Viste le crescenti minacce informatiche e l’implementazione della legislazione sulla privacy dei dati come il GDPR nell’UE o il CCPA negli Stati Uniti, le aziende devono garantire che i dati privati siano utilizzati il meno possibile. Il mascheramento dei dati fornisce un modo per limitare l’uso dei dati privati, consentendo al contempo alle aziende di testare i loro sistemi con dati che sono il più possibile vicini ai dati reali.
Il costo medio di una violazione dei dati è stato di 4 milioni di dollari nel 2019. Questo crea un forte incentivo per le aziende a investire in soluzioni di sicurezza delle informazioni tra cui il data masking per proteggere i dati sensibili. Il mascheramento dei dati è una soluzione indispensabile per le organizzazioni che desiderano rispettare il GDPR o utilizzare dati realistici in un ambiente di test.
- Che cos’è il mascheramento dei dati?
- Perché il mascheramento dei dati è importante ora?
- Come funziona il mascheramento dei dati?
- Quali sono i tipi di mascheramento dei dati?
- Quali sono le tecniche di mascheramento dei dati?
- Adatto alla gestione dei dati di test
- Sostituzione
- Shuffling
- Varianza di numeri e date
- Crittografia
- Character Scrambling
- Adatto per la condivisione di dati con utenti non autorizzati
- Nulling out o Deletion
- Mascheratura fuori
- In che modo il mascheramento dei dati è diverso dai dati sintetici?
- Quali tipi di dati richiedono il mascheramento dei dati?
- Come il GDPR promuove il mascheramento dei dati?
- Quali sono alcuni esempi di casi di studio di mascheramento dei dati?
- Independence Health Group
- Samsung
- Quali sono le migliori pratiche di mascheramento dei dati?
- Quali sono i principali strumenti di mascheramento dei dati?
Che cos’è il mascheramento dei dati?
Il mascheramento dei dati viene anche chiamato offuscamento dei dati, anonimizzazione dei dati o pseudonimizzazione. È il processo di sostituzione dei dati riservati utilizzando dati fittizi funzionali come caratteri o altri dati. Lo scopo principale del mascheramento dei dati è quello di proteggere le informazioni sensibili e private in situazioni in cui l’impresa condivide i dati con terze parti.
Perché il mascheramento dei dati è importante ora?
Il numero di violazioni dei dati sta aumentando ogni anno (Rispetto alla metà dell’anno 2018, il numero di violazioni registrate è aumentato del 54% nel 2019) Pertanto, le organizzazioni devono migliorare i loro sistemi di sicurezza dei dati. La necessità di mascherare i dati sta aumentando a causa dei seguenti motivi:
- Le organizzazioni hanno bisogno di una copia dei dati di produzione quando decidono di usarli per motivi non produttivi come il test delle applicazioni o la modellazione delle analisi aziendali.
- La politica sulla privacy dei dati dell’impresa è minacciata anche dagli insider. Pertanto le organizzazioni dovrebbero comunque fare attenzione mentre consentono l’accesso ai dipendenti insider. Secondo il sondaggio 2019 Insider Data Breach,
- il 79% dei CIO ritiene che i dipendenti abbiano messo a rischio i dati aziendali accidentalmente negli ultimi 12 mesi, mentre il 61% pensa che i dipendenti abbiano messo a rischio i dati aziendali in modo malevolo.
- Il 95% riconosce che le minacce interne alla sicurezza sono un pericolo per la propria organizzazione
- GDPR e CCPA obbligano le aziende a rafforzare i propri sistemi di protezione dei dati, altrimenti le organizzazioni devono pagare multe salate.
Come funziona il mascheramento dei dati?
Il processo di mascheramento dei dati è semplice, ma ha diverse tecniche e tipi. In generale, le organizzazioni iniziano con l’identificazione di tutti i dati sensibili dell’azienda. Poi, usano algoritmi per mascherare i dati sensibili e sostituirli con dati strutturalmente identici ma numericamente diversi. Cosa intendiamo per strutturalmente identici? Per esempio, i numeri di passaporto sono di 9 cifre negli Stati Uniti e gli individui di solito devono condividere le informazioni del loro passaporto con le compagnie aeree. Quando una compagnia aerea costruisce un modello per analizzare e testare l’ambiente aziendale, crea un diverso ID del passaporto lungo 9 cifre o sostituisce alcune cifre con dei caratteri.
Ecco un esempio di come funziona il mascheramento dei dati:
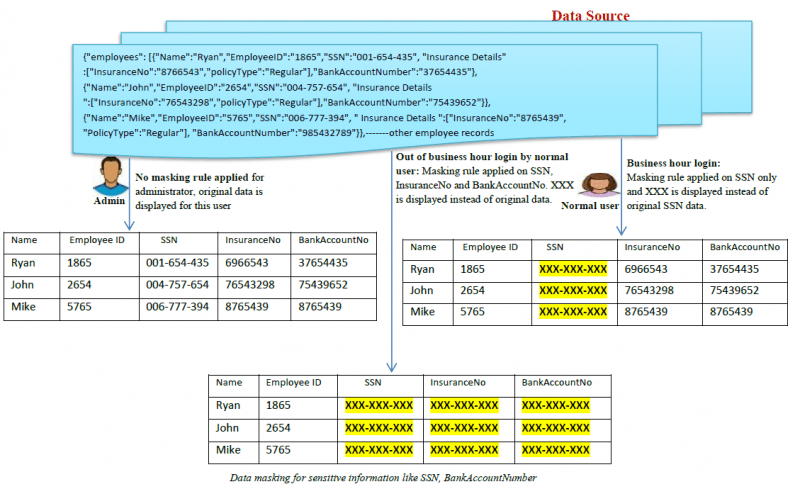
Quali sono i tipi di mascheramento dei dati?
- Mascheramento statico dei dati (SDM): In SDM, i dati sono mascherati nel database originale e poi duplicati in un ambiente di prova in modo che le aziende possano condividere l’ambiente di dati di prova con fornitori terzi.
- Mascheramento dinamico dei dati (DDM): Nel DDM, non c’è bisogno di una seconda fonte di dati per memorizzare i dati mascherati dinamicamente. I dati sensibili originali rimangono nel repository e sono accessibili a un
applicazione quando sono autorizzati dal sistema. I dati non sono mai esposti a utenti non autorizzati, i contenuti sono mescolati in tempo reale su richiesta per rendere i contenuti mascherati. Solo gli utenti autorizzati possono vedere i dati autentici. Un reverse proxy è generalmente utilizzato per ottenere il DDM. Altri metodi dinamici per ottenere il DDM sono generalmente chiamati mascheramento dei dati on-the-fly.
Quali sono le tecniche di mascheramento dei dati?
Ci sono numerose tecniche di mascheramento dei dati e le abbiamo classificate in base al loro caso d’uso.
Adatto alla gestione dei dati di test
Sostituzione
Nell’approccio di sostituzione, come si riferisce il nome, le aziende sostituiscono i dati originali con dati casuali da un file di ricerca fornito o personalizzato. Questo è un modo efficace per mascherare i dati poiché le aziende conservano l’aspetto autentico dei dati.
Shuffling
Shuffling è un altro metodo comune di mascheramento dei dati. Nel metodo shuffling, proprio come la sostituzione, le aziende sostituiscono i dati originali con un altro dall’aspetto autentico, ma mischiano le entità nella stessa colonna in modo casuale.
Varianza di numeri e date
Per i set di dati finanziari e di date, applicare la stessa varianza per creare un nuovo set di dati non cambia la precisione del set di dati mentre si mascherano i dati. L’uso della varianza per creare un nuovo set di dati è anche comunemente usato nella generazione di dati sintetici. Se hai intenzione di proteggere la privacy dei dati con questa tecnica, ti consigliamo di leggere la nostra guida completa alla generazione di dati sintetici.
Crittografia
La crittografia è l’algoritmo di mascheramento dei dati più complesso. Gli utenti possono accedere ai dati solo se hanno la chiave di decrittazione.
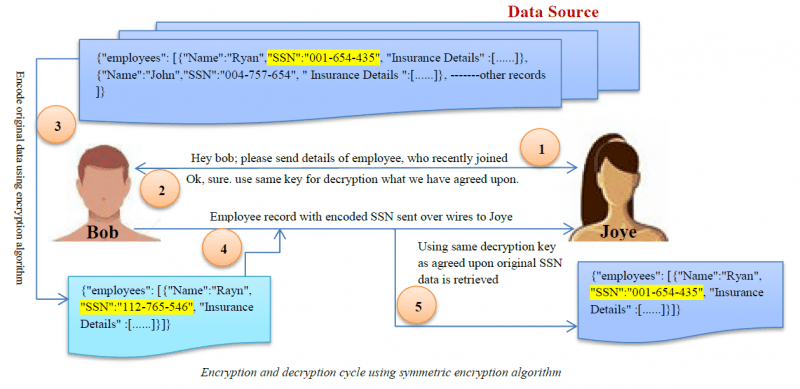
Character Scrambling
Questo metodo comporta la riorganizzazione casuale dell’ordine dei caratteri. Questo processo è irreversibile in modo che i dati originali non possano essere ottenuti dai dati criptati.
Adatto per la condivisione di dati con utenti non autorizzati
Nulling out o Deletion
La sostituzione di dati sensibili con valori nulli è anche un approccio che le aziende possono preferire nei loro sforzi di mascheratura dei dati. Anche se riduce l’accuratezza dei risultati dei test che sono per lo più mantenuti in altri approcci, è un approccio più semplice quando le aziende non stanno mascherando a causa di scopi di convalida del modello.
Mascheratura fuori
Nel metodo di mascheratura fuori, solo una parte dei dati originali è mascherata. È simile al nulling out poiché non è efficace nell’ambiente di prova. Per esempio, nello shopping online, solo le ultime 4 cifre del numero di carta di credito vengono mostrate ai clienti per prevenire le frodi.
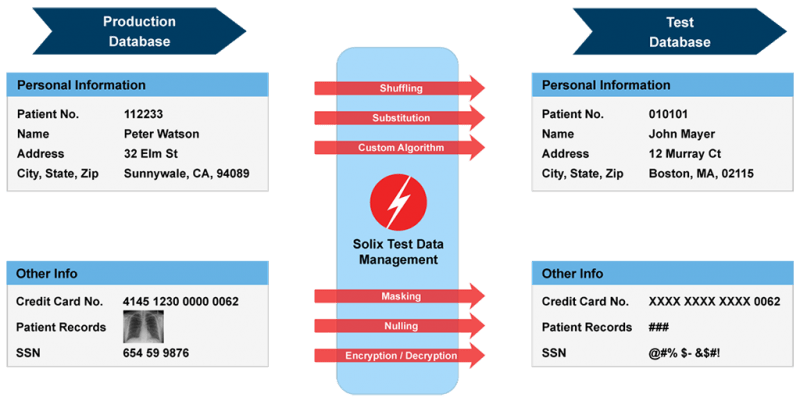
Fonte: Solix Technologies
In che modo il mascheramento dei dati è diverso dai dati sintetici?

Per creare dati di test conformi alle normative GDPR, le organizzazioni hanno due opzioni: generare dati sintetici o mascherare i dati con diversi algoritmi. Anche se queste due tecniche di test servono allo stesso scopo, ogni metodo ha benefici e rischi diversi.
Il mascheramento dei dati è il processo di creazione di una copia dei dati del mondo reale che viene oscurata in campi specifici all’interno di un set di dati. Tuttavia, anche se l’organizzazione applica le tecniche di mascheramento dei dati più complesse e complete, c’è una piccola possibilità che qualcuno possa identificare le singole persone sulla base delle tendenze nei dati mascherati. Pertanto, c’è il rischio di rilasciare informazioni a terzi.
Dall’altro lato, i dati sintetici sono dati che vengono creati artificialmente piuttosto che essere generati da eventi reali. Non contengono informazioni reali sugli individui, sono creati sulla base del modello di dati o dei modelli di messaggi che un’azienda utilizza per i suoi sistemi di produzione. Nei casi in cui un’azienda sta testando un’applicazione completamente nuova o ritiene che il mascheramento dei dati non sia sufficiente, l’utilizzo di dati sintetici è la risposta.
Quali tipi di dati richiedono il mascheramento dei dati?
- Informazioni personali identificabili (PII): Qualsiasi dato che potrebbe potenzialmente essere usato per identificare una particolare persona. Per esempio, nome e cognome, numero di previdenza sociale, numero di patente e numero di passaporto.
- Informazioni sanitarie protette (PHI): PHI include informazioni demografiche, storie mediche, test e risultati di laboratorio, condizioni di salute mentale, informazioni assicurative e altri dati che un operatore sanitario raccoglie per identificare le cure appropriate.
- Informazioni sulle carte di pagamento (PCI-DSS): C’è uno standard di sicurezza delle informazioni che le organizzazioni devono seguire nella gestione delle carte di credito di marca dei principali schemi di carte.
- Proprietà intellettuale (IP): IP si riferisce alle creazioni della mente, come invenzioni, opere letterarie e artistiche, disegni e simboli, nomi e immagini utilizzati nel commercio.
Come il GDPR promuove il mascheramento dei dati?
Il data masking è accettato come una tecnica per proteggere i dati degli individui dal GDPR. Ecco gli articoli correlati in cui il GDPR incoraggia le aziende a utilizzare la pseudonimizzazione:
Articolo 6 (4-e): “L’esistenza di garanzie adeguate, che possono includere la crittografia o la pseudonimizzazione.”
Articolo 25 (1): “Tenendo conto dello stato dell’arte, dei costi di attuazione e della natura, dell’ambito di applicazione, del contesto e delle finalità del trattamento, nonché dei rischi di varia probabilità e gravità per i diritti e le libertà delle persone fisiche che il trattamento comporta, il responsabile del trattamento deve, sia al momento della determinazione dei mezzi di trattamento che al momento del trattamento stesso attuare misure tecniche e organizzative adeguate, come la pseudonimizzazione, volte ad attuare in modo efficace i principi di protezione dei dati, come la minimizzazione dei dati, e ad integrare nel trattamento le garanzie necessarie per soddisfare i requisiti del presente regolamento e tutelare i diritti degli interessati”
Articolo 32 (a): “Il responsabile del trattamento e l’incaricato del trattamento attuano misure tecniche e organizzative adeguate per garantire un livello di sicurezza appropriato al rischio, compresi, tra l’altro, se del caso: la pseudonimizzazione e la cifratura dei dati personali.”
Articolo 40 (2): “Le associazioni e gli altri organismi che rappresentano categorie di responsabili del trattamento o di incaricati del trattamento possono elaborare codici di condotta, oppure modificarli o ampliarli, allo scopo di precisare l’applicazione del presente regolamento, ad esempio per quanto riguarda:
- (d) la pseudonimizzazione dei dati personali
Articolo 89 (1): “Il trattamento a fini di archiviazione nel pubblico interesse, a fini di ricerca scientifica o storica o a fini statistici, è soggetto ad adeguate garanzie, comprese la minimizzazione dei dati e la pseudonimizzazione”
Quali sono alcuni esempi di casi di studio di mascheramento dei dati?
Independence Health Group
Independence Health Group è la principale compagnia di assicurazione sanitaria che offre una vasta gamma di servizi tra cui copertura medica commerciale, Medicare e Medicaid, amministrazione di benefici per terzi, gestione dei benefici farmaceutici e compensazione dei lavoratori. Independence Health voleva consentire agli sviluppatori on-shore e off-shore di testare le applicazioni utilizzando dati reali, tuttavia, avevano bisogno di mascherare PHI e altre informazioni di identificazione personale. Hanno deciso di utilizzare Informatica Dynamic Data Masking per mascherare i nomi dei membri, le date di nascita, i numeri di previdenza sociale (SSN) e altri dati sensibili in tempo reale mentre gli sviluppatori tirano giù i set di dati.
Con una soluzione di mascheramento dei dati, Independence Health è in grado di proteggere meglio i dati sensibili dei clienti, riducendo il costo potenziale di una violazione dei dati.
Samsung
Samsung sta lavorando all’analisi e alla produzione di prodotti mobili e smart TV in tutto il mondo. Mentre esegue l’analisi dei prodotti su milioni di dispositivi Samsung Galaxy Smartphone, l’azienda deve proteggere le informazioni private personali in conformità con le regole e le procedure del regolamento locale.
Per garantire la conformità legale alla privacy personale, Samsung ha collaborato con Dataguise. Lo strumento di Dataguise per Hadoop scopre automaticamente i dati sulla privacy dei consumatori e li cripta prima di migrare i dati verso gli strumenti di analisi AWS, in modo che solo gli utenti autorizzati possano accedere ed eseguire analisi sui dati reali.
Quali sono le migliori pratiche di mascheramento dei dati?
- Assicurati di aver scoperto tutti i dati sensibili nel database aziendale prima di trasferirli nell’ambiente di test.
- Comprendi i tuoi dati sensibili e identifica la tecnica di mascheramento dei dati più adatta di conseguenza.
- Usa metodi irreversibili in modo che i tuoi dati non possano essere ritrasformati nella versione originale.
Quali sono i principali strumenti di mascheramento dei dati?
- CA Test Data Manager
- Piattaforma Dataguise Privacy on Demand
- Delphix Dynamic Data Platform
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camouflage Data Masking
- Informatica Dynamic Data Masking (per DDM)
- Informatica Persistent Data Masking (per SDM)
- Mentis
- Oracle Advanced Security (per DDM)
- Oracle’s Data Masking and Subsetting Pack (per SDM)
- Privacy Analytics
- Solix Data Masking
Se siete interessati ad altre soluzioni di sicurezza per proteggere i dati aziendali dalle minacce informatiche, qui sotto c’è una lista di letture consigliate per voi:
- Sicurezza endpoint: guida approfondita
- La guida definitiva alla Cyber Threat Intelligence (CTI)
- AI Security: Difendersi dai cyberattacchi AI
- Managed Security Services (MSS): Guida completa
- Security Analytics: La guida definitiva
- Tecnologia dell’inganno: Guida approfondita