Vu l’augmentation des cybermenaces et la mise en œuvre de la législation sur la confidentialité des données comme le GDPR dans l’UE ou le CCPA aux États-Unis, les entreprises doivent s’assurer que les données privées sont utilisées le moins possible. Le masquage des données offre un moyen de limiter l’utilisation des données privées tout en permettant aux entreprises de tester leurs systèmes avec des données aussi proches que possible des données réelles.
Le coût moyen d’une violation de données était de 4 millions de dollars en 2019. Cela incite fortement les entreprises à investir dans des solutions de sécurité de l’information, notamment le masquage de données, pour protéger les données sensibles. Le masquage des données est une solution incontournable pour les organisations qui souhaitent se conformer au GDPR ou utiliser des données réalistes dans un environnement de test.
- Qu’est-ce que le masquage des données ?
- Pourquoi le masquage des données est-il important maintenant ?
- Comment fonctionne le masquage des données ?
- Quels sont les types de masquage de données ?
- Quelles sont les techniques de masquage des données ?
- Convient à la gestion des données de test
- Substitution
- Mélange
- Variance du nombre et de la date
- Cryptage
- Brouillage de caractères
- Convient pour le partage de données avec des utilisateurs non autorisés
- Nulling out ou Deletion
- Masking out
- En quoi le masquage des données est-il différent des données synthétiques ?
- Quels types de données nécessitent un masquage des données ?
- Comment le GDPR favorise-t-il le masquage des données ?
- Quels sont des exemples de masquage de données ?
- Independence Health Group
- Samsung
- Quelles sont les meilleures pratiques de masquage des données ?
- Quels sont les principaux outils de masquage de données ?
Qu’est-ce que le masquage des données ?
Le masquage des données est également appelé obfuscation des données, anonymisation des données ou pseudonymisation. Il s’agit du processus de remplacement des données confidentielles par des données fictives fonctionnelles telles que des caractères ou d’autres données. L’objectif principal du masquage des données est de protéger les informations sensibles et privées dans les situations où l’entreprise partage des données avec des tiers.
Pourquoi le masquage des données est-il important maintenant ?
Le nombre de violations de données augmente chaque année (Par rapport au milieu de l’année 2018, le nombre de violations enregistrées a augmenté de 54% en 2019).Par conséquent, les organisations doivent améliorer leurs systèmes de sécurité des données. Le besoin de masquage des données augmente pour les raisons suivantes :
- Les organisations ont besoin d’une copie des données de production lorsqu’elles décident de les utiliser pour des raisons de non-production telles que les tests d’applications ou la modélisation analytique d’entreprise.
- La politique de confidentialité des données de votre entreprise est également menacée par les initiés. Par conséquent, les organisations doivent toujours être prudentes tout en permettant l’accès aux employés initiés. Selon l’enquête 2019 sur les violations de données par des initiés,
- 79 % des DSI pensent que des employés ont mis les données de l’entreprise en danger par accident au cours des 12 derniers mois, tandis que 61 % pensent que des employés ont mis les données de l’entreprise en danger par malveillance.
- 95% reconnaissent que les menaces de sécurité internes sont un danger pour leur organisation
- Le GDPR et le CCPA obligent les entreprises à renforcer leurs systèmes de protection des données sinon les organisations doivent payer de lourdes amendes.
Comment fonctionne le masquage des données ?
Le processus de masquage des données est simple, pourtant, il a différentes techniques et types. En général, les organisations commencent par identifier toutes les données sensibles que votre entreprise détient. Ensuite, elles utilisent des algorithmes pour masquer les données sensibles et les remplacer par des données structurellement identiques mais numériquement différentes. Qu’entend-on par structurellement identique ? Par exemple, les numéros de passeport comportent 9 chiffres aux États-Unis et les personnes doivent généralement communiquer les informations relatives à leur passeport aux compagnies aériennes. Lorsqu’une compagnie aérienne construit un modèle pour analyser et tester l’environnement commercial, elle crée un identifiant de passeport différent, long de 9 chiffres, ou remplace certains chiffres par des caractères.
Voici un exemple du fonctionnement du masquage des données :
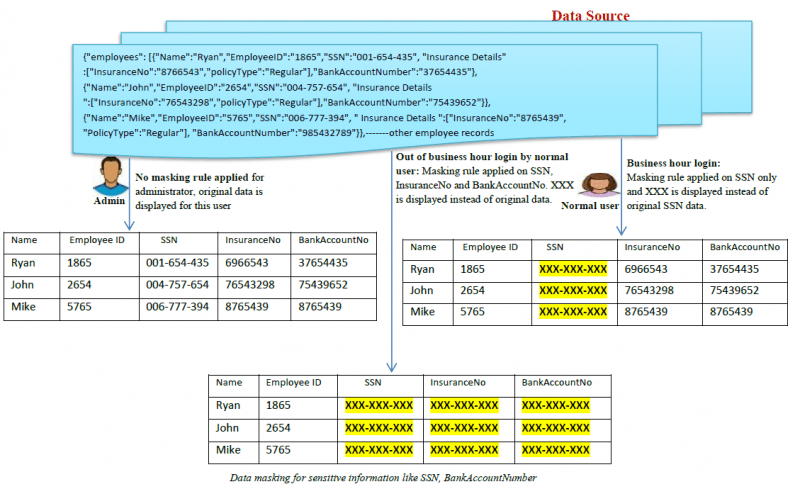
Quels sont les types de masquage de données ?
- Masquage statique des données (SDM) : Dans le SDM, les données sont masquées dans la base de données originale puis dupliquées dans un environnement de test afin que les entreprises puissent partager l’environnement de données de test avec des fournisseurs tiers.
- Masquage dynamique des données (DDM) : Dans le DDM, il n’est pas nécessaire de disposer d’une deuxième source de données pour stocker les données masquées de manière dynamique. Les données sensibles originales restent dans le référentiel et sont accessibles à une
application lorsqu’elle est autorisée par le système. Les données ne sont jamais exposées aux utilisateurs non autorisés, les contenus sont mélangés en temps réel à la demande pour rendre les contenus masqués. Seuls les utilisateurs autorisés sont en mesure de voir les données authentiques. Un reverse proxy est généralement utilisé pour réaliser le DDM. D’autres méthodes dynamiques pour réaliser le DDM sont généralement appelées masquage des données à la volée.
Quelles sont les techniques de masquage des données ?
Il existe de nombreuses techniques de masquage des données et nous les avons classées en fonction de leur cas d’utilisation.
Convient à la gestion des données de test
Substitution
Dans l’approche de substitution, comme son nom l’indique, les entreprises remplacent les données originales par des données aléatoires provenant d’un fichier de consultation fourni ou personnalisé. C’est un moyen efficace de déguiser les données puisque les entreprises préservent l’aspect authentique des données.
Mélange
Le mélange est une autre méthode courante de masquage des données. Dans la méthode de brassage, tout comme la substitution, les entreprises remplacent les données originales par une autre donnée d’apparence authentique, mais elles brassent les entités dans la même colonne de façon aléatoire.
Variance du nombre et de la date
Pour les ensembles de données financières et axées sur la date, appliquer la même variance pour créer un nouvel ensemble de données ne change pas la précision de l’ensemble de données tout en masquant les données. L’utilisation de la variance pour créer un nouvel ensemble de données est également couramment utilisée dans la génération de données synthétiques. Si vous envisagez de protéger la confidentialité des données avec cette technique, nous vous recommandons de lire notre guide complet sur la génération de données synthétiques.
Cryptage
Le cryptage est l’algorithme de masquage des données le plus complexe. Les utilisateurs ne peuvent accéder aux données que s’ils possèdent la clé de déchiffrement.
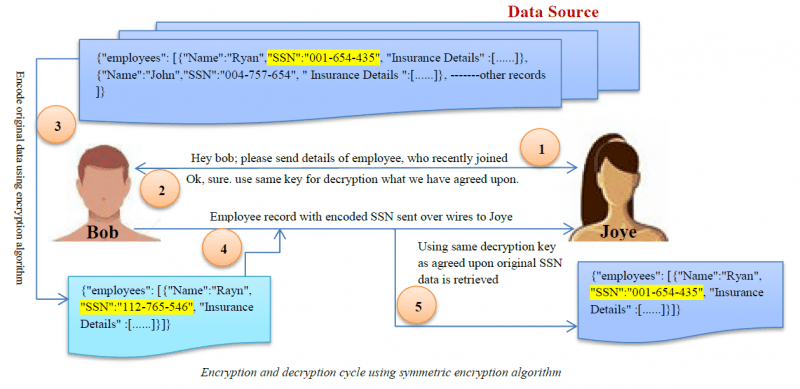
Brouillage de caractères
Cette méthode consiste à réorganiser de manière aléatoire l’ordre des caractères. Ce processus est irréversible, de sorte que les données d’origine ne peuvent pas être obtenues à partir des données brouillées.
Convient pour le partage de données avec des utilisateurs non autorisés
Nulling out ou Deletion
Remplacer les données sensibles par une valeur nulle est également une approche que les entreprises peuvent préférer dans leurs efforts de masquage des données. Bien qu’elle réduise la précision des résultats de test qui sont principalement maintenus dans d’autres approches, c’est une approche plus simple lorsque les entreprises ne masquent pas en raison de la validation du modèle.
Masking out
Dans la méthode de masquage, seule une partie des données originales est masquée. Elle est similaire au nulling out puisqu’elle n’est pas efficace dans l’environnement de test. Par exemple, dans les achats en ligne, seuls les 4 derniers chiffres du numéro de carte de crédit sont montrés aux clients pour éviter la fraude.
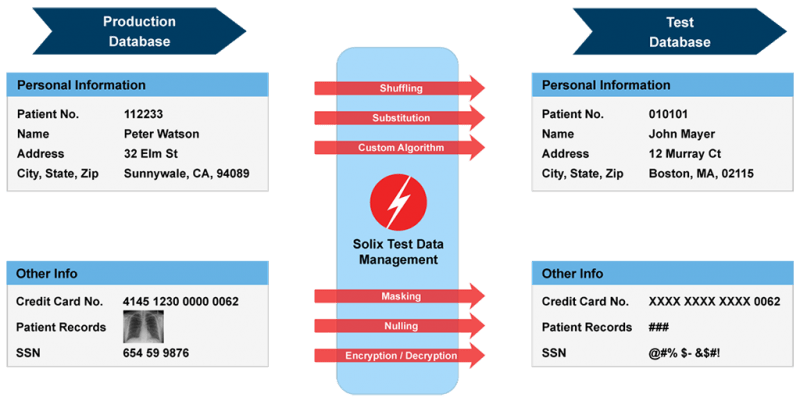
Source : Solix Technologies
En quoi le masquage des données est-il différent des données synthétiques ?

Pour créer des données de test conformes à la réglementation GDPR, les organisations ont deux options : générer des données synthétiques ou masquer les données avec différents algorithmes. Bien que ces deux techniques de test servent au même objectif, chaque méthode présente des avantages et des risques différents.
Le masquage des données est le processus de création d’une copie des données du monde réel qui est masquée dans des champs spécifiques au sein d’un ensemble de données. Cependant, même si l’organisation applique les techniques de masquage de données les plus complexes et les plus complètes, il y a une légère chance que quelqu’un puisse identifier des personnes individuelles en se basant sur les tendances des données masquées. Il y a donc un risque de divulguer des informations à des tiers.
De l’autre côté, les données synthétiques sont des données créées artificiellement plutôt que d’être générées par des événements réels. Elles ne contiennent pas d’informations réelles sur les individus, elles sont créées sur la base du modèle de données ou des modèles de messages qu’une entreprise utilise pour ses systèmes de production. Dans les cas où une entreprise teste une toute nouvelle application ou que l’entreprise estime que son masquage des données n’est pas suffisant, l’utilisation de données synthétiques est la solution.
Quels types de données nécessitent un masquage des données ?
- Informations personnellement identifiables (PII) : Toute donnée qui pourrait potentiellement être utilisée pour identifier une personne en particulier. Par exemple, le nom complet, le numéro de sécurité sociale, le numéro de permis de conduire et le numéro de passeport.
- Informations de santé protégées (PHI) : Les PHI comprennent les informations démographiques, les antécédents médicaux, les résultats de tests et de laboratoires, les conditions de santé mentale, les informations d’assurance et d’autres données qu’un professionnel de la santé recueille pour identifier les soins appropriés.
- Informations sur les cartes de paiement (PCI-DSS) : Il existe une norme de sécurité de l’information que les organisations doivent suivre lors du traitement des cartes de crédit de marque des principaux systèmes de cartes.
- Propriété intellectuelle (PI) : La PI fait référence aux créations de l’esprit, telles que les inventions ; les œuvres littéraires et artistiques ; les dessins et modèles ; et les symboles, noms et images utilisés dans le commerce.
Comment le GDPR favorise-t-il le masquage des données ?
Le masquage des données est accepté comme une technique de protection des données des individus par le GDPR. Voici les articles connexes où le GDPR encourage les entreprises à utiliser la pseudonymisation:
Article 6 (4-e) : » l’existence de garanties appropriées, qui peuvent inclure le cryptage ou la pseudonymisation. »
Article 25 (1) : » Compte tenu de l’état de l’art, du coût de mise en œuvre et de la nature, de la portée, du contexte et des finalités du traitement, ainsi que des risques de probabilité et de gravité variables pour les droits et libertés des personnes physiques que présente le traitement, le responsable du traitement doit, tant au moment de la détermination des moyens de traitement qu’au moment du traitement lui-même, met en œuvre les mesures techniques et organisationnelles appropriées, telles que la pseudonymisation, qui visent à mettre en œuvre de manière efficace les principes de protection des données, tels que la minimisation des données, et à intégrer les garanties nécessaires dans le traitement afin de satisfaire aux exigences du présent règlement et de protéger les droits des personnes concernées. »
Article 32 (a) : « Le responsable du traitement et le sous-traitant mettent en œuvre les mesures techniques et organisationnelles appropriées pour assurer un niveau de sécurité adapté au risque, y compris notamment, le cas échéant : la pseudonymisation et le cryptage des données à caractère personnel. »
Article 40 (2) : « Les associations et autres organismes représentant des catégories de responsables du traitement ou de sous-traitants peuvent élaborer des codes de conduite, ou modifier ou étendre ces codes, dans le but de préciser l’application du présent règlement, par exemple en ce qui concerne :
- d) la pseudonymisation des données à caractère personnel
Article 89 (1) : « Le traitement à des fins d’archivage dans l’intérêt public, à des fins de recherche scientifique ou historique ou à des fins statistiques, est soumis à des garanties appropriées, notamment la minimisation des données et la pseudonymisation. »
Quels sont des exemples de masquage de données ?
Independence Health Group
Independence Health Group est la principale compagnie d’assurance santé qui offre une large gamme de services, notamment une couverture médicale commerciale, Medicare et Medicaid, l’administration des prestations de tiers, la gestion des prestations pharmaceutiques et l’indemnisation des travailleurs. Independence Health souhaitait permettre aux développeurs sur place et à l’étranger de tester des applications à l’aide de données réelles, mais il leur fallait masquer les informations personnelles et autres données d’identification. Ils ont décidé d’utiliser Informatica Dynamic Data Masking pour déguiser les noms des membres, les dates de naissance, les numéros de sécurité sociale (SSN) et d’autres données sensibles en temps réel lorsque les développeurs tirent des ensembles de données.
Avec une solution de masquage des données, Independence Health est en mesure de mieux protéger les données sensibles des clients, ce qui réduit le coût potentiel d’une violation de données.
Samsung
Samsung travaille à l’analyse et à la production de produits mobiles et de téléviseurs intelligents dans le monde entier. Tout en effectuant des analyses de produits sur des millions d’appareils Samsung Galaxy Smartphone, l’entreprise doit protéger les informations privées personnelles conformément aux règles et procédures de la réglementation locale.
Pour assurer la conformité légale à la vie privée, Samsung a établi un partenariat avec Dataguise. L’outil de Dataguise pour Hadoop découvre automatiquement les données de confidentialité des consommateurs et les crypte avant de migrer les données vers les outils d’analyse AWS afin que seuls les utilisateurs autorisés puissent accéder aux données réelles et les analyser.
Quelles sont les meilleures pratiques de masquage des données ?
- Assurez-vous de découvrir toutes les données sensibles dans la base de données de l’entreprise avant de la transférer dans l’environnement de test.
- Comprenez vos données sensibles et identifiez la technique de masquage de données la plus appropriée en conséquence.
- Utilisez des méthodes irréversibles afin que vos données ne puissent pas être retransformées en version originale.
Quels sont les principaux outils de masquage de données ?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data. Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (pour DDM)
- Informatica Persistent Data Masking (pour SDM)
- Mentis
- Oracle Advanced Security (pour DDM)
- Oracle’s Data Masking and Subsetting Pack (pour SDM)
- Privacy Analytics
- Solix Data Masking
.
Si vous êtes intéressé par d’autres solutions de sécurité pour protéger les données de votre entreprise contre les cybermenaces, vous trouverez ci-dessous une liste de lectures recommandées :
- Sécurité des points d’extrémité : guide approfondi
- Le guide ultime du renseignement sur les cybermenaces (CTI)
- Sécurité IA : Se défendre contre les cyberattaques alimentées par l’IA
- Services de sécurité gérés (MSS) : Guide complet
- Les analyses de sécurité : Le guide ultime
- La technologie de déception : guide approfondi
.