Wobec rosnących zagrożeń cybernetycznych i wdrażania przepisów dotyczących prywatności danych, takich jak GDPR w UE czy CCPA w USA, firmy muszą zapewnić, że prywatne dane są wykorzystywane w jak najmniejszym stopniu. Maskowanie danych zapewnia sposób na ograniczenie wykorzystania prywatnych danych, jednocześnie umożliwiając przedsiębiorstwom testowanie swoich systemów z danymi, które są tak bliskie prawdziwym danym, jak to tylko możliwe.
Średni koszt naruszenia danych wyniósł 4 miliony dolarów w 2019 roku. Stwarza to silny bodziec dla przedsiębiorstw do inwestowania w rozwiązania bezpieczeństwa informacji, w tym maskowanie danych w celu ochrony wrażliwych danych. Maskowanie danych jest niezbędnym rozwiązaniem dla organizacji, które chcą zachować zgodność z GDPR lub wykorzystać realistyczne dane w środowisku testowym.
- Co to jest maskowanie danych?
- Dlaczego maskowanie danych jest teraz ważne?
- Jak działa maskowanie danych?
- Jakie są rodzaje maskowania danych?
- Jakie są techniki maskowania danych?
- Odpowiednie do zarządzania danymi testowymi
- Zastępowanie
- Shuffling
- Wariantyzacja liczb i dat
- Szyfrowanie
- Character Scrambling
- Nadaje się do udostępniania danych nieautoryzowanym użytkownikom
- Unicestwianie lub usuwanie
- Masking out
- Czym różni się maskowanie danych od danych syntetycznych?
- Jakie typy danych wymagają maskowania danych?
- W jaki sposób GDPR promuje maskowanie danych?
- Jakie są przykładowe studia przypadków maskowania danych?
- Independence Health Group
- Samsung
- Jakie są najlepsze praktyki maskowania danych?
- Jakie są wiodące narzędzia maskowania danych?
Co to jest maskowanie danych?
Maskowanie danych jest również określane jako obfuskacja danych, anonimizacja danych lub pseudonimizacja. Jest to proces zastępowania danych poufnych za pomocą funkcjonalnych danych fikcyjnych, takich jak znaki lub inne dane. Głównym celem maskowania danych jest ochrona wrażliwych, prywatnych informacji w sytuacjach, gdy przedsiębiorstwo dzieli się danymi z osobami trzecimi.
Dlaczego maskowanie danych jest teraz ważne?
Liczba naruszeń danych rośnie z każdym rokiem (W porównaniu z połową roku 2018, liczba odnotowanych naruszeń wzrosła o 54% w 2019 r.) Dlatego organizacje muszą poprawić swoje systemy bezpieczeństwa danych. Zapotrzebowanie na maskowanie danych rośnie z następujących powodów:
- Organizacje potrzebują kopii danych produkcyjnych, gdy zdecydują się wykorzystać je do celów nieprodukcyjnych, takich jak testowanie aplikacji lub modelowanie analityki biznesowej.
- Polityka prywatności danych przedsiębiorstwa jest zagrożona również przez insiderów. Dlatego organizacje nadal powinny zachować ostrożność przy umożliwianiu dostępu pracownikom insiderów. Według badania 2019 Insider Data Breach,
- 79% CIO uważa, że pracownicy narazili dane firmy na ryzyko przypadkowo w ciągu ostatnich 12 miesięcy, podczas gdy 61% uważa, że pracownicy narazili dane firmy na ryzyko złośliwie.
- 95% przyznaje, że wewnętrzne zagrożenia bezpieczeństwa stanowią niebezpieczeństwo dla ich organizacji
- GDPR i CCPA zmuszają firmy do wzmocnienia swoich systemów ochrony danych, w przeciwnym razie organizacje muszą płacić wysokie grzywny.
Jak działa maskowanie danych?
Proces maskowania danych jest prosty, ale ma różne techniki i rodzaje. Ogólnie rzecz biorąc, organizacje zaczynają od zidentyfikowania wszystkich wrażliwych danych posiadanych przez przedsiębiorstwo. Następnie wykorzystują algorytmy do zamaskowania danych wrażliwych i zastąpienia ich danymi strukturalnie identycznymi, ale numerycznie różnymi. Co rozumiemy przez strukturalnie identyczne dane? Na przykład, numer paszportu w USA składa się z 9 cyfr, a osoby fizyczne zazwyczaj muszą dzielić się swoimi danymi paszportowymi z liniami lotniczymi. Gdy firma lotnicza buduje model do analizy i testowania środowiska biznesowego, tworzy inny 9-cyfrowy identyfikator paszportu lub zastępuje niektóre cyfry znakami.
Tutaj znajduje się przykład działania maskowania danych:
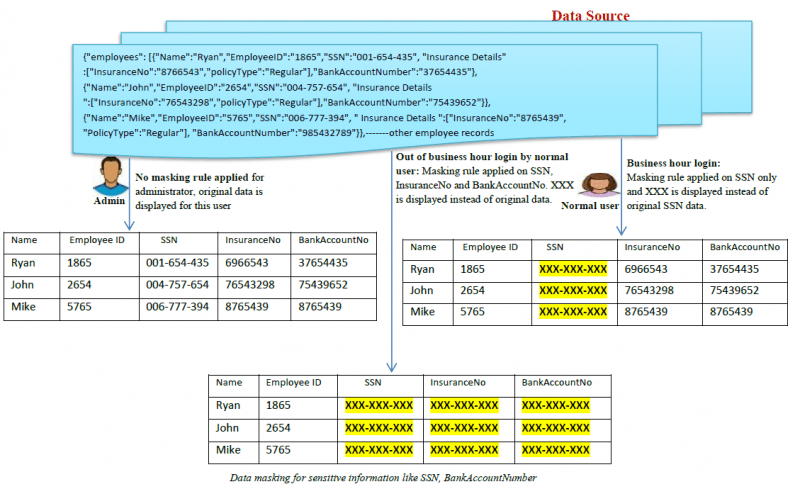
Jakie są rodzaje maskowania danych?
- Statyczne maskowanie danych (SDM): W SDM dane są maskowane w oryginalnej bazie danych, a następnie duplikowane do środowiska testowego, dzięki czemu przedsiębiorstwa mogą udostępniać środowisko danych testowych zewnętrznym sprzedawcom.
- Dynamiczne maskowanie danych (DDM): W DDM nie ma potrzeby stosowania drugiego źródła danych, aby dynamicznie przechowywać zamaskowane dane. Oryginalne dane wrażliwe pozostają w repozytorium i są dostępne dla
aplikacji, gdy są autoryzowane przez system. Dane nigdy nie są wystawione na działanie nieautoryzowanych użytkowników, zawartość jest tasowana w czasie rzeczywistym na żądanie, aby zamaskować zawartość. Tylko autoryzowani użytkownicy są w stanie zobaczyć autentyczne dane. Odwrotne proxy jest zwykle używane do osiągnięcia DDM. Inne dynamiczne metody osiągania DDM są ogólnie nazywane maskowaniem danych w locie.
Jakie są techniki maskowania danych?
Istnieje wiele technik maskowania danych i sklasyfikowaliśmy je zgodnie z ich zastosowaniem.
Odpowiednie do zarządzania danymi testowymi
Zastępowanie
W podejściu zastępowania, jak sama nazwa wskazuje, firmy zastępują oryginalne dane losowymi danymi z dostarczonego lub dostosowanego pliku lookup. Jest to skuteczny sposób maskowania danych, ponieważ firmy zachowują autentyczny wygląd danych.
Shuffling
Shuffling jest kolejną powszechną metodą maskowania danych. W metodzie tasowania, podobnie jak w przypadku zastępowania, firmy zastępują oryginalne dane innymi autentycznie wyglądającymi danymi, ale losowo tasują podmioty w tej samej kolumnie.
Wariantyzacja liczb i dat
W przypadku zbiorów danych finansowych i opartych na datach zastosowanie tej samej wariancji do utworzenia nowego zbioru danych nie zmienia dokładności zbioru danych podczas maskowania danych. Używanie wariancji do tworzenia nowego zbioru danych jest również powszechnie stosowane w generowaniu danych syntetycznych. Jeśli planujesz chronić prywatność danych za pomocą tej techniki, zalecamy zapoznanie się z naszym obszernym przewodnikiem po generowaniu danych syntetycznych.
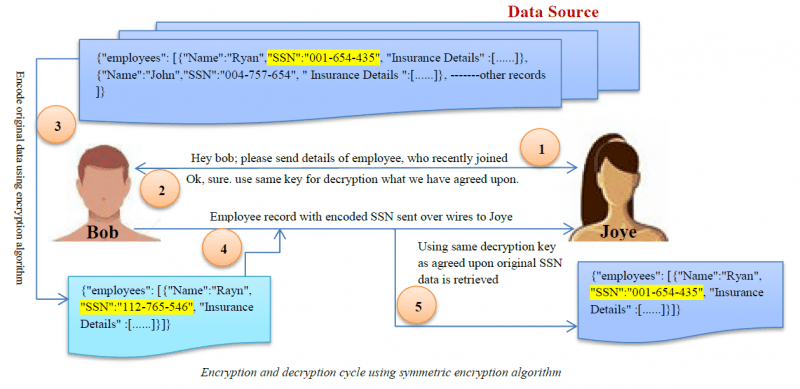
Szyfrowanie
Szyfrowanie jest najbardziej złożonym algorytmem maskowania danych. Użytkownicy mogą uzyskać dostęp do danych tylko wtedy, gdy posiadają klucz deszyfrujący.
Character Scrambling
Metoda ta polega na losowej zmianie kolejności znaków. Proces ten jest nieodwracalny, więc oryginalne dane nie mogą być uzyskane z zakodowanych danych.
Nadaje się do udostępniania danych nieautoryzowanym użytkownikom
Unicestwianie lub usuwanie
Zastąpienie wrażliwych danych wartością null jest również podejściem, które firmy mogą preferować w swoich wysiłkach maskowania danych. Chociaż zmniejsza dokładność wyników testowania, które są w większości zachowane w innych podejściach, jest to prostsze podejście, gdy firmy nie maskują z powodu celów walidacji modelu.
Masking out
W metodzie maskowania, tylko część oryginalnych danych jest maskowana. Jest to podobne do nulling out, ponieważ nie jest skuteczne w środowisku testowym. Na przykład, w zakupach online, tylko ostatnie 4 cyfry numeru karty kredytowej są pokazywane klientom, aby zapobiec oszustwom.
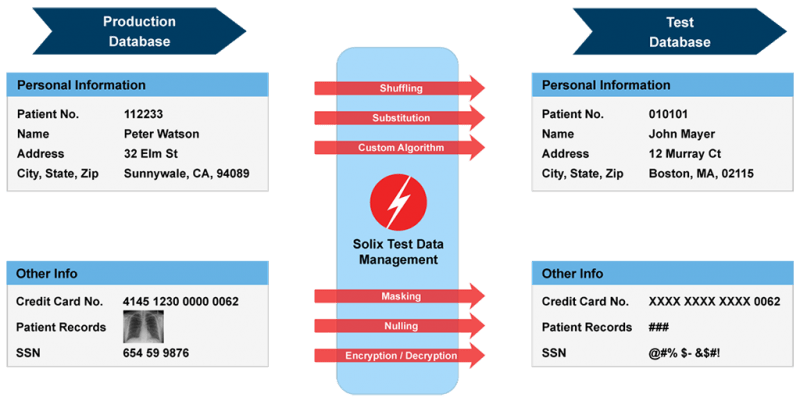
Źródło: Solix Technologies
Czym różni się maskowanie danych od danych syntetycznych?

Do tworzenia danych testowych zgodnych z regulacjami GDPR organizacje mają dwie opcje: generowanie danych syntetycznych lub maskowanie danych za pomocą różnych algorytmów. Chociaż te dwie techniki testowania służą do tego samego celu, każda z metod ma inne korzyści i zagrożenia.
Maskowanie danych to proces tworzenia kopii danych rzeczywistych, które są zasłonięte w określonych polach w zbiorze danych. Jednakże, nawet jeśli organizacja stosuje najbardziej złożone i kompleksowe techniki maskowania danych, istnieje niewielka szansa, że ktoś może zidentyfikować poszczególne osoby na podstawie trendów w zamaskowanych danych. W związku z tym istnieje ryzyko ujawnienia informacji osobom trzecim.
Z drugiej strony, dane syntetyczne to dane, które są sztucznie tworzone, a nie generowane przez rzeczywiste zdarzenia. Nie zawierają one prawdziwych informacji o osobach, są tworzone w oparciu o model danych lub modele wiadomości, które firma wykorzystuje w swoich systemach produkcyjnych. W przypadkach, gdy firma testuje zupełnie nową aplikację lub uważa, że jej maskowanie danych nie jest wystarczające, rozwiązaniem jest użycie danych syntetycznych.
Jakie typy danych wymagają maskowania danych?
- Informacje umożliwiające identyfikację osób (PII): Wszelkie dane, które mogą być potencjalnie wykorzystane do identyfikacji konkretnej osoby. Na przykład pełne imię i nazwisko, numer ubezpieczenia społecznego, numer prawa jazdy i numer paszportu.
- Chronione informacje zdrowotne (PHI): PHI obejmuje informacje demograficzne, historie medyczne, wyniki badań i laboratoriów, warunki zdrowia psychicznego, informacje o ubezpieczeniu i inne dane, które pracownik służby zdrowia gromadzi w celu określenia odpowiedniej opieki.
- Informacje o kartach płatniczych (PCI-DSS): Istnieje standard bezpieczeństwa informacji, którego organizacje muszą przestrzegać podczas obsługi markowych kart kredytowych z głównych systemów kartowych.
- Własność intelektualna (IP): IP odnosi się do wytworów umysłu, takich jak wynalazki; dzieła literackie i artystyczne; projekty; oraz symbole, nazwy i obrazy wykorzystywane w handlu.
W jaki sposób GDPR promuje maskowanie danych?
Maskowanie danych jest akceptowane jako technika ochrony danych osób fizycznych przez GDPR. Oto powiązane artykuły, w których GDPR zachęca przedsiębiorstwa do stosowania pseudonimizacji:
Artykuł 6 (4-e): ” istnienie odpowiednich zabezpieczeń, które mogą obejmować szyfrowanie lub pseudonimizację.”
Artykuł 25 (1): „Uwzględniając stan wiedzy technicznej, koszt wdrażania oraz charakter, zakres, kontekst i cele przetwarzania, a także ryzyko o różnym prawdopodobieństwie wystąpienia i wadze dla praw i wolności osób fizycznych, jakie niesie ze sobą przetwarzanie, administrator – zarówno w momencie ustalania środków przetwarzania, jak i w momencie samego przetwarzania, wdraża odpowiednie środki techniczne i organizacyjne, takie jak pseudonimizacja, które służą skutecznemu wdrożeniu zasad ochrony danych, takich jak minimalizacja danych, oraz integracji niezbędnych zabezpieczeń w procesie przetwarzania w celu spełnienia wymogów niniejszego rozporządzenia i ochrony praw osób, których dane dotyczą”
Art. 32 (a): „Administrator i podmiot przetwarzający wdrażają odpowiednie środki techniczne i organizacyjne, aby zapewnić poziom bezpieczeństwa stosowny do ryzyka, w tym między innymi w stosownych przypadkach: pseudonimizację i szyfrowanie danych osobowych.”
Art. 40 (2): „Stowarzyszenia i inne podmioty reprezentujące kategorie administratorów lub podmiotów przetwarzających mogą przygotowywać kodeksy postępowania, zmieniać lub rozszerzać takie kodeksy, w celu określenia stosowania niniejszego rozporządzenia, np. w odniesieniu do:
- (d) pseudonimizacji danych osobowych
Artykuł 89 (1): „Przetwarzanie do celów archiwizacyjnych w interesie publicznym, do celów badań naukowych lub historycznych lub do celów statystycznych, podlega odpowiednim zabezpieczeniom, w tym minimalizacji danych i pseudonimizacji”
Jakie są przykładowe studia przypadków maskowania danych?
Independence Health Group
Independence Health Group jest wiodącą firmą ubezpieczeń zdrowotnych, która oferuje szeroki zakres usług, w tym komercyjne, Medicare i Medicaid pokrycie medyczne, administrację świadczeń stron trzecich, zarządzanie świadczeniami farmaceutycznymi i odszkodowania pracownicze. Independence Health chciało umożliwić programistom on- i off-shore testowanie aplikacji przy użyciu rzeczywistych danych, jednak potrzebowali zamaskować PHI i inne informacje umożliwiające identyfikację osób. Zdecydowano się na wykorzystanie rozwiązania Informatica Dynamic Data Masking do maskowania nazwisk członków, dat urodzenia, numerów ubezpieczenia społecznego (SSN) i innych wrażliwych danych w czasie rzeczywistym, gdy programiści pobierają zbiory danych.
Dzięki rozwiązaniu do maskowania danych, Independence Health jest w stanie lepiej chronić wrażliwe dane klientów, co zmniejsza potencjalne koszty naruszenia danych.
Samsung
Samsung pracuje nad analizą i produkcją produktów mobilnych i inteligentnych telewizorów na całym świecie. Podczas przeprowadzania analizy produktów na milionach urządzeń Samsung Galaxy Smartphone, firma musi chronić prywatne dane osobowe zgodnie z zasadami i procedurami lokalnych regulacji.
Aby zapewnić zgodność z prawem w zakresie prywatności osób, Samsung nawiązał współpracę z Dataguise. Narzędzie Dataguise dla Hadoop automatycznie odkrywa dane dotyczące prywatności konsumentów i szyfruje je przed migracją danych do narzędzi analitycznych AWS, aby tylko autoryzowani użytkownicy mieli dostęp i mogli wykonywać analizy na danych rzeczywistych.
Jakie są najlepsze praktyki maskowania danych?
- Upewnij się, że odkryłeś wszystkie wrażliwe dane w bazie danych przedsiębiorstwa przed przeniesieniem jej do środowiska testowego.
- Zrozum wrażliwe dane i odpowiednio zidentyfikuj najbardziej odpowiednią technikę maskowania danych.
- Użyj nieodwracalnych metod, aby dane nie mogły zostać przekształcone z powrotem do oryginalnej wersji.
Jakie są wiodące narzędzia maskowania danych?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (for DDM)
- Informatica Persistent Data Masking (for SDM)
- Mentis
- Oracle Advanced Security (for DDM)
- Oracle’s Data Masking and Subsetting Pack (for SDM)
- Privacy Analytics
- Solix Data Masking
Jeśli są Państwo zainteresowani innymi rozwiązaniami zabezpieczającymi w celu ochrony danych przedsiębiorstwa przed cyberzagrożeniami, poniżej znajduje się lista zalecanych lektur:
- Endpoint Security: in-Depth Guide
- The Ultimate Guide to Cyber Threat Intelligence (CTI)
- AI Security: Obrona przed cyberatakami napędzanymi przez AI
- Managed Security Services (MSS): Comprehensive Guide
- Security Analytics: Ostateczny przewodnik
- Technologia podstępu: dogłębny przewodnik