サイバー脅威の増加や、EUのGDPRや米国のCCPAなどのデータプライバシー法の実施を考えると、企業は個人データをできるだけ使用しないようにする必要があります。 データマスキングは、個人データの使用を制限する方法を提供する一方で、企業が実際のデータに限りなく近いデータでシステムをテストできるようにします。
データ侵害の平均コストは、2019年に400万ドルでした。 このことは、企業が機密データを保護するために、データマスキングを含む情報セキュリティソリューションに投資する強い動機付けとなっています。 データマスキングは、GDPRに準拠したい、またはテスト環境で現実的なデータを使用したい組織にとって必須のソリューションです
- データマスキングとは何ですか?
- なぜ今、データマスキングが重要なのですか?
- データマスキングとはどのように機能しますか?
- データマスキングの種類は何ですか。
- データマスキングの技術にはどのようなものがありますか。 テストデータ管理に最適 Substitution
- Shuffling
- Number and Date Variance
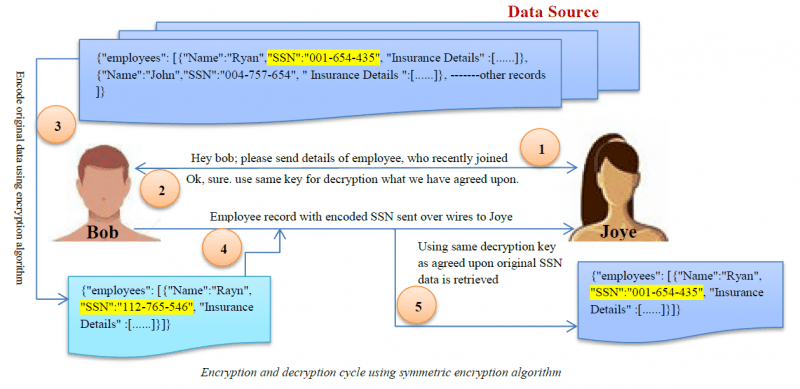
- 暗号化
- Character Scrambling
- Nulling out or Deletion
- マスキング アウト
- データマスキングは合成データとはどう違うのですか。
- どのような種類のデータにデータマスキングが必要なのでしょうか。
- GDPRはどのようにデータマスキングを促進しますか?
- データマスキングの事例にはどのようなものがあるのでしょうか。
- Independence Health Group
- データマスキングのベストプラクティスとは何ですか。
データマスキングとは何ですか?
データマスキングは、データ難読化、データ匿名化、または仮名化とも呼ばれます。 文字などの機能的な架空のデータを用いて、機密データを置き換える処理のことです。
なぜ今、データマスキングが重要なのですか?
データ侵害の件数は年々増加しています(2018年の年央と比較して、2019年の記録された侵害の件数は54%増)そのため、組織はデータセキュリティ体制を向上させる必要があります。 以下の理由により、データマスキングの必要性が高まっています:
- 組織は、アプリケーションテストやビジネス分析のモデリングなどの非生産的な理由でデータを使用することを決めたときに、本番データのコピーを必要とします
- 企業のデータプライバシー方針は、内部者によっても脅かされています。 したがって、組織は、インサイダーの従業員へのアクセスを可能にする間、依然として注意する必要があります。 2019年インサイダーデータブリーチ調査によると、
- CIOの79%は、過去12ヶ月間に従業員が誤って企業データを危険にさらしたと考えており、61%は従業員が悪意を持って企業データを危険にさらしたと考えています。
- 95% が内部からのセキュリティ脅威が組織にとって危険であると認識している
- GDPR と CCPA により、企業はデータ保護システムを強化しなければならず、さもなければ企業は高額な罰金を支払わなければならない
データマスキングとはどのように機能しますか?
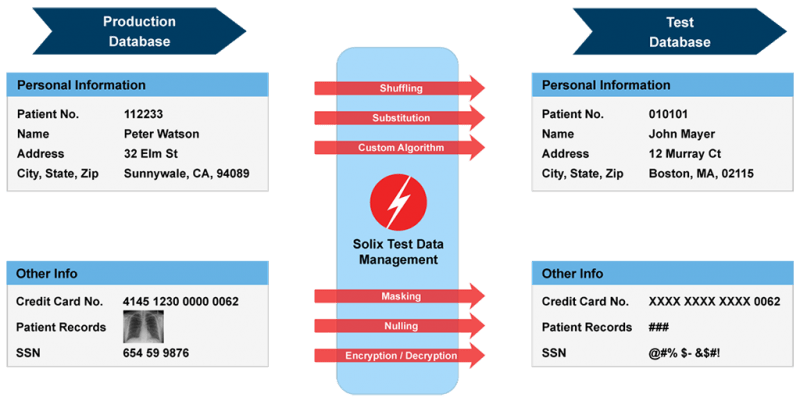
データマスキングのプロセスは単純ですが、さまざまなテクニックやタイプがあります。 一般に、組織は、企業が保有するすべての機密データを特定することから始めます。 次に、アルゴリズムを使用して機密データをマスキングし、構造的には同じだが数値的には異なるデータに置き換えます。 構造的に同じとはどういう意味でしょうか。 例えば、米国ではパスポート番号は9桁で、通常、個人は航空会社とパスポート情報を共有しなければなりません。 航空会社がビジネス環境を分析およびテストするためにモデルを構築する場合、別の 9 桁の長いパスポート ID を作成するか、一部の数字を文字に置き換えます。
ここで、データ マスクの動作の一例を紹介します。 Informatica
データマスキングの種類は何ですか。
- 静的データマスキング(SDM)。 SDM では、データは元のデータベースでマスキングされ、テスト環境に複製されます。 DDMでは、マスキングされたデータを動的に保存するための第2のデータソースは必要ない。 元の機密データはリポジトリに残り、システムによって許可されたときに
アプリケーションにアクセスできます。 データは権限のないユーザーには決して公開されず、コンテンツはオンデマンドでリアルタイムにシャッフルされ、マスクされたコンテンツになります。 許可されたユーザーのみが本物のデータを見ることができる。 DDMの実現には、一般的にリバースプロキシーが使用される。
データマスキングの技術にはどのようなものがありますか。
テストデータ管理に最適
Substitution
代用手法では、その名の通り、企業は元のデータを、供給されたかカスタマイズしたルックアップファイルのランダムなデータで置き換えます。
Shuffling
Shuffling は、もうひとつの一般的なデータマスキング方法です。
Number and Date Variance
金融および日付駆動のデータセットでは、新しいデータセットを作成するために同じ分散を適用しても、データをマスキングしてもデータセットの正確さは変わりません。 分散を使用して新しいデータセットを作成することは、合成データ生成でもよく使用されます。 この手法でデータのプライバシーを保護するつもりなら、合成データ生成の包括的なガイドを読むことをお勧めします。
暗号化
暗号化は、最も複雑なデータマスキングアルゴリズムです。 ユーザーは、復号化キーがある場合にのみデータにアクセスできます。
Character Scrambling
この方法は、文字の順序をランダムに並べ替えるものです。 このプロセスは不可逆的で、スクランブルされたデータから元のデータを得ることはできません。
Nulling out or Deletion
機密データをヌル値に置き換えることは、企業がデータマスキングの取り組みにおいて好むことのできるアプローチでもあります。 他のアプローチではほとんど維持されるテスト結果の精度が低下しますが、ビジネスがモデル検証の目的でマスキングしていない場合は、よりシンプルなアプローチです。
マスキング アウト
マスキング アウト手法では、元のデータの一部のみがマスキングされます。 テスト環境では有効ではないので、ヌルアウトと似ています。 たとえば、オンライン ショッピングでは、詐欺を防ぐために、クレジットカード番号の最後の 4 桁のみが顧客に表示されます。
Source: Solix Technologies
データマスキングは合成データとはどう違うのですか。

GDPR規制に準拠したテストデータを作成するために、組織は合成データの生成または異なるアルゴリズムによるデータのマスキングという2つの選択肢を持っています。 これら 2 つのテスト手法は同じ目的を果たすものですが、それぞれの方法には異なる利点とリスクがあります。
データマスキングは、データセット内の特定のフィールドを隠蔽した現実世界のデータのコピーを作成するプロセスです。 しかし、組織が最も複雑で包括的なデータマスキング技術を適用したとしても、誰かがマスキングされたデータの傾向に基づいて個人を特定できる可能性はわずかにあります。
一方、合成データとは、実際の出来事によって生成されたのではなく、人工的に作られたデータのことです。 個人に関する実際の情報は含まれておらず、ビジネスが生産システムで使用しているデータモデルやメッセージモデルに基づいて作成されます。
どのような種類のデータにデータマスキングが必要なのでしょうか。
- 個人を特定できる情報 (PII)。 特定の個人を識別するために使用される可能性のあるすべてのデータ。 たとえば、フルネーム、社会保障番号、運転免許証番号、パスポート番号などです。
- 保護されるべき医療情報(PHI)。 PHI には、人口統計学的情報、病歴、検査結果、精神状態、保険情報、および医療専門家が適切なケアを特定するために収集するその他のデータが含まれます。
- 支払カード情報(PCI-DSS)。 主要なカードスキームのブランドクレジットカードを扱う際に、組織が従うべき情報セキュリティ基準があります。
- 知的財産 (IP)。
- 知的財産(IP):発明、文学や芸術作品、デザイン、商業で使用される記号、名前、画像など、心の創造物を指します。
GDPRはどのようにデータマスキングを促進しますか?
データマスキングは、GDPRによって個人のデータを保護するための手法として認められています。 以下は、GDPRが企業に対して仮名化の使用を奨励している関連条文です:
第6条(4-e)。 「暗号化または仮名化を含む適切な保護措置の存在」
第25条 (1)。 「管理者は、技術水準、実施コスト、処理の性質、範囲、文脈及び目的、並びに処理によってもたらされる自然人の権利及び自由に対する様々な可能性及び重大性のリスクを考慮して、処理のための手段を決定する時点及び処理自体の時点の双方において、以下のことを行わなければならない。 データ最小化などのデータ保護の原則を効果的に実施し、この規則の要件を満たし、データ主体の権利を保護するために、必要な保護措置を処理に組み込むために設計された、仮名化などの適切な技術的および組織的措置を実施する」
第32条(a)項。 「管理者及び処理者は、リスクに見合ったセキュリティレベルを確保するため、特に適切なものとして、個人データの仮名化及び暗号化を含む適切な技術的及び組織的措置を実施しなければならない」
第40条(2)。 「管理者または処理者のカテゴリーを代表する協会およびその他の団体は、次の事項など、本規則の適用を規定する目的で、行動規範を作成し、または当該規範を修正もしくは拡張することができる:
- (d) 個人データの偽名化
第89条 (1): 「公益のためのアーカイブ目的、科学的もしくは歴史的研究目的、または統計目的のための処理は、データの最小化および仮名化を含む適切な保護措置に従うものとする」
データマスキングの事例にはどのようなものがあるのでしょうか。
Independence Health Group
Independence Health Group は大手医療保険会社で、商業医療保険、Medicare、Medicaid 医療保険、第三者給付管理、薬局給付管理、労災など幅広いサービスを行っています。 Independence Healthは、社内外の開発者が実際のデータを使ってアプリケーションをテストできるようにしたいと考えていましたが、PHIやその他の個人を特定できる情報をマスキングする必要がありました。 データマスキングソリューションにより、Independence Health は顧客の機密データをより確実に保護することができ、データ侵害の潜在的なコストを削減することができました。 何百万ものSamsung Galaxy Smartphoneデバイスの製品分析を行う一方で、同社は現地の規制の規則と手順に従って個人の個人情報を保護しなければなりません。
個人のプライバシーに対する法的コンプライアンスを確保するために、SamsungはDataguiseと提携しています。 DataguiseのHadoop用ツールは、消費者のプライバシーデータを自動的に検出し、データをAWS分析ツールに移行する前に暗号化するため、許可されたユーザーのみが実データにアクセスして分析を実行できます。
データマスキングのベストプラクティスとは何ですか。
- テスト環境に転送する前に、企業のデータベースですべての機密データを検出したことを確認します。
- 機密データを理解し、それに応じて最も適したデータマスキング技術を特定します。
- 不可逆な方法を使用して、データを元のバージョンに変換できないようにします。
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Imperva Camouflage Data Masking (for DDM)
- Informatica Persistent Data Masking (for SDM)
- Mentis
- Oracle Advanced Security (for DDM)
- Oracle Data Masking and Subsetting Pack (for SDM)
- Privacy Analytics
- Solix Data Masking
企業データをサイバー脅威から保護する他のセキュリティソリューションにも興味がありましたら、ぜひご覧ください。 以下は、お勧めの文献リストです。
- Endpoint Security: in-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: AIを活用したサイバー攻撃から身を守る
- マネージド・セキュリティ・サービス(MSS)。 包括的なガイド
- セキュリティ・アナリティクス。 究極のガイド
- Deception Technology:徹底ガイド