in-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Verdedigen tegen AI-aangedreven cyberaanvallen
- Managed Security Services (MSS): Comprehensive Guide
- Security Analytics: The Ultimate Guide
- Deception Technology: in-deepth Guide