I betragtning af de stigende cybertrusler og implementeringen af lovgivning om databeskyttelse som GDPR i EU eller CCPA i USA er virksomheder nødt til at sikre, at private data bruges så lidt som muligt. Datamaskering giver en måde at begrænse brugen af private data på, samtidig med at virksomheder kan teste deres systemer med data, der er så tæt på virkelige data som muligt.
Den gennemsnitlige omkostning ved et databrud var 4 millioner dollars i 2019. Dette skaber et stærkt incitament for virksomheder til at investere i informationssikkerhedsløsninger, herunder datamaskering for at beskytte følsomme data. Datamaskering er en uundværlig løsning for organisationer, der ønsker at overholde GDPR eller at bruge realistiske data i et testmiljø.
- Hvad er datamaskering?
- Hvorfor er datamaskering vigtig nu?
- Hvordan virker datamaskering?
- Hvad er typerne af datamaskering?
- Hvad er teknikkerne til datamaskering?
- Velegnet til testdatahåndtering
- Substitution
- Shuffling
- Nummer- og datovarians
- Kryptering
- Karakterforvrængning
- Velegnet til deling af data med uautoriserede brugere
- Nulling out or Deletion
- Masking out
- Hvordan er datamaskering anderledes end syntetiske data?
- Hvilke typer data kræver datamaskering?
- Hvordan fremmer GDPR datamaskering?
- Hvad er nogle eksempler på casestudier af datamaskering?
- Independence Health Group
- Samsung
- Hvad er den bedste praksis for datamaskering?
- Hvad er de førende værktøjer til datamaskering?
Hvad er datamaskering?
Datamaskering omtales også som dataobfuskering, dataanonymisering eller pseudonymisering. Det er processen med at erstatte fortrolige data ved hjælp af funktionelle fiktive data som f.eks. tegn eller andre data. Hovedformålet med datamaskering er at beskytte følsomme, private oplysninger i situationer, hvor virksomheden deler data med tredjeparter.
Hvorfor er datamaskering vigtig nu?
Antallet af databrud stiger hvert år (Sammenlignet med midten af 2018 var antallet af registrerede brud steget med 54 % i 2019) Derfor er organisationer nødt til at forbedre deres datasikkerhedssystemer. Behovet for datamaskering er stigende af følgende årsager:
- Organisationer har brug for en kopi af produktionsdata, når de beslutter sig for at bruge dem til ikke-produktionsmæssige formål som f.eks. applikationstest eller forretningsanalysemodellering.
- Din virksomheds politik for databeskyttelse er også truet af insidere. Derfor bør organisationer stadig være forsigtige, mens de giver insidermedarbejdere adgang. Ifølge 2019 Insider Data Breach-undersøgelsen
- 79% af CIO’erne mener, at medarbejdere har bragt virksomhedens data i fare ved et uheld i de sidste 12 måneder, mens 61% mener, at medarbejdere har bragt virksomhedens data i fare i ond hensigt.
- 95% erkender, at insidersikkerhedstrusler er en fare for deres organisation
- GDPR og CCPA tvinger virksomheder til at styrke deres databeskyttelsessystemer, ellers skal organisationer betale store bøder.
Hvordan virker datamaskering?
Datamaskeringsprocessen er enkel, men den har forskellige teknikker og typer. Generelt starter organisationer med at identificere alle følsomme data, som din virksomhed ligger inde med. Derefter bruger de algoritmer til at maskere følsomme data og erstatte dem med strukturelt identiske, men numerisk forskellige data. Hvad mener vi med strukturelt identiske? F.eks. er pasnumre 9 cifre i USA, og enkeltpersoner er normalt nødt til at dele deres pasoplysninger med flyselskaberne. Når et flyselskab opbygger en model for at analysere og teste forretningsmiljøet, opretter de et andet 9-cifret langt pas-id eller erstatter nogle cifre med tegn.
Her er et eksempel på, hvordan datamaskering fungerer:
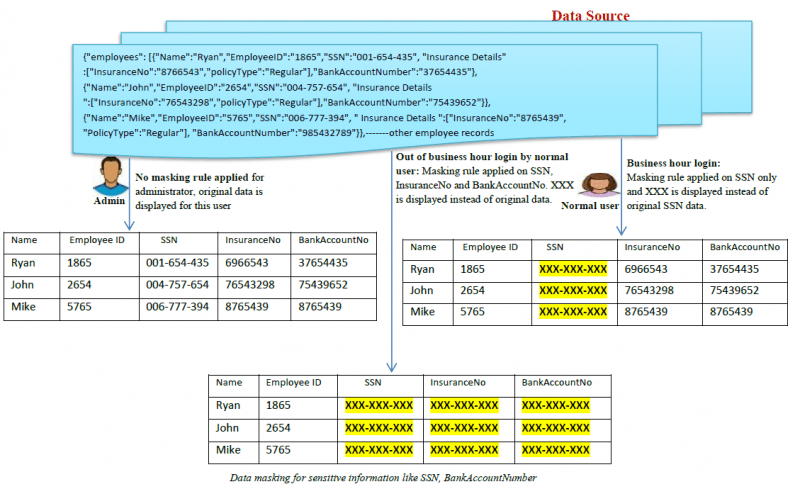
Hvad er typerne af datamaskering?
- Statisk datamaskering (SDM): I SDM maskeres data i den oprindelige database og kopieres derefter til et testmiljø, så virksomhederne kan dele testdatamiljøet med tredjepartsleverandører.
- Dynamisk datamaskering (DDM): Data maskeres i den oprindelige database og kopieres derefter til et testmiljø, så virksomhederne kan dele testdatamiljøet med tredjepartsleverandører.
- I DDM er der ikke behov for en anden datakilde til dynamisk lagring af de maskerede data. De oprindelige følsomme data forbliver i lageret og er tilgængelige for en
applikation, når systemet har givet tilladelse hertil. Dataene udsættes aldrig for uautoriserede brugere, indholdet blandes i realtid på anmodning for at gøre indholdet maskeret. Kun autoriserede brugere er i stand til at se autentiske data. Der anvendes normalt en reverse proxy til at opnå DDM. Andre dynamiske metoder til at opnå DDM kaldes generelt on-the-fly datamaskering.
Hvad er teknikkerne til datamaskering?
Der findes mange teknikker til datamaskering, og vi har klassificeret dem efter deres anvendelsesområde.
Velegnet til testdatahåndtering
Substitution
I substitutionsmetoden erstatter virksomhederne, som navnet antyder, de oprindelige data med tilfældige data fra en leveret eller tilpasset opslagsfil. Dette er en effektiv måde at skjule data på, da virksomhederne bevarer dataenes autentiske udseende.
Shuffling
Shuffling er en anden almindelig datamaskeringsmetode. I shuffling-metoden erstatter virksomhederne ligesom ved substitution de oprindelige data med andre data, der ser autentiske ud, men de blander enhederne i den samme kolonne tilfældigt.
Nummer- og datovarians
For finansielle og datadrevne datasæt ændrer anvendelsen af den samme varians til at skabe et nyt datasæt ikke datasættets nøjagtighed, mens data maskeres. Anvendelse af varians til at oprette et nyt datasæt er også almindeligt anvendt ved generering af syntetiske data. Hvis du planlægger at beskytte datasikkerhed med denne teknik, anbefaler vi, at du læser vores omfattende vejledning om generering af syntetiske data.
Kryptering
Kryptering er den mest komplekse datamaskeringsalgoritme. Brugere kan kun få adgang til data, hvis de har dekrypteringsnøglen.
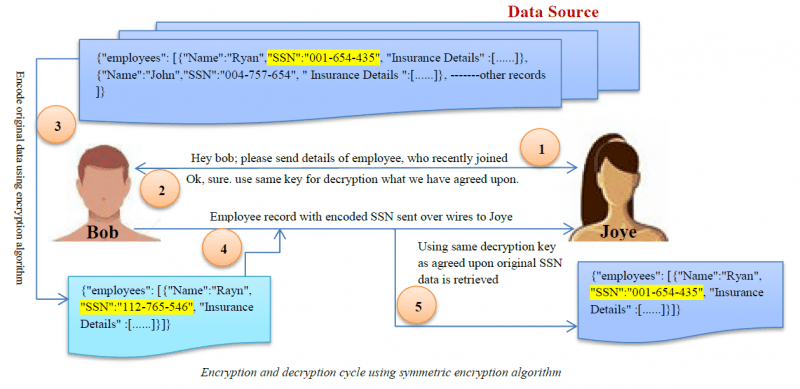
Karakterforvrængning
Denne metode indebærer, at rækkefølgen af tegn omarrangeres tilfældigt. Denne proces er irreversibel, så de originale data kan ikke fås fra de forvrængede data.
Velegnet til deling af data med uautoriserede brugere
Nulling out or Deletion
Udskiftning af følsomme data med nulværdi er også en tilgang, som virksomheder kan foretrække i deres bestræbelser på datamaskering. Selv om det reducerer nøjagtigheden af testresultater, som for det meste opretholdes i andre tilgange, er det en enklere tilgang, når virksomheder ikke maskerer på grund af modelvalideringsformål.
Masking out
I masking out-metoden maskeres kun en del af de oprindelige data. Det svarer til nulling out, da det ikke er effektivt i testmiljøet. Ved online-shopping vises kun de sidste 4 cifre i kreditkortnummeret for kunderne for at forhindre svindel.
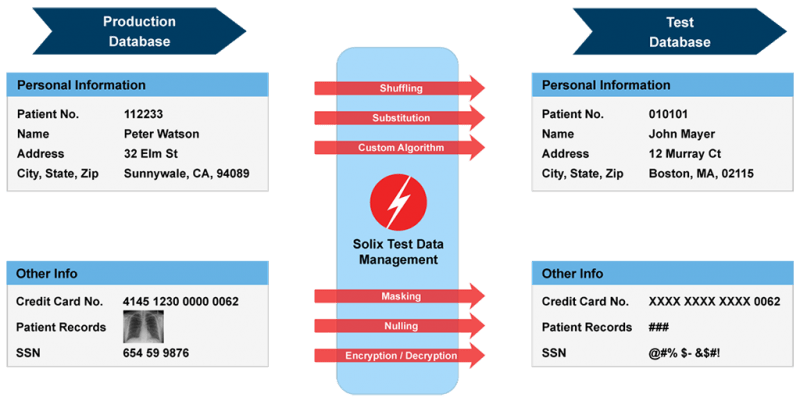
Kilde: Solix Technologies
Hvordan er datamaskering anderledes end syntetiske data?

For at skabe testdata, der er i overensstemmelse med GDPR-reglerne, har organisationer to muligheder: generering af syntetiske data eller maskering af data med forskellige algoritmer. Selv om disse to testteknikker tjener samme formål, har hver metode forskellige fordele og risici.
Datamaskering er processen med at skabe en kopi af data fra den virkelige verden, som er skjult i specifikke felter i et datasæt. Men selv om organisationen anvender de mest komplekse og omfattende teknikker til datamaskering, er der en lille chance for, at nogen kan identificere individuelle personer på baggrund af tendenser i de maskerede data. Derfor er der risiko for at frigive oplysninger til tredjeparter.
På den anden side er syntetiske data data data, der er kunstigt skabt i stedet for at blive genereret af faktiske begivenheder. De indeholder ikke reelle oplysninger om enkeltpersoner, de oprettes på grundlag af den datamodel eller de meddelelsesmodeller, som en virksomhed anvender til sine produktionssystemer. I tilfælde, hvor en virksomhed tester en helt ny applikation, eller hvor virksomheden mener, at deres datamaskering ikke er tilstrækkelig, er brugen af syntetiske data løsningen.
Hvilke typer data kræver datamaskering?
- Personligt identificerbare oplysninger (PII): Alle data, der potentielt kan bruges til at identificere en bestemt person. F.eks. fulde navn, socialsikringsnummer, kørekortnummer og pasnummer.
- Beskyttede sundhedsoplysninger (PHI): PHI omfatter demografiske oplysninger, medicinske historier, test- og laboratorieresultater, psykiske helbredsforhold, forsikringsoplysninger og andre data, som en sundhedsperson indsamler for at identificere passende behandling.
- Betalingskortoplysninger (PCI-DSS): Der er en informationssikkerhedsstandard, som organisationer skal følge, når de håndterer mærkevarekreditkort fra de store kortordninger.
- Intellektuel ejendom (IP): IP henviser til intellektuelle frembringelser som f.eks. opfindelser, litterære og kunstneriske værker, design og symboler, navne og billeder, der anvendes i handelen.
Hvordan fremmer GDPR datamaskering?
Datamaskering er accepteret som en teknik til at beskytte enkeltpersoners data i GDPR. Her er de relaterede artikler, hvor GDPR tilskynder virksomheder til at bruge pseudonymisering:
Artikel 6 (4-e):
Artikel 25, stk. 1: “Der skal være passende sikkerhedsforanstaltninger, som kan omfatte kryptering eller pseudonymisering.”
Artikel 25, stk. 1: “Der skal være passende sikkerhedsforanstaltninger, som kan omfatte kryptering eller pseudonymisering: “Under hensyntagen til det aktuelle tekniske niveau, omkostningerne ved gennemførelsen og behandlingens art, omfang, kontekst og formål samt de risici af varierende sandsynlighed og alvor for fysiske personers rettigheder og frihedsrettigheder, som behandlingen indebærer, skal den dataansvarlige både på tidspunktet for fastlæggelsen af midlerne til behandling og på tidspunktet for selve behandlingen, gennemføre passende tekniske og organisatoriske foranstaltninger, såsom pseudonymisering, som er udformet med henblik på at gennemføre databeskyttelsesprincipper, såsom dataminimering, på en effektiv måde og integrere de nødvendige garantier i behandlingen for at opfylde kravene i denne forordning og beskytte de registreredes rettigheder.”
Artikel 32, litra a): “Den dataansvarlige og databehandleren skal gennemføre passende tekniske og organisatoriske foranstaltninger for at sikre et sikkerhedsniveau, der står i et rimeligt forhold til risikoen, herunder bl.a., hvor det er relevant: pseudonymisering og kryptering af personoplysninger.”
Artikel 40, stk. 2: “Sammenslutninger og andre organer, der repræsenterer kategorier af registeransvarlige eller registerførere, kan udarbejde adfærdskodekser eller ændre eller udvide sådanne kodekser med henblik på at præcisere anvendelsen af denne forordning, f.eks. med hensyn til:
- (d) pseudonymisering af personoplysninger
Artikel 89, stk. 1: “Behandling til arkivformål i offentlighedens interesse, til videnskabelige eller historiske forskningsformål eller til statistiske formål skal være omfattet af passende garantier, herunder dataminimering og pseudonymisering.”
Hvad er nogle eksempler på casestudier af datamaskering?
Independence Health Group
Independence Health Group er det førende sundhedsforsikringsselskab, der tilbyder en bred vifte af tjenester, herunder kommerciel, Medicare og Medicaid medicinsk dækning, administration af tredjepartsydelser, administration af apoteksydelser og arbejdsskadeforsikring. Independence Health ønskede at give on- og off-shore-udviklere mulighed for at teste applikationer ved hjælp af rigtige data, men de havde dog brug for at maskere PHI og andre personligt identificerbare oplysninger. De besluttede at bruge Informatica Dynamic Data Masking til at skjule medlemmernes navne, fødselsdatoer, socialsikringsnumre (SSN) og andre følsomme data i realtid, mens udviklerne trækker datasæt ned.
Med en datamaskeringsløsning kan Independence Health bedre beskytte følsomme kundedata, hvilket reducerer de potentielle omkostninger ved et databrud.
Samsung
Samsung arbejder med at analysere og producere mobil og smart-tv-produkter over hele verden. Mens virksomheden udfører produktanalyser på millioner af Samsung Galaxy Smartphone-enheder, skal den beskytte personlige private oplysninger i overensstemmelse med reglerne og procedurerne i den lokale lovgivning.
For at sikre den juridiske overholdelse af personlige oplysninger har Samsung indgået et samarbejde med Dataguise. Dataguises værktøj til Hadoop opdager automatisk data om forbrugernes privatliv og krypterer dem, inden dataene migreres til AWS-analyseværktøjer, så kun autoriserede brugere kan få adgang til og udføre analyser på rigtige data.
Hvad er den bedste praksis for datamaskering?
- Sørg for, at du har opdaget alle følsomme data i virksomhedens database, før du overfører dem til testmiljøet.
- Forstå dine følsomme data, og identificer den bedst egnede teknik til datamaskering i overensstemmelse hermed.
- Brug irreversible metoder, så dine data ikke kan omdannes tilbage til den oprindelige version.
Hvad er de førende værktøjer til datamaskering?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (for SDM)
- Mentis
- Oracle Advanced Security (for DDM)
- Oracle’s Data Masking and Subsetting Pack (for SDM)
- Privacy Analytics
- Solix Data Masking
Hvis du er interesseret i andre sikkerhedsløsninger til at beskytte dine virksomhedsdata mod cybertrusler, er der nedenfor en anbefalet læseliste til dig:
- Endpoint Security: In-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Forsvar mod AI-drevne cyberangreb
- Managed Security Services (MSS): Beskyttelse mod AI-drevne cyberangreb
- Comprehensive Guide
- Security Analytics: Den ultimative guide
- Deceptionsteknologi: Uddybende guide