Angesichts der zunehmenden Cyber-Bedrohungen und der Umsetzung von Datenschutzgesetzen wie der GDPR in der EU oder der CCPA in den USA müssen Unternehmen sicherstellen, dass private Daten so wenig wie möglich verwendet werden. Datenmaskierung bietet eine Möglichkeit, die Verwendung privater Daten einzuschränken und gleichzeitig Unternehmen die Möglichkeit zu geben, ihre Systeme mit Daten zu testen, die den realen Daten so nahe wie möglich kommen.
Die durchschnittlichen Kosten einer Datenschutzverletzung lagen 2019 bei 4 Millionen US-Dollar. Dies ist ein starker Anreiz für Unternehmen, in Informationssicherheitslösungen wie Datenmaskierung zu investieren, um sensible Daten zu schützen. Datenmaskierung ist eine unverzichtbare Lösung für Unternehmen, die die GDPR einhalten oder realistische Daten in einer Testumgebung verwenden möchten.
- Was ist Datenmaskierung?
- Warum ist Datenmaskierung jetzt wichtig?
- Wie funktioniert die Datenmaskierung?
- Welche Arten der Datenmaskierung gibt es?
- Welche Techniken der Datenmaskierung gibt es?
- Geeignet für das Testdatenmanagement
- Substitution
- Shuffling
- Zahlen- und Datumsvarianz
- Verschlüsselung
- Character Scrambling
- Geeignet für die Weitergabe von Daten an nicht autorisierte Benutzer
- Nullen oder Löschen
- Ausmaskieren
- Wie unterscheidet sich die Datenmaskierung von synthetischen Daten?
- Welche Arten von Daten erfordern eine Datenmaskierung?
- Wie fördert die GDPR die Datenmaskierung?
- Was sind einige Beispiele für Datenmaskierung?
- Independence Health Group
- Samsung
- Was sind die besten Praktiken zur Datenmaskierung?
- Welche sind die führenden Datenmaskierungstools?
Was ist Datenmaskierung?
Datenmaskierung wird auch als Datenverschleierung, Datenanonymisierung oder Pseudonymisierung bezeichnet. Es handelt sich dabei um den Prozess der Ersetzung vertraulicher Daten durch funktionale fiktive Daten wie Zeichen oder andere Daten. Hauptzweck der Datenmaskierung ist der Schutz sensibler, privater Informationen in Situationen, in denen das Unternehmen Daten mit Dritten teilt.
Warum ist Datenmaskierung jetzt wichtig?
Die Zahl der Datenschutzverletzungen nimmt jedes Jahr zu (im Vergleich zur Jahresmitte 2018 ist die Zahl der erfassten Datenschutzverletzungen 2019 um 54 % gestiegen), daher müssen Unternehmen ihre Datensicherheitssysteme verbessern. Der Bedarf an Datenmaskierung nimmt aus folgenden Gründen zu:
- Organisationen benötigen eine Kopie der Produktionsdaten, wenn sie sich entscheiden, diese für nicht-produktive Zwecke wie Anwendungstests oder Business-Analytics-Modellierung zu verwenden.
- Die Datenschutzrichtlinien des Unternehmens sind auch durch Insider bedroht. Daher sollten Unternehmen bei der Freigabe des Zugriffs für Insider-Mitarbeiter immer noch vorsichtig sein. Laut der 2019 Insider Data Breach Survey glauben
- 79 % der CIOs, dass Mitarbeiter in den letzten 12 Monaten versehentlich Unternehmensdaten in Gefahr gebracht haben, während 61 % der Meinung sind, dass Mitarbeiter Unternehmensdaten böswillig in Gefahr gebracht haben.
- 95 % räumen ein, dass Sicherheitsbedrohungen durch Insider eine Gefahr für ihr Unternehmen darstellen
- GDPR und CCPA zwingen Unternehmen dazu, ihre Datenschutzsysteme zu verstärken, da sie sonst hohe Geldstrafen zahlen müssen.
Wie funktioniert die Datenmaskierung?
Datenmaskierung ist ein einfacher Prozess, der jedoch verschiedene Techniken und Arten umfasst. Im Allgemeinen beginnen Organisationen mit der Identifizierung aller sensiblen Daten in ihrem Unternehmen. Anschließend maskieren sie sensible Daten mit Hilfe von Algorithmen und ersetzen sie durch strukturell identische, aber numerisch unterschiedliche Daten. Was meinen wir mit strukturell identisch? In den USA sind Passnummern zum Beispiel 9-stellig, und Personen müssen ihre Passdaten in der Regel an Fluggesellschaften weitergeben. Wenn eine Fluggesellschaft ein Modell erstellt, um das Geschäftsumfeld zu analysieren und zu testen, erstellt sie eine andere 9-stellige Passnummer oder ersetzt einige Ziffern durch Buchstaben.
Hier ist ein Beispiel dafür, wie Datenmaskierung funktioniert:
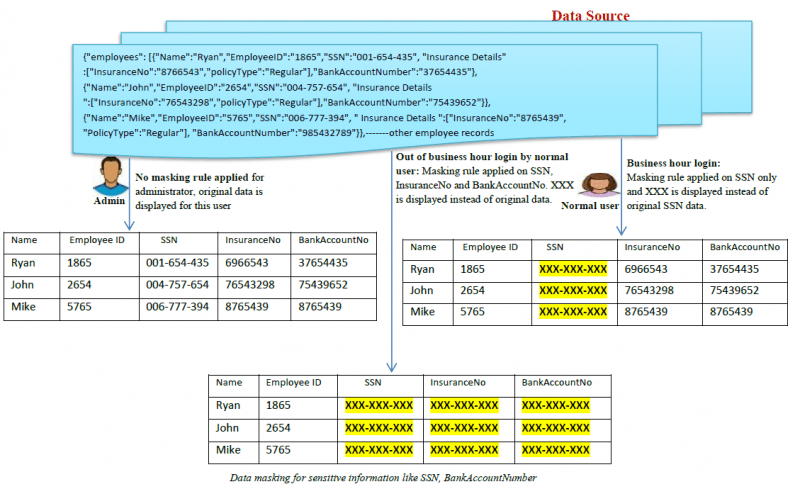
Welche Arten der Datenmaskierung gibt es?
- Statische Datenmaskierung (SDM): Bei SDM werden Daten in der Originaldatenbank maskiert und dann in eine Testumgebung dupliziert, so dass Unternehmen die Testdatenumgebung mit Drittanbietern gemeinsam nutzen können.
- Dynamische Datenmaskierung (DDM): Bei DDM ist keine zweite Datenquelle erforderlich, um die maskierten Daten dynamisch zu speichern. Die ursprünglichen sensiblen Daten verbleiben im Repository und sind für eine
Anwendung zugänglich, wenn sie vom System autorisiert wurde. Die Daten werden niemals unbefugten Benutzern zugänglich gemacht, die Inhalte werden bei Bedarf in Echtzeit umgeschichtet, um die Inhalte zu maskieren. Nur autorisierte Benutzer können die authentischen Daten sehen. Für DDM wird in der Regel ein Reverse Proxy verwendet. Andere dynamische Methoden zur Erreichung von DDM werden im Allgemeinen als „on-the-fly data masking“ bezeichnet.
Welche Techniken der Datenmaskierung gibt es?
Es gibt zahlreiche Datenmaskierungstechniken, die wir je nach Anwendungsfall klassifiziert haben.
Geeignet für das Testdatenmanagement
Substitution
Beim Substitutionsansatz, wie der Name schon sagt, ersetzen die Unternehmen die Originaldaten durch Zufallsdaten aus einer mitgelieferten oder angepassten Lookup-Datei. Dies ist eine wirksame Methode zur Verschleierung von Daten, da die Unternehmen das authentische Aussehen der Daten beibehalten.
Shuffling
Shuffling ist eine weitere gängige Datenmaskierungsmethode. Bei der Shuffling-Methode werden die Originaldaten wie bei der Substitution durch andere, authentisch aussehende Daten ersetzt, aber die Entitäten in derselben Spalte werden zufällig gemischt.
Zahlen- und Datumsvarianz
Bei Finanz- und Datumsdatensätzen ändert die Anwendung derselben Varianz zur Erstellung eines neuen Datensatzes nichts an der Genauigkeit des Datensatzes, während die Daten maskiert werden. Die Verwendung von Varianz zur Erstellung eines neuen Datensatzes wird auch häufig bei der Erzeugung synthetischer Daten verwendet. Wenn Sie den Datenschutz mit dieser Technik schützen wollen, empfehlen wir Ihnen, unseren umfassenden Leitfaden zur Generierung synthetischer Daten zu lesen.
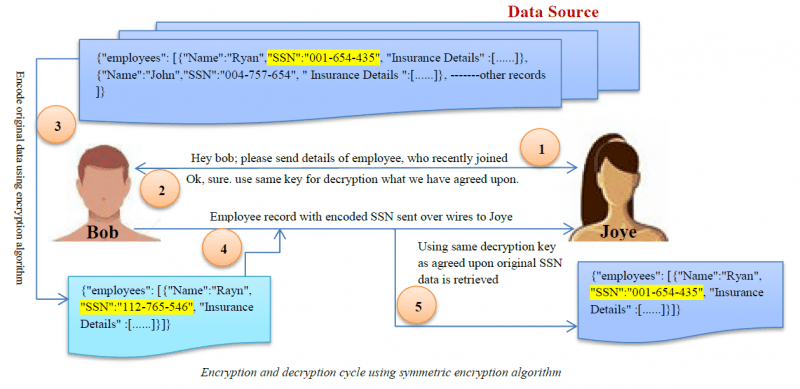
Verschlüsselung
Verschlüsselung ist der komplexeste Algorithmus zur Datenmaskierung. Benutzer können nur dann auf Daten zugreifen, wenn sie den Entschlüsselungsschlüssel besitzen.
Character Scrambling
Bei dieser Methode wird die Reihenfolge der Zeichen nach dem Zufallsprinzip neu angeordnet. Dieser Prozess ist irreversibel, so dass die Originaldaten nicht aus den verschlüsselten Daten gewonnen werden können.
Geeignet für die Weitergabe von Daten an nicht autorisierte Benutzer
Nullen oder Löschen
Das Ersetzen sensibler Daten durch Nullwerte ist ebenfalls ein Ansatz, den Unternehmen bei ihren Bemühungen zur Datenmaskierung vorziehen können. Obwohl dies die Genauigkeit der Testergebnisse verringert, die bei anderen Ansätzen meist beibehalten wird, ist es ein einfacherer Ansatz, wenn Unternehmen aufgrund von Modellvalidierungszwecken nicht maskieren.
Ausmaskieren
Bei der Ausmaskierungsmethode wird nur ein Teil der ursprünglichen Daten maskiert. Es ist ähnlich wie das Nulling out, da es in der Testumgebung nicht wirksam ist. Beim Online-Shopping werden den Kunden beispielsweise nur die letzten 4 Ziffern der Kreditkartennummer angezeigt, um Betrug zu verhindern.
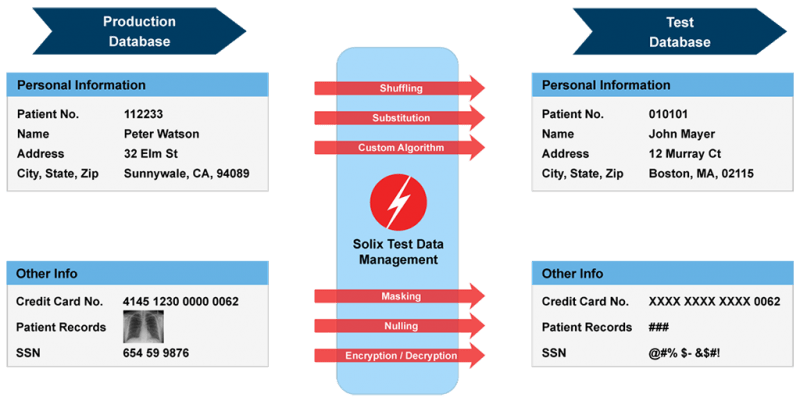
Quelle: Solix Technologies
Wie unterscheidet sich die Datenmaskierung von synthetischen Daten?

Für die Erstellung von Testdaten, die mit den GDPR-Vorschriften konform sind, haben Unternehmen zwei Möglichkeiten: die Generierung synthetischer Daten oder die Maskierung von Daten mit verschiedenen Algorithmen. Obwohl diese beiden Testtechniken dem gleichen Zweck dienen, hat jede Methode unterschiedliche Vorteile und Risiken.
Datenmaskierung ist der Prozess der Erstellung einer Kopie von realen Daten, die in bestimmten Feldern innerhalb eines Datensatzes unkenntlich gemacht werden. Doch selbst wenn die Organisation die komplexesten und umfassendsten Datenmaskierungstechniken anwendet, besteht eine geringe Chance, dass jemand einzelne Personen anhand von Trends in den maskierten Daten identifizieren kann. Daher besteht die Gefahr, dass Informationen an Dritte weitergegeben werden.
Auf der anderen Seite sind synthetische Daten Daten, die künstlich erzeugt werden und nicht auf tatsächlichen Ereignissen beruhen. Sie enthalten keine echten Informationen über Personen, sondern werden auf der Grundlage des Datenmodells oder der Nachrichtenmodelle erstellt, die ein Unternehmen für seine Produktionssysteme verwendet. In Fällen, in denen ein Unternehmen eine völlig neue Anwendung testet oder der Meinung ist, dass seine Datenmaskierung nicht ausreicht, ist die Verwendung synthetischer Daten die Lösung.
Welche Arten von Daten erfordern eine Datenmaskierung?
- Persönlich identifizierbare Informationen (PII): Alle Daten, die potenziell zur Identifizierung einer bestimmten Person verwendet werden können. Zum Beispiel vollständiger Name, Sozialversicherungsnummer, Führerscheinnummer und Reisepassnummer.
- Geschützte Gesundheitsinformationen (PHI): Zu den PHI gehören demografische Informationen, Krankengeschichten, Test- und Laborergebnisse, psychische Erkrankungen, Versicherungsinformationen und andere Daten, die ein Angehöriger der Gesundheitsberufe sammelt, um eine angemessene Versorgung zu gewährleisten.
- Zahlungskarteninformationen (PCI-DSS): Es gibt einen Informationssicherheitsstandard, den Organisationen beim Umgang mit Markenkreditkarten der großen Kartensysteme einhalten müssen.
- Geistiges Eigentum (IP): Geistiges Eigentum bezieht sich auf geistige Schöpfungen wie Erfindungen, literarische und künstlerische Werke, Designs sowie Symbole, Namen und Bilder, die im Handel verwendet werden.
Wie fördert die GDPR die Datenmaskierung?
Datenmaskierung wird von der GDPR als Technik zum Schutz der Daten von Einzelpersonen akzeptiert. Hier sind die zugehörigen Artikel, in denen die GDPR Unternehmen ermutigt, Pseudonymisierung zu verwenden:
Artikel 6 (4-e): „Das Vorhandensein geeigneter Garantien, die Verschlüsselung oder Pseudonymisierung umfassen können.“
Artikel 25 (1): „Unter Berücksichtigung des Stands der Technik, der Implementierungskosten und der Art, des Umfangs, der Umstände und der Zwecke der Verarbeitung sowie der unterschiedlichen Eintrittswahrscheinlichkeit und Schwere der von der Verarbeitung ausgehenden Risiken für die Rechte und Freiheiten natürlicher Personen hat der Verantwortliche sowohl zum Zeitpunkt der Festlegung der Mittel für die Verarbeitung als auch zum Zeitpunkt der Verarbeitung selbst, geeignete technische und organisatorische Maßnahmen, wie z. B. die Pseudonymisierung, zu treffen, die geeignet sind, die Datenschutzgrundsätze, wie z. B. die Datenminimierung, wirksam umzusetzen und die erforderlichen Garantien in die Verarbeitung einzubeziehen, um die Anforderungen dieser Verordnung zu erfüllen und die Rechte der betroffenen Personen zu schützen.“
Artikel 32 (a): „Der für die Verarbeitung Verantwortliche und der Auftragsverarbeiter treffen geeignete technische und organisatorische Maßnahmen, um ein dem Risiko angemessenes Sicherheitsniveau zu gewährleisten, wozu unter anderem gegebenenfalls die Pseudonymisierung und Verschlüsselung personenbezogener Daten gehören.“
Artikel 40 (2): „Verbände und andere Gremien, die Kategorien von für die Verarbeitung Verantwortlichen oder Auftragsverarbeitern vertreten, können Verhaltenskodizes ausarbeiten oder solche Kodizes ändern oder erweitern, um die Anwendung dieser Verordnung zu präzisieren, beispielsweise im Hinblick auf:
- d) die Pseudonymisierung personenbezogener Daten
Artikel 89 (1): „Die Verarbeitung zu im öffentlichen Interesse liegenden Archivzwecken, zu wissenschaftlichen oder historischen Forschungszwecken oder zu statistischen Zwecken unterliegt angemessenen Garantien, einschließlich Datenminimierung und Pseudonymisierung.“
Was sind einige Beispiele für Datenmaskierung?
Independence Health Group
Independence Health Group ist ein führendes Krankenversicherungsunternehmen, das eine breite Palette von Dienstleistungen anbietet, darunter kommerzielle, Medicare- und Medicaid-Krankenversicherungen, Verwaltung von Leistungen Dritter, Verwaltung von Apothekenleistungen und Arbeiterunfallversicherung. Independence Health wollte es Entwicklern im In- und Ausland ermöglichen, Anwendungen anhand echter Daten zu testen, musste aber PHI und andere persönlich identifizierbare Informationen ausblenden. Das Unternehmen entschied sich für Informatica Dynamic Data Masking, um Namen, Geburtsdaten, Sozialversicherungsnummern und andere sensible Daten in Echtzeit zu verschleiern, während Entwickler Datensätze abrufen.
Mit einer Datenmaskierungslösung ist Independence Health in der Lage, sensible Kundendaten besser zu schützen, was die potenziellen Kosten einer Datenschutzverletzung reduziert.
Samsung
Samsung arbeitet weltweit an der Analyse und Herstellung von Mobil- und Smart-TV-Produkten. Bei der Produktanalyse von Millionen von Samsung Galaxy-Smartphones muss das Unternehmen personenbezogene Daten gemäß den Regeln und Verfahren der lokalen Vorschriften schützen.
Um die Einhaltung der gesetzlichen Bestimmungen zum Schutz personenbezogener Daten zu gewährleisten, ist Samsung eine Partnerschaft mit Dataguise eingegangen. Das Dataguise-Tool für Hadoop erkennt automatisch Daten zum Schutz der Privatsphäre von Verbrauchern und verschlüsselt sie, bevor die Daten zu AWS-Analyse-Tools migriert werden, so dass nur autorisierte Benutzer auf Echtdaten zugreifen und Analysen durchführen können.
Was sind die besten Praktiken zur Datenmaskierung?
- Stellen Sie sicher, dass Sie alle sensiblen Daten in der Unternehmensdatenbank entdeckt haben, bevor Sie sie in die Testumgebung übertragen.
- Verstehen Sie Ihre sensiblen Daten und identifizieren Sie entsprechend die am besten geeignete Datenmaskierungstechnik.
- Verwenden Sie irreversible Methoden, damit Ihre Daten nicht in die ursprüngliche Version zurückverwandelt werden können.
Welche sind die führenden Datenmaskierungstools?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (für DDM)
- Informatica Persistent Data Masking (für SDM)
- Mentis
- Oracle Advanced Security (für DDM)
- Oracle’s Data Masking and Subsetting Pack (für SDM)
- Privacy Analytics
- Solix Data Masking
Wenn Sie sich für andere Sicherheitslösungen zum Schutz Ihrer Unternehmensdaten vor Cyber-Bedrohungen interessieren, Nachfolgend finden Sie eine empfohlene Leseliste für Sie:
- Endpoint Security: in-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Verteidigen Sie sich gegen KI-gestützte Cyberangriffe
- Managed Security Services (MSS): Umfassender Leitfaden
- Security Analytics: Der ultimative Leitfaden
- Täuschungstechnologie: Ausführlicher Leitfaden