Az egyre növekvő kiberfenyegetések és az olyan adatvédelmi jogszabályok, mint az EU-ban a GDPR vagy az USA-ban a CCPA végrehajtása miatt a vállalkozásoknak biztosítaniuk kell, hogy a személyes adatokat a lehető legkevésbé használják fel. Az adatmaszkolás módot nyújt a magánadatok használatának korlátozására, miközben lehetővé teszi a vállalkozások számára, hogy a valós adatokhoz a lehető legközelebb álló adatokkal teszteljék rendszereiket.
Az adatbetörés átlagos költsége 2019-ben 4 millió dollár volt. Ez erősen ösztönzi a vállalkozásokat arra, hogy beruházzanak információbiztonsági megoldásokba, köztük az adatmaszkolásba az érzékeny adatok védelme érdekében. Az adatmaszkolás elengedhetetlen megoldás azon szervezetek számára, amelyek meg kívánnak felelni a GDPR-nak, vagy valós adatokat kívánnak használni tesztelési környezetben.
- Mi az adatmaszkolás?
- Miért fontos most az adatmaszkolás?
- Hogyan működik az adatmaszkolás?
- Milyen típusai vannak az adatmaszkolásnak?
- Melyek az adatmaszkolás technikái?
- Alkalmas a tesztadatok kezelésére
- Substitution
- Shuffling
- Szám- és dátumvariáció
- Titkosítás
- Character Scrambling
- Alkalmas az adatok illetéktelen felhasználókkal való megosztására
- Nulling out or Deletion
- Maszkolás ki
- Miben különbözik az adatmaszkolás a szintetikus adatoktól?
- Milyen típusú adatok igényelnek adatmaszkolást?
- Hogyan segíti elő a GDPR az adatok elfedését?
- Milyen példák vannak az adatmaszkolás esettanulmányaira?
- Independence Health Group
- Samsung
- Mik az adatmaszkolás legjobb gyakorlatai?
- Melyek a vezető adatmaszkoló eszközök?
Mi az adatmaszkolás?
Az adatmaszkírozást adatelhomályosításnak, adatanonimizálásnak vagy álnevesítésnek is nevezik. Ez az a folyamat, amelynek során a bizalmas adatokat funkcionális fiktív adatok, például karakterek vagy más adatok használatával helyettesítik. Az adatmaszkolás fő célja az érzékeny, bizalmas információk védelme olyan helyzetekben, amikor a vállalkozás adatokat oszt meg harmadik felekkel.
Miért fontos most az adatmaszkolás?
Az adatvédelmi incidensek száma évről évre növekszik (2018 év közepéhez képest 2019-ben a regisztrált adatvédelmi incidensek száma 54%-kal nőtt) Ezért a szervezeteknek javítaniuk kell adatbiztonsági rendszereiket. Az adatmaszkolás iránti igény a következő okok miatt növekszik:
- A szervezeteknek szükségük van a termelési adatok másolatára, ha úgy döntenek, hogy azokat nem termelési célokra, például alkalmazástesztelésre vagy üzleti analitikai modellezésre használják.
- A vállalat adatvédelmi szabályzatát a bennfentesek is veszélyeztetik. Ezért a szervezeteknek továbbra is óvatosnak kell lenniük a bennfentes alkalmazottak hozzáférésének engedélyezése során. A 2019-es Insider Data Breach felmérés szerint
- A CIO-k 79%-a úgy véli, hogy az alkalmazottak az elmúlt 12 hónapban véletlenül, míg 61%-a szerint az alkalmazottak rosszindulatúan veszélyeztették a vállalati adatokat.
- 95% ismeri el, hogy a belső biztonsági fenyegetések veszélyt jelentenek a szervezetükre
- A GDPR és a CCPA arra kényszeríti a vállalkozásokat, hogy megerősítsék adatvédelmi rendszereiket, különben a szervezeteknek súlyos bírságokat kell fizetniük.
Hogyan működik az adatmaszkolás?
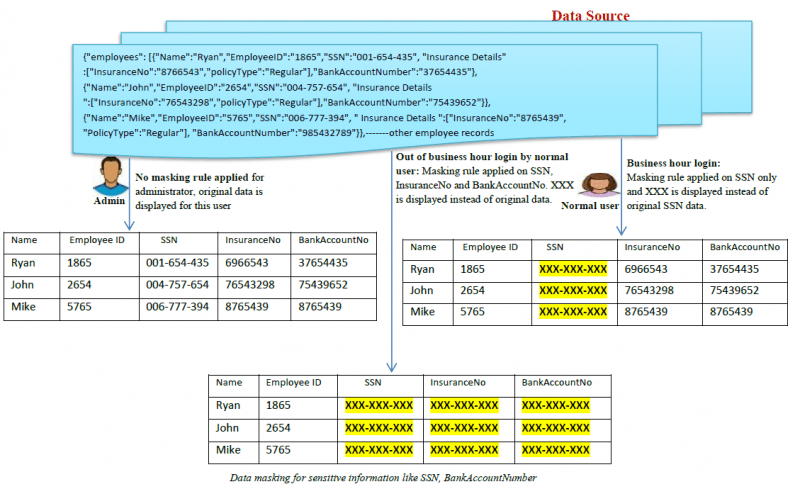
Az adatmaszkolás folyamata egyszerű, mégis, különböző technikák és típusok léteznek. Általában a szervezetek azzal kezdik, hogy azonosítják az összes érzékeny adatot, amellyel a vállalkozás rendelkezik. Ezután algoritmusok segítségével elfedik az érzékeny adatokat, és szerkezetileg azonos, de számszerűen eltérő adatokkal helyettesítik azokat. Mit értünk szerkezetileg azonos alatt? Az USA-ban például az útlevélszámok 9 számjegyűek, és az egyéneknek általában meg kell osztaniuk az útlevéladataikat a légitársaságokkal. Amikor egy légitársaság az üzleti környezet elemzéséhez és teszteléséhez modellt készít, egy másik 9 számjegyű hosszú útlevél-azonosítót hoz létre, vagy néhány számjegyet karakterekkel helyettesít.
Itt egy példa arra, hogyan működik az adatmaszkolás:
Milyen típusai vannak az adatmaszkolásnak?
- Statikus adatmaszkolás (SDM):
- Dinamikus adatmaszkolás (DDM): Az SDM során az adatokat az eredeti adatbázisban maszkolják, majd egy tesztkörnyezetbe duplikálják, hogy a vállalkozások megoszthassák a tesztadat-környezetet harmadik fél beszállítóival.
- Dinamikus adatmaszkolás (DDM): A DDM-ben nincs szükség második adatforrásra a maszkolt adatok dinamikus tárolásához. Az eredeti érzékeny adatok az adattárban maradnak, és egy
alkalmazás számára hozzáférhetők, ha a rendszer engedélyezi őket. Az adatok soha nincsenek kitéve az illetéktelen felhasználóknak, a tartalmak valós időben, igény szerint keverednek, hogy a tartalmak maszkoltak legyenek. Csak az engedélyezett felhasználók láthatják a hiteles adatokat. A DDM megvalósításához általában fordított proxy-t használnak. A DDM elérésének egyéb dinamikus módszereit általában on-the-fly adatmaszkolásnak nevezik.
Melyek az adatmaszkolás technikái?
Számos adatmaszkírozási technika létezik, és ezeket a felhasználási esetük szerint osztályoztuk.
Alkalmas a tesztadatok kezelésére
Substitution
A substitution megközelítésben, ahogy a neve is utal rá, a vállalkozások az eredeti adatokat véletlenszerű adatokkal helyettesítik a szállított vagy testre szabott lookup fájlból származó adatokkal. Ez az adatok álcázásának hatékony módja, mivel a vállalkozások megőrzik az adatok autentikus megjelenését.
Shuffling
A shuffling egy másik gyakori adatmaszkírozási módszer. A keverési módszerben a helyettesítéshez hasonlóan a vállalkozások az eredeti adatokat egy másik, hiteles kinézetű adattal helyettesítik, de véletlenszerűen keverik az entitásokat ugyanabban az oszlopban.
Szám- és dátumvariáció
A pénzügyi és dátumvezérelt adatkészletek esetében az adatok maszkolásakor az új adatkészlet létrehozásához azonos variancia alkalmazása nem változtatja meg az adatkészlet pontosságát. A variancia alkalmazása egy új adatkészlet létrehozásához a szintetikus adatok generálásánál is gyakran használatos. Ha ezzel a technikával tervezi az adatvédelem védelmét, javasoljuk, hogy olvassa el a szintetikus adatgenerálásról szóló átfogó útmutatónkat.
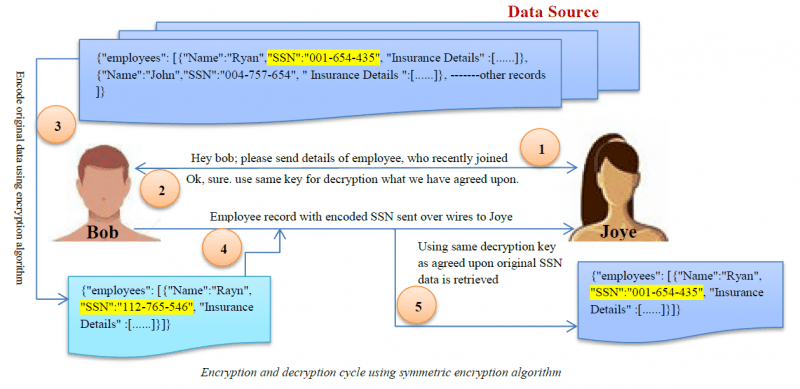
Titkosítás
A titkosítás a legösszetettebb adatmaszkoló algoritmus. A felhasználók csak akkor férhetnek hozzá az adatokhoz, ha rendelkeznek a visszafejtő kulccsal.
Character Scrambling
Ez a módszer a karakterek sorrendjének véletlenszerű átrendezését jelenti. Ez a folyamat visszafordíthatatlan, így az eredeti adatok nem nyerhetők ki a titkosított adatokból.
Alkalmas az adatok illetéktelen felhasználókkal való megosztására
Nulling out or Deletion
Az érzékeny adatok null értékkel való helyettesítése szintén egy olyan megközelítés, amelyet a vállalkozások előnyben részesíthetnek az adatmaszkolás során. Bár csökkenti a tesztelési eredmények pontosságát, amelyet más megközelítéseknél többnyire fenntartanak, ez egy egyszerűbb megközelítés, ha az üzleti vállalkozások nem maszkolnak modellérvényesítési célok miatt.
Maszkolás ki
A maszkolás ki módszerben az eredeti adatoknak csak egy részét maszkolják. Hasonló a nulling out-hoz, mivel a tesztkörnyezetben nem hatékony. Például az online vásárlás során a hitelkártyaszámnak csak az utolsó 4 számjegyét mutatják meg a vásárlóknak a csalás megelőzése érdekében.
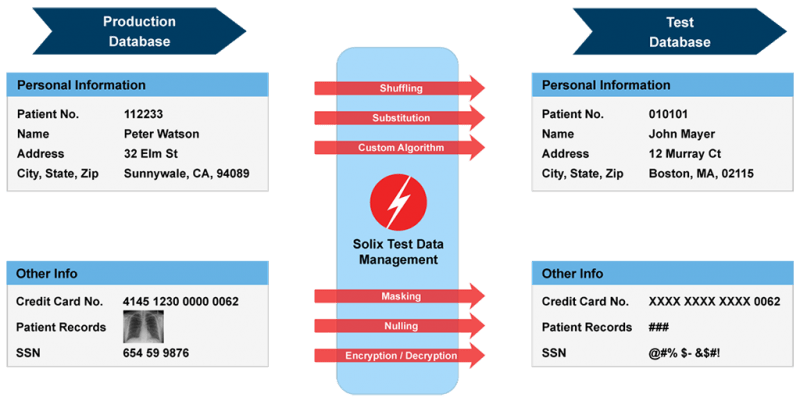
Forrás: Solix Technologies
Miben különbözik az adatmaszkolás a szintetikus adatoktól?

A GDPR-előírásoknak megfelelő tesztadatok létrehozására a szervezeteknek két lehetőségük van: szintetikus adatok generálása vagy az adatok különböző algoritmusokkal történő maszkolása. Bár ez a két tesztelési technika ugyanazt a célt szolgálja, mindegyik módszernek különböző előnyei és kockázatai vannak.
Az adatmaszkírozás a valós adatok másolatának létrehozása, amelyet egy adathalmazon belül bizonyos mezőkben eltakarnak. Azonban még akkor is, ha a szervezet a legösszetettebb és legátfogóbb adatmaszkírozási technikákat alkalmazza, van egy kis esély arra, hogy valaki a maszkolt adatok tendenciái alapján azonosítani tud egyes személyeket. Ezért fennáll a kockázata annak, hogy harmadik felek számára információkat adnak ki.
A másik oldalon a szintetikus adatok olyan adatok, amelyeket mesterségesen hoznak létre, nem pedig tényleges események alapján. Nem tartalmaz valós információkat az egyénekről, hanem azon adatmodell vagy üzenetmodellek alapján jön létre, amelyeket egy vállalkozás használ a termelési rendszereihez. Azokban az esetekben, amikor egy vállalkozás egy teljesen új alkalmazást tesztel, vagy amikor a vállalkozás úgy véli, hogy az adatmaszkolás nem elegendő, a szintetikus adatok használata a megoldás.
Milyen típusú adatok igényelnek adatmaszkolást?
- Személyesen azonosítható információk (PII): Minden olyan adat, amely potenciálisan felhasználható egy adott személy azonosítására. Például teljes név, társadalombiztosítási szám, jogosítványszám és útlevélszám.
- Védett egészségügyi információk (PHI): A PHI magában foglalja a demográfiai adatokat, kórtörténeteket, vizsgálati és laboratóriumi eredményeket, mentális egészségi állapotokat, biztosítási információkat és egyéb olyan adatokat, amelyeket az egészségügyi szakember a megfelelő ellátás azonosítása érdekében gyűjt.
- Fizetőkártya-információk (PCI-DSS): Van egy információbiztonsági szabvány, amelyet a szervezeteknek követniük kell a főbb kártyarendszerek márkás hitelkártyáinak kezelése során.
- Szellemi tulajdon (IP): A szellemi tulajdon olyan szellemi alkotásokra utal, mint a találmányok; irodalmi és művészeti alkotások; formatervezési minták; valamint a kereskedelemben használt szimbólumok, nevek és képek.
Hogyan segíti elő a GDPR az adatok elfedését?
Az adatmaszkírozást a GDPR az egyének adatainak védelmét szolgáló technikaként fogadja el. Itt vannak a kapcsolódó cikkek, amelyekben a GDPR az álnevesítés alkalmazására ösztönzi a vállalkozásokat:
6. cikk (4-e) bek: ” megfelelő biztosítékok megléte, amelyek magukban foglalhatják a titkosítást vagy az álnevesítést.”
25. cikk (1) bekezdés: “(1) Figyelembe véve a technika állását, a megvalósítás költségeit és az adatkezelés jellegét, hatályát, összefüggéseit és céljait, valamint a természetes személyek jogaira és szabadságaira nézve az adatkezelés által jelentett, különböző valószínűségű és súlyosságú kockázatokat, az adatkezelő mind az adatkezelés eszközeinek meghatározásakor, mind magának az adatkezelésnek az időpontjában, megfelelő technikai és szervezési intézkedéseket – például álnevesítés – hajt végre, amelyek célja az adatvédelmi elvek – például az adatok minimalizálása – hatékony végrehajtása és a szükséges biztosítékok beépítése az adatkezelésbe az e rendeletben foglalt követelmények teljesítése és az érintettek jogainak védelme érdekében.”
32. cikk a) pont: “Az adatkezelő és az adatfeldolgozó megfelelő technikai és szervezési intézkedéseket hajt végre a kockázatnak megfelelő biztonsági szint biztosítása érdekében, beleértve többek között adott esetben: a személyes adatok álnevesítését és titkosítását.”
40. cikk (2) bekezdés: “Az adatkezelők vagy adatfeldolgozók kategóriáit képviselő egyesületek és egyéb testületek magatartási kódexeket készíthetnek, illetve módosíthatják vagy bővíthetik ezeket a kódexeket e rendelet alkalmazásának pontosítása céljából, például a következők tekintetében:
- d) a személyes adatok álnevesítése
89. cikk (1) bekezdés: “A közérdekű archiválási célú, tudományos vagy történelmi kutatási célú vagy statisztikai célú adatkezelésre megfelelő garanciákat kell alkalmazni, beleértve az adatminimalizálást és az álnevesítést.”
Milyen példák vannak az adatmaszkolás esettanulmányaira?
Independence Health Group
Az Independence Health Group a vezető egészségbiztosító, amely szolgáltatások széles körét kínálja, beleértve a kereskedelmi, Medicare és Medicaid orvosi fedezetet, a harmadik fél által nyújtott ellátások kezelését, a gyógyszertári ellátások kezelését és a munkavállalói kártérítést. Az Independence Health lehetővé kívánta tenni, hogy az on- és off-shore fejlesztők valós adatok felhasználásával tesztelhessék az alkalmazásokat, azonban a PHI-t és más személyazonosításra alkalmas információkat el kellett rejteniük. Az Informatica Dynamic Data Masking használata mellett döntöttek, hogy valós időben álcázzák a tagok nevét, születési dátumát, társadalombiztosítási számát (SSN) és más érzékeny adatokat, miközben a fejlesztők adathalmazokat hívnak le.
Az Independence Health az adatmaszkoló megoldással jobban meg tudja védeni az ügyfelek érzékeny adatait, ami csökkenti az adatbiztonság megsértésének lehetséges költségeit.
Samsung
A Samsung világszerte mobil és smart TV termékek elemzésén és gyártásán dolgozik. A Samsung Galaxy okostelefonok millióinak termékelemzése során a vállalatnak a helyi szabályozás szabályainak és eljárásainak megfelelően kell védenie a személyes magánadatokat.
A személyes adatok védelmére vonatkozó jogi megfelelés biztosítása érdekében a Samsung partnerséget kötött a Dataguise-szal. A Dataguise Hadoophoz készült eszköze automatikusan felfedezi a fogyasztók adatvédelmi adatait, és titkosítja azokat, mielőtt az adatokat az AWS analitikai eszközeihez migrálná, így csak az arra jogosult felhasználók férhetnek hozzá a valós adatokhoz, és végezhetnek elemzést azokon.
Mik az adatmaszkolás legjobb gyakorlatai?
- Győződjön meg róla, hogy felfedezte az összes érzékeny adatot a vállalati adatbázisban, mielőtt átviszi azokat a tesztelési környezetbe.
- Ismerje meg az érzékeny adatokat, és ennek megfelelően határozza meg a legmegfelelőbb adatmaszkolási technikát.
- Használjon visszafordíthatatlan módszereket, hogy az adatokat ne lehessen visszaalakítani az eredeti verzióra.
Melyek a vezető adatmaszkoló eszközök?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data. Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (SDM-hez)
- Mentis
- Oracle Advanced Security (DDM-hez)
- Oracle’s Data Masking and Subsetting Pack (SDM-hez)
- Privacy Analytics
- Solix Data Masking
Ha más biztonsági megoldások is érdeklik, hogy megvédje vállalati adatait a kiberfenyegetésektől, az alábbiakban egy ajánlott olvasmánylistát talál:
- Endpoint Security: In-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Védekezés az AI-alapú kibertámadások ellen
- Managed Security Services (MSS):
- Security Analytics:
- Deception Technology: In-Depth Guide