Yritysten on varmistettava, että yksityisiä tietoja käytetään mahdollisimman vähän, kun otetaan huomioon lisääntyvät kyberuhat ja tietosuojaa koskevan lainsäädännön, kuten EU:n GDPR:n tai Yhdysvaltojen CCPA:n, täytäntöönpano. Tietojen peittäminen tarjoaa keinon rajoittaa yksityisten tietojen käyttöä ja antaa samalla yrityksille mahdollisuuden testata järjestelmiään tiedoilla, jotka ovat mahdollisimman lähellä todellisia tietoja.
Tietomurron keskimääräiset kustannukset olivat 4 miljoonaa dollaria vuonna 2019. Tämä luo yrityksille vahvan kannustimen investoida tietoturvaratkaisuihin, kuten tietojen peittämiseen arkaluonteisten tietojen suojaamiseksi. Tietojen peittäminen on välttämätön ratkaisu organisaatioille, jotka haluavat noudattaa GDPR-asetusta tai käyttää todellisia tietoja testausympäristössä.
- Mitä on tietojen peittäminen?
- Miksi tietojen peittäminen on nyt tärkeää?
- Miten tietojen peittäminen toimii?
- Millaisia tietojen peittämisen tyyppejä on?
- Mitkä ovat tiedon peittämisen tekniikat?
- Soveltuu testidatan hallintaan
- Substituutio
- Shuffling
- Luku- ja päivämäärävariaatio
- Kryptaus
- Character Scrambling
- Soveltuu tietojen jakamiseen luvattomille käyttäjille
- Tyhjentäminen tai poistaminen
- Masking out
- Miten tietojen peittäminen eroaa synteettisistä tiedoista?
- Minkä tyyppiset tiedot vaativat tietojen peittämistä?
- Miten GDPR edistää tietojen peittämistä?
- Millaisia esimerkkitapauksia on tietojen peittämisestä?
- Independence Health Group
- Samsung
- Mitkä ovat tietojen peittämisen parhaat käytännöt?
- Mitä johtavia datan peittämistyökaluja on olemassa?
Mitä on tietojen peittäminen?
Datan peittämisestä käytetään myös nimityksiä tietojen hämärtäminen, tietojen anonymisointi tai pseudonymisointi. Se on prosessi, jossa luottamukselliset tiedot korvataan käyttämällä toiminnallisia fiktiivisiä tietoja, kuten merkkejä tai muita tietoja. Tietojen peittämisen päätarkoitus on suojata arkaluonteisia, yksityisiä tietoja tilanteissa, joissa yritys jakaa tietoja kolmansien osapuolten kanssa.
Miksi tietojen peittäminen on nyt tärkeää?
Tietomurtojen määrä kasvaa joka vuosi (Vuoden 2018 puoliväliin verrattuna kirjattujen tietomurtojen määrä kasvoi 54 % vuonna 2019) Siksi organisaatioiden on parannettava tietoturvajärjestelmiään. Tietojen peittämisen tarve kasvaa seuraavista syistä:
- Organisaatiot tarvitsevat kopion tuotantotiedoista, kun ne päättävät käyttää niitä muihin kuin tuotantoon liittyviin tarkoituksiin, kuten sovellusten testaamiseen tai liiketoiminta-analytiikan mallintamiseen.
- Yrityksen tietosuojaa uhkaavat myös sisäpiiriläiset. Siksi organisaatioiden on silti oltava varovaisia, kun ne sallivat pääsyn sisäpiirin työntekijöille. 2019 Insider Data Breach -tutkimuksen mukaan
- 79 % CIO:ista uskoo, että työntekijät ovat vaarantaneet yrityksen tietoja vahingossa viimeisten 12 kuukauden aikana, kun taas 61 % uskoo, että työntekijät ovat vaarantaneet yrityksen tietoja ilkivaltaisesti.
- 95 % myöntää, että sisäpiirin tietoturvauhat ovat vaaraksi heidän organisaatiolleen
- GDPR ja CCPA pakottavat yritykset vahvistamaan tietosuojajärjestelmiään, muutoin organisaatiot joutuvat maksamaan mojovat sakot.
Miten tietojen peittäminen toimii?
Datan peittämisprosessi on yksinkertainen, mutta siinä on kuitenkin erilaisia tekniikoita ja tyyppejä. Yleensä organisaatiot aloittavat tunnistamalla kaikki yrityksesi hallussa olevat arkaluonteiset tiedot. Sitten ne käyttävät algoritmeja arkaluonteisten tietojen peittämiseen ja korvaavat ne rakenteeltaan samanlaisilla mutta numeerisesti erilaisilla tiedoilla. Mitä tarkoitamme rakenteellisesti identtisillä tiedoilla? Esimerkiksi Yhdysvalloissa passin numero on yhdeksän numeroa, ja yksityishenkilöt joutuvat yleensä jakamaan passitietonsa lentoyhtiöiden kanssa. Kun lentoyhtiö rakentaa mallin analysoidakseen ja testatakseen liiketoimintaympäristöä, se luo erilaisen yhdeksän numeron pituisen passitunnuksen tai korvaa joitakin numeroita merkeillä.
Tässä on esimerkki siitä, miten tietojen peittäminen toimii:
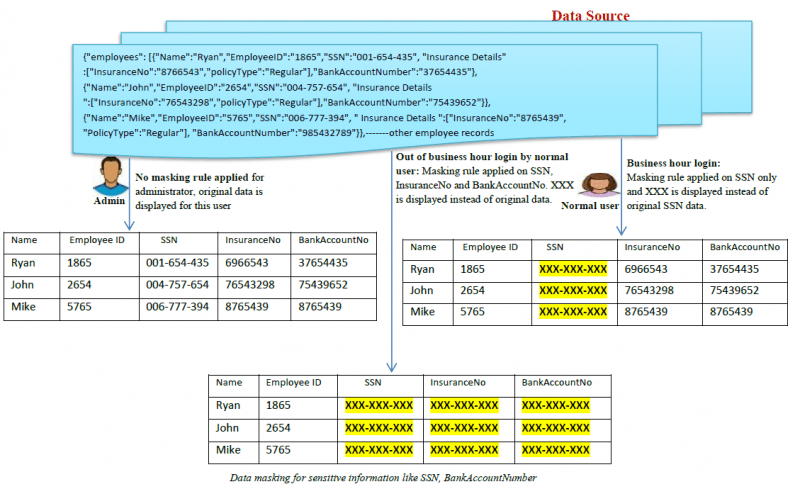
Millaisia tietojen peittämisen tyyppejä on?
- Staattinen tietojen peittäminen (SDM):
- Dynaaminen tietojen peittäminen (DDM): SDM:ssä tiedot peitetään alkuperäisessä tietokannassa, minkä jälkeen ne kopioidaan testiympäristöön, jotta yritykset voivat jakaa testidataympäristön kolmannen osapuolen toimittajien kanssa.
- Dynaaminen tietojen peittäminen (DDM): DDM: DDM:ssä ei tarvita toista tietolähdettä naamioidun tiedon dynaamiseksi tallentamiseksi. Alkuperäiset arkaluonteiset tiedot pysyvät tietovarastossa ja ovat
sovelluksen käytettävissä, kun järjestelmä antaa siihen luvan. Tietoja ei koskaan altisteta luvattomille käyttäjille, vaan sisältö sekoitetaan reaaliaikaisesti pyydettäessä, jotta sisältö saadaan naamioitua. Ainoastaan valtuutetut käyttäjät näkevät aitoja tietoja. DDM:n toteuttamiseen käytetään yleensä käänteistä välityspalvelinta. Muita dynaamisia menetelmiä DDM:n aikaansaamiseksi kutsutaan yleensä on-the-fly-tiedon peittämiseksi.
Mitkä ovat tiedon peittämisen tekniikat?
Datan peittämistekniikoita on lukuisia, ja luokittelimme ne käyttötilanteen mukaan.
Soveltuu testidatan hallintaan
Substituutio
Substituutiomenetelmässä nimensä mukaisesti yritykset korvaavat alkuperäiset tiedot satunnaisilla tiedoilla mukana toimitetusta tai räätälöidystä hakutiedostosta. Tämä on tehokas tapa naamioida tietoja, koska yritykset säilyttävät tietojen aidon ulkoasun.
Shuffling
Shuffling on toinen yleinen tietojen naamiointimenetelmä. Shuffling-menetelmässä yritykset korvaavat korvaamisen tavoin alkuperäisen datan toisella aidon näköisellä datalla, mutta ne sekoittavat samassa sarakkeessa olevia yksiköitä satunnaisesti.
Luku- ja päivämäärävariaatio
Taloudellisissa ja päivämäärään perustuvissa tietokokonaisuuksissa saman varianssin käyttäminen uuden tietokokonaisuuden luomiseksi ei muuta tietokokonaisuuden tarkkuutta dataa naamioidessa. Varianssin käyttämistä uuden tietokokonaisuuden luomiseen käytetään yleisesti myös synteettisen datan luomisessa. Jos aiot suojata tietojen yksityisyyttä tällä tekniikalla, suosittelemme lukemaan kattavan oppaamme synteettisen datan luomisesta.
Kryptaus
Kryptaus on monimutkaisin datan peittoalgoritmi. Käyttäjät pääsevät käsiksi tietoihin vain, jos heillä on salauksen purkuavain.
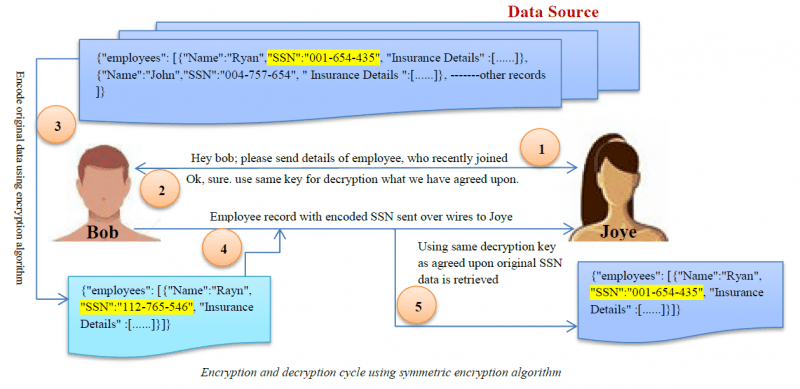
Character Scrambling
Tässä menetelmässä merkkien järjestys järjestetään satunnaisesti uudelleen. Tämä prosessi on peruuttamaton, joten alkuperäisiä tietoja ei voida saada salatusta datasta.
Soveltuu tietojen jakamiseen luvattomille käyttäjille
Tyhjentäminen tai poistaminen
Arkaluonteisten tietojen korvaaminen nolla-arvolla on myös lähestymistapa, jota yritykset voivat suosia tietojen peittämistoimissaan. Vaikka se vähentää testaustulosten tarkkuutta, joka useimmiten säilyy muissa lähestymistavoissa, se on yksinkertaisempi lähestymistapa, kun yritykset eivät peitä tietoja mallin validointitarkoituksiin.
Masking out
Masking out -menetelmässä vain osa alkuperäisistä tiedoista peitetään. Se on samanlainen kuin nulling out, koska se ei ole tehokas testiympäristössä. Esimerkiksi verkkokaupassa asiakkaille näytetään vain luottokortin numeron neljä viimeistä numeroa petosten estämiseksi.
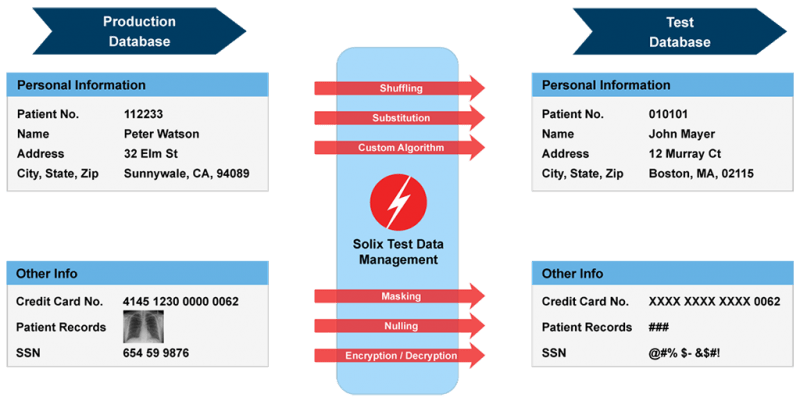
Lähde: Solix Technologies
Miten tietojen peittäminen eroaa synteettisistä tiedoista?

GDPR-säädösten mukaisten testidatan luomiseksi organisaatioilla on kaksi vaihtoehtoa: synteettisen datan luominen tai datan peittäminen eri algoritmeilla. Vaikka nämä kaksi testaustekniikkaa palvelevat samaa tarkoitusta, kummallakin menetelmällä on erilaiset hyödyt ja riskit.
Datan peittäminen on prosessi, jossa luodaan kopio reaalimaailman tiedoista, jotka on peitetty tietyissä kentissä tietokokonaisuuden sisällä. Vaikka organisaatio soveltaisi kaikkein monimutkaisimpia ja kattavimpia datan peittämistekniikoita, on kuitenkin pieni mahdollisuus, että joku voi tunnistaa yksittäisiä henkilöitä peitetyn datan trendien perusteella. Näin ollen on olemassa riski tietojen luovuttamisesta kolmansille osapuolille.
Toisaalta synteettinen data on dataa, joka on keinotekoisesti luotu sen sijaan, että se olisi syntynyt todellisten tapahtumien perusteella. Se ei sisällä todellista tietoa yksilöistä, vaan se luodaan sen tietomallin tai viestimallien perusteella, joita yritys käyttää tuotantojärjestelmissään. Synteettisen datan käyttö on ratkaisu tapauksissa, joissa yritys testaa kokonaan uutta sovellusta tai yritys uskoo, että sen käyttämä tietojen peittäminen ei ole riittävää.
Minkä tyyppiset tiedot vaativat tietojen peittämistä?
- Henkilökohtaisesti tunnistettavat tiedot (PII): Kaikki tiedot, joita voidaan mahdollisesti käyttää tietyn henkilön tunnistamiseen. Esimerkiksi koko nimi, sosiaaliturvatunnus, ajokortin numero ja passin numero.
- Suojatut terveystiedot (PHI): PHI sisältää demografisia tietoja, sairaushistoriaa, testi- ja laboratoriotuloksia, mielenterveysolosuhteita, vakuutustietoja ja muita tietoja, joita terveydenhuollon ammattilainen kerää asianmukaisen hoidon tunnistamiseksi.
- Maksukorttitiedot (PCI-DSS): On olemassa tietoturvastandardi, jota organisaatioiden on noudatettava käsitellessään suurimpien korttijärjestelmien merkkiluottokortteja.
- Immateriaalioikeudet (IP): Immateriaalioikeuksilla tarkoitetaan mielen luomuksia, kuten keksintöjä, kirjallisia ja taiteellisia teoksia, malleja sekä kaupassa käytettäviä symboleja, nimiä ja kuvia.
Miten GDPR edistää tietojen peittämistä?
Datan peittäminen hyväksytään GDPR:ssä tekniikaksi yksilöiden tietojen suojaamiseksi. Tässä ovat asiaan liittyvät artikkelit, joissa GDPR kannustaa yrityksiä käyttämään pseudonymisointia:
6 artiklan 4-e kohta: ” asianmukaisten suojatoimien olemassaolo, joihin voi kuulua salaus tai pseudonymisointi.”
25 artiklan 1 kohta: ”Ottaen huomioon tekniikan tason, toteutuskustannukset ja käsittelyn luonteen, laajuuden, asiayhteyden ja tarkoitukset sekä käsittelystä luonnollisten henkilöiden oikeuksiin ja vapauksiin kohdistuvat riskit, joiden todennäköisyys ja vakavuus vaihtelevat, rekisterinpitäjän on sekä käsittelykeinoja määritettäessä että itse käsittelyn aikana, toteutettava asianmukaiset tekniset ja organisatoriset toimenpiteet, kuten pseudonymisointi, joiden tarkoituksena on panna tehokkaasti täytäntöön tietosuojaperiaatteet, kuten tietojen minimointi, ja sisällyttää tarvittavat takeet käsittelyyn tämän asetuksen vaatimusten täyttämiseksi ja rekisteröityjen oikeuksien suojaamiseksi.”
32 artiklan a alakohta: ”Rekisterinpitäjän ja henkilötietojen käsittelijän on toteutettava asianmukaiset tekniset ja organisatoriset toimenpiteet riskiin nähden asianmukaisen turvallisuustason varmistamiseksi, mukaan lukien muun muassa tarvittaessa: henkilötietojen pseudonymisointi ja salaus.”
40 artiklan 2 kohta: ”Yhdistykset ja muut rekisterinpitäjien tai henkilötietojen käsittelijöiden ryhmiä edustavat elimet voivat laatia käytännesääntöjä tai muuttaa tai laajentaa tällaisia sääntöjä tämän asetuksen soveltamisen täsmentämiseksi, esimerkiksi seuraavien seikkojen osalta:
- d) henkilötietojen pseudonymisointi
89 artiklan 1 kohta: ”Yleisen edun mukaisia arkistointitarkoituksia, tieteellisiä tai historiallisia tutkimustarkoituksia tai tilastollisia tarkoituksia varten tapahtuvaan käsittelyyn on sovellettava asianmukaisia suojatoimia, mukaan lukien tietojen minimointi ja pseudonymisointi.”
Millaisia esimerkkitapauksia on tietojen peittämisestä?
Independence Health Group
Independence Health Group on johtava sairausvakuutusyhtiö, joka tarjoaa monenlaisia palveluita, mukaan lukien kaupallinen, Medicare- ja Medicaid-sairaanhoitovakuutusturva, etuuksien hallinnointi kolmannelle osapuolelle (third-party benefits administration), apteekkietuuksien hallinnointi (pharmacy benefits management) ja työelämän korvaukset. Independence Health halusi antaa sisäisten ja ulkoisten kehittäjien testata sovelluksia oikeilla tiedoilla, mutta PHI-tiedot ja muut henkilökohtaisesti tunnistettavat tiedot piti kuitenkin peittää. He päättivät käyttää Informatica Dynamic Data Masking -ratkaisua jäsenten nimien, syntymäaikojen, sosiaaliturvatunnusten (SSN) ja muiden arkaluonteisten tietojen häivyttämiseen reaaliaikaisesti, kun kehittäjät hakevat tietokokonaisuuksia.
Datan peittämisratkaisun avulla Independence Health pystyy suojaamaan asiakkaiden arkaluonteisia tietoja paremmin, mikä vähentää mahdollisia tietomurrosta aiheutuvia kustannuksia.
Samsung
Samsung työskentelee matkapuhelinten ja älytelevisiotuotteiden analysoimiseksi ja tuottamiseksi kaikkialla maailmassa. Suorittaessaan tuoteanalyysejä miljoonille Samsung Galaxy Smartphone -laitteille yrityksen on suojattava henkilökohtaisia yksityisiä tietoja paikallisen sääntelyn sääntöjen ja menettelyjen mukaisesti.
Suojatakseen yksityisyydensuojan lakisääteisen noudattamisen Samsung on tehnyt yhteistyötä Dataguisen kanssa. Dataguisen Hadoop-työkalu havaitsee automaattisesti kuluttajien yksityisyyden suojaa koskevat tiedot ja salaa ne ennen tietojen siirtämistä AWS:n analytiikkatyökaluihin, jotta vain valtuutetut käyttäjät pääsevät käsiksi reaaliaineistoon ja voivat tehdä analyysejä siitä.
Mitkä ovat tietojen peittämisen parhaat käytännöt?
- Varmista, että löysit kaikki arkaluonteiset tiedot yrityksen tietokannasta ennen niiden siirtämistä testausympäristöön.
- Ymmärrä arkaluonteiset tietosi ja määritä sopivin datan peittämistekniikka sen mukaisesti.
- Käytä peruuttamattomia menetelmiä, jotta tietojasi ei voida muuttaa takaisin alkuperäiseksi versioksi.
Mitä johtavia datan peittämistyökaluja on olemassa?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (for SDM)
- Mentis
- Oracle Advanced Security (for DDM)
- Oracle’s Data Masking and Subsetting Pack (for SDM)
- Privacy Analytics
- Solix Data Masking
Jos olet kiinnostunut muista tietoturvaratkaisuista, joiden avulla voit suojata yritystietojasi tietoverkkouhkilta, alla on sinulle suositeltava lukulista:
- Endpoint Security: In-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Puolustaudu tekoälyavusteisia kyberhyökkäyksiä vastaan
- Managed Security Services (MSS):
- Security Analytics: Comprehensive Guide: Comprehensive Guide
- Security Analytics: Perimmäinen opas
- Deception Technology: In-Depth Guide