Med tanke på de ökande cyberhoten och genomförandet av dataskyddslagstiftning som GDPR i EU eller CCPA i USA måste företag se till att privata uppgifter används så lite som möjligt. Datamaskering är ett sätt att begränsa användningen av privata data och samtidigt göra det möjligt för företag att testa sina system med data som ligger så nära riktiga data som möjligt.
Den genomsnittliga kostnaden för ett dataintrång var 4 miljoner dollar under 2019. Detta skapar ett starkt incitament för företag att investera i informationssäkerhetslösningar, inklusive datamaskning, för att skydda känsliga uppgifter. Datamaskning är en nödvändig lösning för organisationer som vill följa GDPR eller använda realistiska data i en testmiljö.
- Vad är datamaskning?
- Varför är datamaskning viktigt nu?
- Hur fungerar datamaskning?
- Vilka typer av datamaskning finns det?
- Vilka är teknikerna för datamaskning?
- Lämplig för hantering av testdata
- Substitution
- Shuffling
- Nummer- och datumvarians
- Kryptering
- Karakterförvrängning
- Lämpligt för att dela data med obehöriga användare
- Nullning eller radering
- Masking out
- Hur skiljer sig datamaskning från syntetiska data?
- Vilka typer av data kräver datamaskning?
- Hur främjar GDPR datamaskering?
- Vad är några exempel på fallstudier av datamaskering?
- Independence Health Group
- Samsung
- Vilka är de bästa metoderna för datamaskning?
- Vilka är de ledande verktygen för datamaskning?
Vad är datamaskning?
Datamaskning kallas också för dataförvrängning, dataanonymisering eller pseudonymisering. Det är en process där konfidentiella uppgifter ersätts med hjälp av funktionella fiktiva uppgifter, t.ex. tecken eller andra uppgifter. Huvudsyftet med datamaskning är att skydda känslig, privat information i situationer där företaget delar data med tredje part.
Varför är datamaskning viktigt nu?
Antalet dataintrång ökar varje år (Jämfört med mitten av 2018 ökade antalet registrerade dataintrång med 54 % under 2019) Därför måste organisationer förbättra sina datasäkerhetssystem. Behovet av datamaskering ökar av följande skäl:
- Organisationer behöver en kopia av produktionsdata när de bestämmer sig för att använda dem av icke-produktionsskäl, t.ex. för applikationstestning eller modellering av affärsanalyser.
- Ditt företags dataskyddspolicy hotas även av insiders. Därför bör organisationer fortfarande vara försiktiga när de tillåter åtkomst för insideranställda. Enligt 2019 Insider Data Breach survey,
- 79 % av CIO:erna tror att anställda har utsatt företagsdata för risker av misstag under de senaste 12 månaderna, medan 61 % tror att anställda har utsatt företagsdata för risker i onödan.
- 95% erkänner att säkerhetshot från insiders är en fara för deras organisation
- GDPR och CCPA tvingar företag att stärka sina dataskyddssystem, annars måste organisationer betala höga böter.
Hur fungerar datamaskning?
Datamaskeringsprocessen är enkel, men den har olika tekniker och typer. I allmänhet börjar organisationer med att identifiera alla känsliga data som ditt företag innehar. Sedan använder de algoritmer för att maskera känsliga data och ersätta dem med strukturellt identiska men numeriskt annorlunda data. Vad menar vi med strukturellt identiska? Till exempel är passnummer 9 siffror i USA och enskilda personer måste vanligtvis dela med sig av sina passuppgifter till flygbolag. När ett flygbolag bygger en modell för att analysera och testa affärsmiljön skapar de ett annat 9-siffrigt långt passnummer eller ersätter vissa siffror med tecken.
Här är ett exempel på hur datamaskning fungerar:
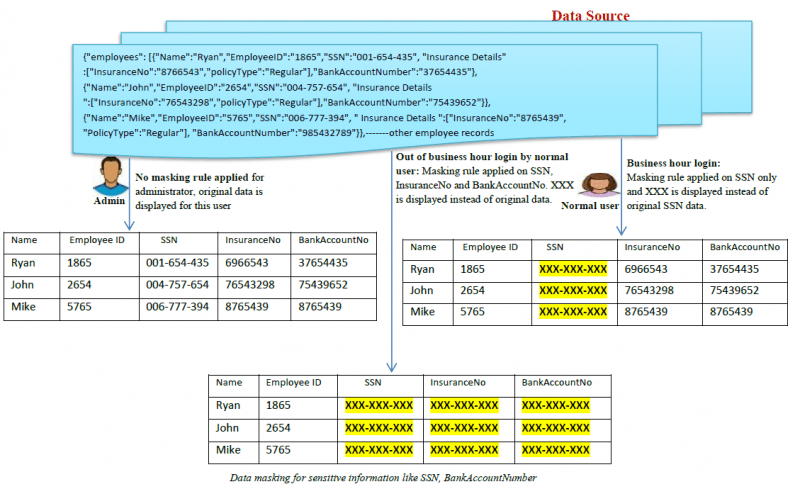
Vilka typer av datamaskning finns det?
- Statisk datamaskning (SDM): I SDM maskeras data i den ursprungliga databasen och kopieras sedan till en testmiljö så att företag kan dela testdatamiljön med tredjepartsleverantörer.
- Dynamisk datamaskning (DDM): Denna typ av maskning innebär att data maskeras i den ursprungliga databasen och sedan kopieras till en testmiljö så att företag kan dela testdatamiljön med tredjepartsleverantörer: I DDM behövs ingen andra datakälla för att lagra de maskerade uppgifterna dynamiskt. De ursprungliga känsliga uppgifterna finns kvar i arkivet och är tillgängliga för en
tillämpning när den är auktoriserad av systemet. Data exponeras aldrig för obehöriga användare, innehållet blandas i realtid på begäran för att göra innehållet maskerat. Endast auktoriserade användare kan se autentiska data. En omvänd proxy används i allmänhet för att uppnå DDM. Andra dynamiska metoder för att uppnå DDM kallas i allmänhet för on-the-fly datamaskning.
Vilka är teknikerna för datamaskning?
Det finns många tekniker för datamaskning och vi har klassificerat dem enligt deras användningsområde.
Lämplig för hantering av testdata
Substitution
I substitutionsmetoden, som namnet antyder, ersätter företagen de ursprungliga uppgifterna med slumpmässiga uppgifter från en levererad eller anpassad uppslagsfil. Detta är ett effektivt sätt att dölja uppgifter eftersom företagen bevarar uppgifternas autentiska utseende.
Shuffling
Shuffling är en annan vanlig metod för att maskera uppgifter. I shuffling-metoden ersätter företagen, precis som vid substitution, originaldata med en annan data med autentiskt utseende, men de blandar om enheterna i samma kolumn slumpmässigt.
Nummer- och datumvarians
För finansiella och datadrivna datauppsättningar ändrar tillämpningen av samma varians för att skapa en ny datauppsättning inte datauppsättningens noggrannhet samtidigt som data maskeras. Att använda varians för att skapa ett nytt dataset är också vanligt förekommande vid generering av syntetiska data. Om du planerar att skydda dataintegriteten med den här tekniken rekommenderar vi att du läser vår omfattande guide till syntetisk datagenerering.
Kryptering
Kryptering är den mest komplexa algoritmen för datamaskning. Användare kan endast få tillgång till data om de har dekrypteringsnyckeln.
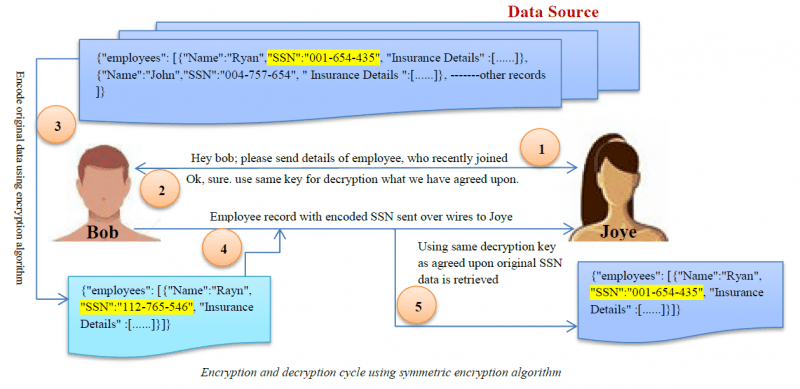
Karakterförvrängning
Denna metod innebär att man slumpmässigt arrangerar om ordningen på tecken. Denna process är oåterkallelig så att originaldata inte kan erhållas från de förvrängda data.
Lämpligt för att dela data med obehöriga användare
Nullning eller radering
Att ersätta känsliga data med ett nollvärde är också ett tillvägagångssätt som företag kan föredra i sitt arbete med datamaskning. Även om det minskar noggrannheten i testresultaten, som oftast bibehålls i andra metoder, är det ett enklare tillvägagångssätt när företag inte maskerar på grund av modellvalidering.
Masking out
I masking out-metoden maskeras endast en viss del av de ursprungliga uppgifterna. Den liknar nulling out eftersom den inte är effektiv i testmiljön. Vid online shopping visas till exempel endast de fyra sista siffrorna i kreditkortsnumret för kunderna för att förhindra bedrägeri.
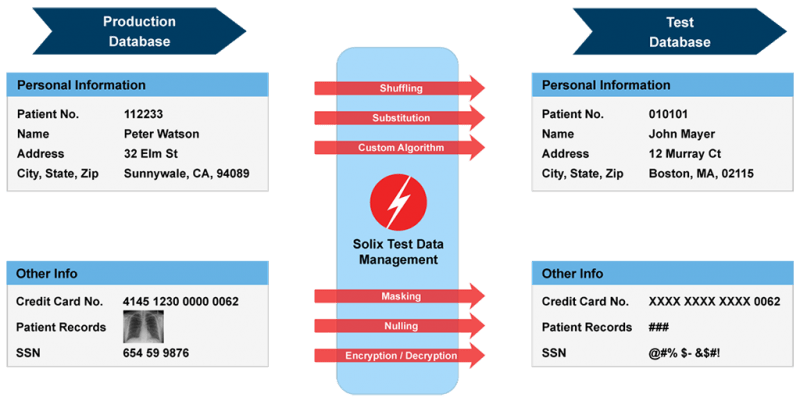
Källa: Solix Technologies
Hur skiljer sig datamaskning från syntetiska data?

För att skapa testdata som uppfyller GDPR-bestämmelserna har organisationer två alternativ: att generera syntetiska data eller maskera data med olika algoritmer. Även om dessa två testtekniker tjänar samma syfte har varje metod olika fördelar och risker.
Datamaskering är en process där man skapar en kopia av verkliga data som döljs i specifika fält i en datamängd. Men även om organisationen tillämpar de mest komplexa och omfattande datamaskningstekniker finns det en liten chans att någon kan identifiera enskilda personer baserat på trender i de maskerade uppgifterna. Därför finns det en risk för att information lämnas ut till tredje part.
Å andra sidan är syntetiska data data data som skapas på konstgjord väg i stället för att genereras av faktiska händelser. De innehåller inte verklig information om individer, utan skapas utifrån den datamodell eller de meddelandemodeller som ett företag använder för sina produktionssystem. I de fall då ett företag testar en helt ny applikation eller då företaget anser att deras datamaskning inte är tillräcklig, är användningen av syntetiska data lösningen.
Vilka typer av data kräver datamaskning?
- Personligt identifierbar information (PII): Alla uppgifter som potentiellt kan användas för att identifiera en viss person. Till exempel fullständigt namn, socialförsäkringsnummer, körkortsnummer och passnummer.
- Skyddad hälsoinformation (PHI): PHI omfattar demografisk information, medicinsk historia, test- och laboratorieresultat, psykiska hälsoproblem, försäkringsinformation och andra uppgifter som en sjukvårdspersonal samlar in för att identifiera lämplig vård.
- Information om betalkort (PCI-DSS): Det finns en informationssäkerhetsstandard som organisationer ska följa när de hanterar märkeskreditkort från de stora kortsystemen.
- Intellektuell egendom (IP): IP avser intellektuella skapelser, t.ex. uppfinningar, litterära och konstnärliga verk, mönster samt symboler, namn och bilder som används i handeln.
Hur främjar GDPR datamaskering?
Datamaskering accepteras som en teknik för att skydda enskilda personers uppgifter i GDPR. Här är de relaterade artiklarna där GDPR uppmuntrar företag att använda pseudonymisering:
Artikel 6 (4-e):
Artikel 25 (1): ”Förekomsten av lämpliga skyddsåtgärder, som kan innefatta kryptering eller pseudonymisering.”
Artikel 25 (1): ”Den personuppgiftsansvarige ska, med beaktande av den senaste tekniken, kostnaden för genomförandet och behandlingens art, omfattning, sammanhang och ändamål samt de risker av varierande sannolikhet och svårighetsgrad för fysiska personers rättigheter och friheter som behandlingen medför, både vid tidpunkten för fastställandet av medlen för behandlingen och vid tidpunkten för själva behandlingen, …”, genomföra lämpliga tekniska och organisatoriska åtgärder, t.ex. pseudonymisering, som är utformade för att genomföra dataskyddsprinciper, t.ex. uppgiftsminimering, på ett effektivt sätt och för att integrera nödvändiga skyddsåtgärder i behandlingen för att uppfylla kraven i denna förordning och skydda de registrerades rättigheter.”
Artikel 32 a: ”Den personuppgiftsansvarige och personuppgiftsbiträdet ska genomföra lämpliga tekniska och organisatoriska åtgärder för att säkerställa en säkerhetsnivå som är lämplig i förhållande till risken, inklusive bland annat i förekommande fall: pseudonymisering och kryptering av personuppgifter.”
Artikel 40.2: ”Sammanslutningar och andra organ som företräder kategorier av registeransvariga eller registerförare får utarbeta uppförandekoder, eller ändra eller utvidga sådana koder, i syfte att specificera tillämpningen av denna förordning, t.ex. när det gäller:
- d) pseudonymisering av personuppgifter
Artikel 89 (1): ”Behandling för arkivändamål i allmänhetens intresse, vetenskapliga eller historiska forskningsändamål eller statistiska ändamål ska omfattas av lämpliga skyddsåtgärder, inklusive dataminimering och pseudonymisering.”
Vad är några exempel på fallstudier av datamaskering?
Independence Health Group
Independence Health Group är det ledande sjukförsäkringsbolaget som erbjuder ett brett utbud av tjänster, bland annat kommersiell, Medicare- och Medicaid-medicinskt täckning, administration av tredjepartsförmåner, hantering av apoteksförmåner och arbetsersättning. Independence Health ville låta utvecklare på plats och utomlands testa applikationer med hjälp av riktiga data, men de behövde dölja PHI och annan personligt identifierbar information. De bestämde sig för att använda Informatica Dynamic Data Masking för att dölja medlemsnamn, födelsedatum, socialförsäkringsnummer (SSN) och andra känsliga uppgifter i realtid när utvecklare hämtar datamängder.
Med en lösning för datamaskning kan Independence Health bättre skydda känsliga kunduppgifter, vilket minskar den potentiella kostnaden för ett dataintrång.
Samsung
Samsung arbetar med att analysera och producera produkter för mobiler och smarta TV-apparater över hela världen. När företaget utför produktanalyser på miljontals Samsung Galaxy Smartphone-enheter måste företaget skydda personlig privat information i enlighet med reglerna och förfarandena i den lokala lagstiftningen.
För att säkerställa laglig efterlevnad av personlig integritet har Samsung samarbetat med Dataguise. Dataguise verktyg för Hadoop upptäcker automatiskt uppgifter om konsumenters integritet och krypterar dem innan data migreras till AWS analysverktyg så att endast auktoriserade användare kan få tillgång till och utföra analyser på riktiga data.
Vilka är de bästa metoderna för datamaskning?
- Säkerställ att du har upptäckt alla känsliga data i företagets databas innan du överför dem till testmiljön.
- Förstå dina känsliga data och identifiera den lämpligaste tekniken för datamaskning i enlighet med detta.
- Använd oåterkalleliga metoder så att dina data inte kan omvandlas tillbaka till originalversionen.
Vilka är de ledande verktygen för datamaskning?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (for SDM)
- Mentis
- Oracle Advanced Security (for DDM)
- Oracle’s Data Masking and Subsetting Pack (for SDM)
- Privacy Analytics
- Solix Data Masking
Om du är intresserad av andra säkerhetslösningar för att skydda dina företagsdata från cyberhot, nedan finns en rekommenderad litteraturlista för dig:
- Endpoint Security: in-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Försvar mot AI-drivna cyberattacker
- Managed Security Services (MSS): Comprehensive Guide
- Security Analytics: Den ultimata guiden
- Denektionsteknologi: en djupgående guide