Dado el aumento de las amenazas cibernéticas y la implementación de la legislación sobre privacidad de datos como el GDPR en la UE o la CCPA en los Estados Unidos, las empresas necesitan asegurarse de que los datos privados se utilicen lo menos posible. El enmascaramiento de datos proporciona una forma de limitar el uso de datos privados al tiempo que permite a las empresas probar sus sistemas con datos lo más parecidos a los reales.
El coste medio de una violación de datos fue de 4 millones de dólares en 2019. Esto crea un fuerte incentivo para que las empresas inviertan en soluciones de seguridad de la información, incluyendo el enmascaramiento de datos para proteger los datos sensibles. El enmascaramiento de datos es una solución imprescindible para las organizaciones que desean cumplir con el GDPR o utilizar datos realistas en un entorno de pruebas.
- ¿Qué es el enmascaramiento de datos?
- ¿Por qué es importante ahora el enmascaramiento de datos?
- ¿Cómo funciona el enmascaramiento de datos?
- ¿Cuáles son los tipos de enmascaramiento de datos?
- ¿Cuáles son las técnicas de enmascaramiento de datos?
- Adecuado para la gestión de datos de prueba
- Sustitución
- Shuffling
- Varianza de números y fechas
- Encriptación
- Reordenación de caracteres
- Adecuado para compartir datos con usuarios no autorizados
- Nulling out o Deletion
- Enmascaramiento
- ¿En qué se diferencia el enmascaramiento de datos de los datos sintéticos?
- ¿Qué tipos de datos requieren enmascaramiento de datos?
- ¿Cómo promueve el GDPR el enmascaramiento de datos?
- ¿Cuáles son algunos ejemplos de casos de enmascaramiento de datos?
- Independence Health Group
- Samsung
- ¿Cuáles son las mejores prácticas de enmascaramiento de datos?
- ¿Cuáles son las principales herramientas de enmascaramiento de datos?
¿Qué es el enmascaramiento de datos?
El enmascaramiento de datos también se conoce como ofuscación de datos, anonimización de datos o seudonimización. Es el proceso de sustituir los datos confidenciales por el uso de datos funcionales ficticios, como caracteres u otros datos. El objetivo principal del enmascaramiento de datos es proteger la información sensible y privada en situaciones en las que la empresa comparte datos con terceros.
¿Por qué es importante ahora el enmascaramiento de datos?
El número de violaciones de datos está aumentando cada año (En comparación con la mitad del año 2018, el número de violaciones registradas aumentó un 54% en 2019) Por lo tanto, las organizaciones necesitan mejorar sus sistemas de seguridad de datos. La necesidad de enmascaramiento de datos está aumentando debido a las siguientes razones:
- Las organizaciones necesitan una copia de los datos de producción cuando deciden utilizarlos por razones ajenas a la producción, como las pruebas de aplicaciones o el modelado de análisis de negocios.
- La política de privacidad de los datos de su empresa también se ve amenazada por personas internas. Por lo tanto, las organizaciones deben seguir siendo cuidadosas mientras permiten el acceso a los empleados con información privilegiada. Según la encuesta 2019 Insider Data Breach,
- el 79% de los CIOs cree que los empleados han puesto en riesgo los datos de la empresa de forma accidental en los últimos 12 meses, mientras que el 61% cree que los empleados han puesto en riesgo los datos de la empresa de forma maliciosa.
- El 95% reconoce que las amenazas de seguridad internas son un peligro para su organización
- El GDPR y la CCPA obligan a las empresas a reforzar sus sistemas de protección de datos, ya que de lo contrario las organizaciones tienen que pagar fuertes multas.
¿Cómo funciona el enmascaramiento de datos?
El proceso de enmascaramiento de datos es sencillo, pero tiene diferentes técnicas y tipos. En general, las organizaciones empiezan por identificar todos los datos sensibles que tiene su empresa. A continuación, utilizan algoritmos para enmascarar los datos sensibles y sustituirlos por datos estructuralmente idénticos pero numéricamente diferentes. ¿Qué queremos decir con estructuralmente idénticos? Por ejemplo, los números de pasaporte tienen 9 dígitos en Estados Unidos y las personas suelen tener que compartir su información de pasaporte con las compañías aéreas. Cuando una compañía aérea construye un modelo para analizar y probar el entorno empresarial, crea un ID de pasaporte de 9 dígitos diferentes o sustituye algunos dígitos por caracteres.
Aquí tiene un ejemplo de cómo funciona el enmascaramiento de datos:
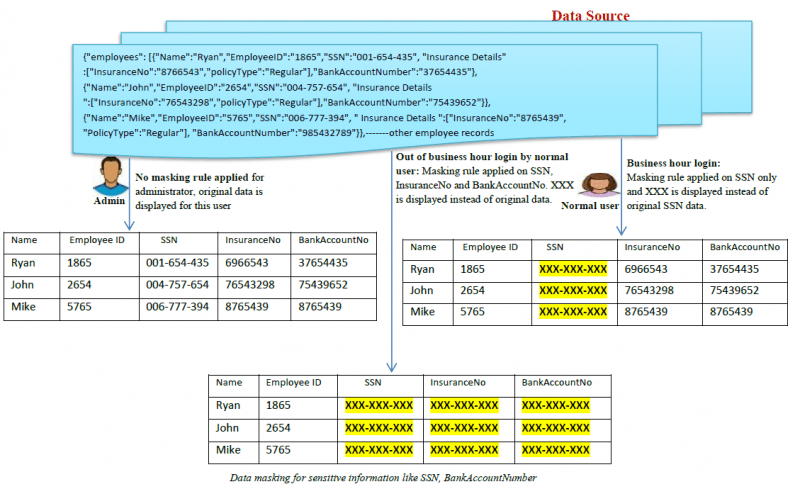
¿Cuáles son los tipos de enmascaramiento de datos?
- Enmascaramiento de datos estático (SDM): En el SDM, los datos se enmascaran en la base de datos original y luego se duplican en un entorno de prueba para que las empresas puedan compartir el entorno de datos de prueba con terceros proveedores.
- Enmascaramiento dinámico de datos (DDM): En DDM, no hay necesidad de una segunda fuente de datos para almacenar los datos enmascarados de forma dinámica. Los datos sensibles originales permanecen en el repositorio y son accesibles para una
aplicación cuando el sistema lo autoriza. Los datos nunca se exponen a usuarios no autorizados, los contenidos se barajan en tiempo real bajo demanda para hacer que los contenidos estén enmascarados. Sólo los usuarios autorizados pueden ver los datos auténticos. Por lo general, se utiliza un proxy inverso para lograr el DDM. Otros métodos dinámicos para lograr el DDM se denominan generalmente enmascaramiento de datos sobre la marcha.
¿Cuáles son las técnicas de enmascaramiento de datos?
Hay numerosas técnicas de enmascaramiento de datos y las clasificamos según su caso de uso.
Adecuado para la gestión de datos de prueba
Sustitución
En el enfoque de sustitución, como su nombre indica, las empresas sustituyen los datos originales por datos aleatorios de un archivo de búsqueda suministrado o personalizado. Esta es una forma eficaz de disfrazar los datos, ya que las empresas conservan el aspecto auténtico de los datos.
Shuffling
Shuffling es otro método común de enmascaramiento de datos. En el método de barajar, al igual que en la sustitución, las empresas sustituyen los datos originales por otros de aspecto auténtico, pero barajan las entidades de la misma columna de forma aleatoria.
Varianza de números y fechas
En el caso de los conjuntos de datos financieros y de fechas, aplicar la misma varianza para crear un nuevo conjunto de datos no cambia la precisión del conjunto de datos mientras se enmascaran los datos. El uso de la varianza para crear un nuevo conjunto de datos también se utiliza comúnmente en la generación de datos sintéticos. Si planea proteger la privacidad de los datos con esta técnica, le recomendamos que lea nuestra guía completa sobre la generación de datos sintéticos.
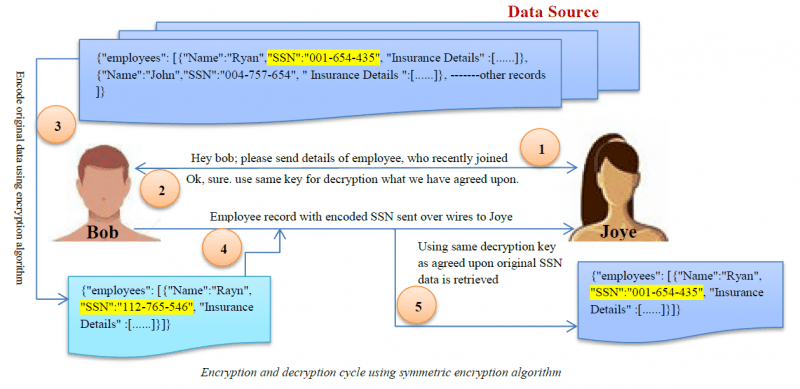
Encriptación
La encriptación es el algoritmo de enmascaramiento de datos más complejo. Los usuarios pueden acceder a los datos sólo si tienen la clave de descifrado.
Reordenación de caracteres
Este método consiste en reordenar aleatoriamente el orden de los caracteres. Este proceso es irreversible, por lo que los datos originales no pueden obtenerse a partir de los datos revueltos.
Adecuado para compartir datos con usuarios no autorizados
Nulling out o Deletion
Reemplazar los datos sensibles con un valor nulo es también un enfoque que las empresas pueden preferir en sus esfuerzos de enmascaramiento de datos. Aunque reduce la precisión de los resultados de las pruebas que se mantienen en su mayoría en otros enfoques, es un enfoque más sencillo cuando las empresas no están enmascarando debido a los propósitos de validación del modelo.
Enmascaramiento
En el método de enmascaramiento, sólo se enmascara una parte de los datos originales. Es similar a la anulación, ya que no es eficaz en el entorno de prueba. Por ejemplo, en las compras en línea, sólo se muestran a los clientes los últimos 4 dígitos del número de la tarjeta de crédito para evitar el fraude.
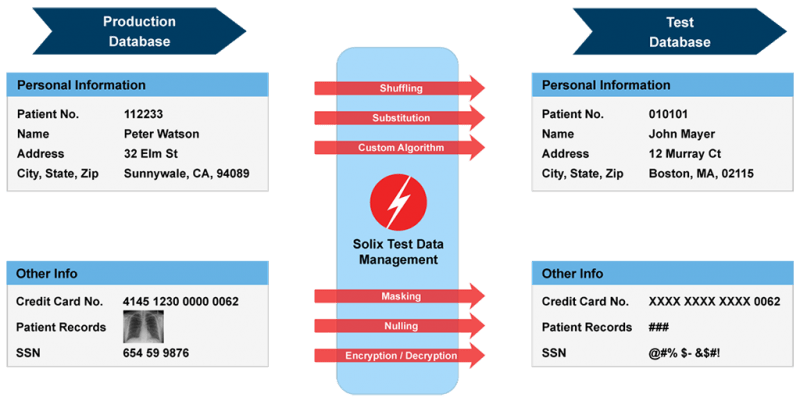
Fuente: Solix Technologies
¿En qué se diferencia el enmascaramiento de datos de los datos sintéticos?

Para crear datos de prueba que cumplan con la normativa GDPR, las organizaciones tienen dos opciones: generar datos sintéticos o enmascarar los datos con diferentes algoritmos. Aunque estas dos técnicas de prueba sirven para el mismo propósito, cada método tiene diferentes beneficios y riesgos.
El enmascaramiento de datos es el proceso de crear una copia de datos del mundo real que se oscurece en campos específicos dentro de un conjunto de datos. Sin embargo, aunque la organización aplique las técnicas de enmascaramiento de datos más complejas y exhaustivas, existe una pequeña posibilidad de que alguien pueda identificar a personas individuales basándose en las tendencias de los datos enmascarados. Por lo tanto, existe el riesgo de revelar información a terceros.
Por otro lado, los datos sintéticos son datos creados artificialmente en lugar de ser generados por eventos reales. No contienen información real sobre los individuos, sino que se crean basándose en el modelo de datos o en los modelos de mensajes que una empresa utiliza para sus sistemas de producción. Para los casos en que una empresa está probando una aplicación completamente nueva o la empresa cree que su enmascaramiento de datos no es suficiente, el uso de datos sintéticos es la respuesta.
¿Qué tipos de datos requieren enmascaramiento de datos?
- Información personal identificable (PII): Cualquier dato que pueda ser potencialmente utilizado para identificar a una persona en particular. Por ejemplo, el nombre completo, el número de la seguridad social, el número del carné de conducir y el número del pasaporte.
- Información sanitaria protegida (PHI): La PHI incluye información demográfica, historiales médicos, resultados de pruebas y laboratorios, condiciones de salud mental, información de seguros y otros datos que un profesional de la salud recoge para identificar la atención adecuada.
- Información de tarjetas de pago (PCI-DSS): Existe una norma de seguridad de la información que deben seguir las organizaciones cuando manejan tarjetas de crédito de marca de las principales redes de tarjetas.
- Propiedad intelectual (PI): La PI se refiere a las creaciones de la mente, como las invenciones; las obras literarias y artísticas; los diseños; y los símbolos, nombres e imágenes utilizados en el comercio.
¿Cómo promueve el GDPR el enmascaramiento de datos?
El enmascaramiento de datos es aceptado como una técnica para proteger los datos de las personas por el GDPR. Estos son los artículos relacionados en los que el GDPR anima a las empresas a utilizar la seudonimización:
Artículo 6 (4-e): «la existencia de garantías adecuadas, que pueden incluir el cifrado o la seudonimización»
Artículo 25 (1): «Teniendo en cuenta el estado de la técnica, el coste de aplicación y la naturaleza, el alcance, el contexto y los fines del tratamiento, así como los riesgos de probabilidad y gravedad variables para los derechos y libertades de las personas físicas que entraña el tratamiento, el responsable del tratamiento deberá, tanto en el momento de determinar los medios para el tratamiento como en el momento del propio tratamiento aplicar las medidas técnicas y organizativas apropiadas, como la seudonimización, destinadas a aplicar los principios de protección de datos, como la minimización de datos, de manera efectiva y a integrar las garantías necesarias en el tratamiento para cumplir los requisitos del presente Reglamento y proteger los derechos de los interesados»
Artículo 32 (a): «El responsable y el encargado del tratamiento aplicarán las medidas técnicas y organizativas apropiadas para garantizar un nivel de seguridad adecuado al riesgo, incluyendo, entre otras cosas, según proceda: la seudonimización y el cifrado de los datos personales.»
Artículo 40 (2): «Las asociaciones y otros organismos que representen a categorías de responsables o encargados del tratamiento podrán elaborar códigos de conducta, o modificar o ampliar dichos códigos, con el fin de especificar la aplicación del presente Reglamento, por ejemplo en lo que respecta a:
- d) la seudonimización de los datos personales
Artículo 89 (1): «El tratamiento con fines de archivo en interés público, fines de investigación científica o histórica o fines estadísticos, estará sometido a las garantías adecuadas, incluidas la minimización de datos y la seudonimización»
¿Cuáles son algunos ejemplos de casos de enmascaramiento de datos?
Independence Health Group
Independence Health Group es la principal compañía de seguros de salud que ofrece una amplia gama de servicios que incluyen cobertura médica comercial, de Medicare y Medicaid, administración de beneficios de terceros, gestión de beneficios de farmacia y compensación de trabajadores. Independence Health quería que los desarrolladores internos y externos pudieran probar las aplicaciones con datos reales, pero necesitaban enmascarar la PHI y otra información de identificación personal. Decidieron utilizar Informatica Dynamic Data Masking para enmascarar los nombres de los miembros, las fechas de nacimiento, los números de la seguridad social (SSN) y otros datos confidenciales en tiempo real a medida que los desarrolladores extraen conjuntos de datos.
Con una solución de enmascaramiento de datos, Independence Health puede proteger mejor los datos confidenciales de los clientes, lo que reduce el coste potencial de una filtración de datos.
Samsung
Samsung trabaja en el análisis y la producción de productos móviles y televisores inteligentes en todo el mundo. Mientras realiza el análisis de productos en millones de dispositivos Samsung Galaxy Smartphone, la empresa tiene que proteger la información privada personal de acuerdo con las normas y procedimientos de la regulación local.
Para garantizar el cumplimiento legal de la privacidad personal, Samsung se ha asociado con Dataguise. La herramienta de Dataguise para Hadoop descubre automáticamente los datos de privacidad de los consumidores y los encripta antes de migrar los datos a las herramientas de análisis de AWS para que solo los usuarios autorizados puedan acceder y realizar análisis sobre los datos reales.
¿Cuáles son las mejores prácticas de enmascaramiento de datos?
- Asegúrese de descubrir todos los datos sensibles en la base de datos de la empresa antes de transferirlos al entorno de pruebas.
- Comprenda sus datos sensibles e identifique la técnica de enmascaramiento de datos más adecuada en consecuencia.
- Utilice métodos irreversibles para que sus datos no puedan ser transformados de nuevo a la versión original.
¿Cuáles son las principales herramientas de enmascaramiento de datos?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (para SDM)
- Mentis
- Oracle Advanced Security (para DDM)
- Oracle’s Data Masking and Subsetting Pack (para SDM)
- Privacy Analytics
- Solix Data Masking
Si está interesado en otras soluciones de seguridad para proteger los datos de su empresa de las ciberamenazas, a continuación le ofrecemos una lista de lecturas recomendadas:
- Seguridad de puntos finales: guía en profundidad
- La guía definitiva de la inteligencia sobre ciberamenazas (CTI)
- Seguridad de la IA: Defiéndase contra los ciberataques impulsados por la IA
- Servicios de seguridad gestionados (MSS): Guía completa
- Security Analytics: La guía definitiva
- Tecnología del engaño: guía en profundidad