
Chce vaše organizace agregovat a analyzovat data, aby zjistila trendy, ale způsobem, který chrání soukromí? Nebo možná již používáte diferenční nástroje pro ochranu soukromí, ale chcete rozšířit (nebo sdílet) své znalosti? V obou případech je tento seriál blogů určen právě vám.
Proč děláme tento seriál? V loňském roce NIST spustil prostor pro spolupráci v oblasti inženýrství ochrany soukromí s cílem shromáždit nástroje, řešení a procesy s otevřeným zdrojovým kódem, které podporují inženýrství ochrany soukromí a řízení rizik. Jako moderátoři pro Collaboration Space jsme pomohli NIST shromáždit diferencované nástroje pro ochranu soukromí v rámci tematické oblasti deidentifikace. NIST také zveřejnil rámec pro ochranu soukromí: A Tool for Improving Privacy through Enterprise Risk Management a doprovodný plán, který rozpoznal řadu problémových oblastí ochrany soukromí, včetně tématu deidentifikace. Nyní bychom rádi využili prostor pro spolupráci, abychom pomohli zaplnit mezeru v cestovní mapě týkající se deidentifikace. Naším konečným cílem je podpořit NIST v tom, aby se tato série proměnila v podrobnější pokyny týkající se diferenciace soukromí.
Každý příspěvek bude začínat koncepčními základy a praktickými případy použití, jejichž cílem je pomoci odborníkům, jako jsou vlastníci podnikových procesů nebo pracovníci programů ochrany soukromí, naučit se právě tolik, aby to bylo nebezpečné (jen žertuji). Po pokrytí základů se podíváme na dostupné nástroje a jejich technické přístupy pro inženýry ochrany soukromí nebo IT profesionály, kteří se zajímají o podrobnosti implementace. Abychom všechny uvedli do problematiky, poskytne tento první příspěvek základní informace o diferencované ochraně osobních údajů a popíše některé klíčové pojmy, které budeme používat ve zbytku seriálu.
Problém
Jak můžeme použít data k získání informací o populaci, aniž bychom se dozvěděli o konkrétních osobách v rámci této populace? Uvažujme tyto dvě otázky:
- „Kolik lidí žije ve Vermontu?“
- „Kolik lidí jménem Joe Near žije ve Vermontu?“
První odhaluje vlastnost celé populace, zatímco druhá odhaluje informace o jedné osobě. Potřebujeme mít možnost dozvědět se o trendech v populaci a zároveň zabránit možnosti dozvědět se něco nového o konkrétní osobě. To je cílem mnoha statistických analýz dat, například statistik zveřejňovaných americkým úřadem pro sčítání lidu, a obecněji strojového učení. V každém z těchto prostředí mají modely odhalovat trendy v populaci, nikoliv odrážet informace o nějakém jednotlivci.
Ale jak můžeme odpovědět na první otázku „Kolik lidí žije ve Vermontu?“? – kterou budeme označovat jako dotaz – a zároveň zabránit tomu, aby byla zodpovězena druhá otázka „Kolik lidí jménem Joe Near žije ve Vermontu?“. Nejpoužívanějším řešením je tzv. deidentifikace (nebo anonymizace), která ze souboru dat odstraní identifikační informace. (Obecně budeme předpokládat, že soubor dat obsahuje informace shromážděné od mnoha jednotlivců). Další možností je povolit pouze souhrnné dotazy, například průměr z dat. Bohužel nyní chápeme, že ani jeden z těchto přístupů ve skutečnosti neposkytuje silnou ochranu soukromí. Soubory dat s odstraněnou identifikací jsou předmětem útoků na propojení s databází. Agregace chrání soukromí pouze v případě, že agregované skupiny jsou dostatečně velké, a i tehdy jsou útoky na soukromí možné .
Diferencované soukromí
Diferencované soukromí je matematická definice toho, co znamená mít soukromí. Nejedná se o konkrétní proces, jako je deidentifikace, ale o vlastnost, kterou proces může mít. Například je možné dokázat, že určitý algoritmus „splňuje“ diferenciální soukromí.
Informativně diferenciální soukromí zaručuje každému jednotlivci, který přispívá daty k analýze, následující: výstup diferenciálně soukromé analýzy bude zhruba stejný, ať už přispějete svými daty, nebo ne. Diferenciálně soukromá analýza se často nazývá mechanismus a označujeme ji ℳ.
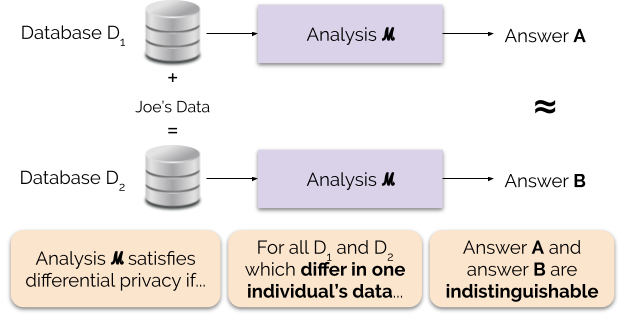
Obrázek 1 ilustruje tento princip. Odpověď „A“ je vypočtena bez Joeových údajů, zatímco odpověď „B“ je vypočtena s Joeovými údaji. Diferenciální soukromí říká, že obě odpovědi by měly být nerozlišitelné. To znamená, že ten, kdo uvidí výstup, nebude schopen zjistit, zda byla použita Joeova data nebo co Joeova data obsahovala.
Sílu záruky soukromí řídíme nastavením parametru soukromí ε, kterému se také říká ztráta soukromí nebo rozpočet soukromí. Čím nižší je hodnota parametru ε, tím nerozlišitelnější jsou výsledky, a tedy tím více jsou chráněna data každého jednotlivce.
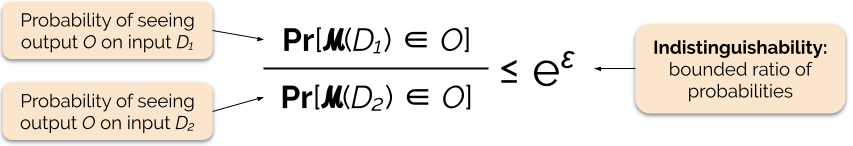
Často můžeme odpovědět na dotaz s diferenciálním soukromím tak, že k odpovědi na dotaz přidáme určitý náhodný šum. Problém spočívá v určení, kam šum přidat a kolik ho přidat. Jedním z nejčastěji používaných mechanismů pro přidávání šumu je Laplaceův mechanismus .
Dotazy s vyšší citlivostí vyžadují přidání většího šumu, aby byla splněna určitá `epsilonová` veličina diferenciálního soukromí, a tento dodatečný šum má potenciál učinit výsledky méně užitečnými. Citlivost a tento kompromis mezi soukromím a užitečností podrobněji popíšeme v budoucích příspěvcích na blogu.
Výhody diferenciálního soukromí
Diferenciální soukromí má oproti předchozím technikám ochrany soukromí několik důležitých výhod:
- Předpokládá, že všechny informace jsou identifikační informace, čímž odpadá náročný (a někdy nemožný) úkol zohlednit všechny identifikační prvky dat.
- Je odolná vůči útokům na soukromí založeným na pomocných informacích, takže může účinně zabránit útokům na propojení, které jsou možné u deidentifikovaných dat.
- Je kompoziční – ztrátu soukromí při provádění dvou diferenciálně soukromých analýz na stejných datech můžeme určit prostým sečtením jednotlivých ztrát soukromí pro obě analýzy. Kompozičnost znamená, že můžeme poskytnout smysluplné záruky ohledně soukromí i při zveřejnění výsledků více analýz ze stejných dat. Techniky, jako je deidentifikace, nejsou kompoziční a vícenásobné zveřejnění podle těchto technik může vést ke katastrofální ztrátě soukromí.
Tyto výhody jsou hlavními důvody, proč by si odborník mohl zvolit diferenciální ochranu soukromí místo některé jiné techniky ochrany soukromí dat. Současnou nevýhodou diferenciálního soukromí je, že je poměrně nové a robustní nástroje, standardy a osvědčené postupy nejsou mimo akademické výzkumné komunity snadno dostupné. Předpokládáme však, že toto omezení může být v blízké budoucnosti překonáno díky rostoucí poptávce po robustních a snadno použitelných řešeních pro ochranu soukromí dat.
Příště
Zůstaňte naladěni: náš příští příspěvek naváže na tento a bude se zabývat otázkami bezpečnosti spojenými s nasazením systémů pro diferenciální ochranu soukromí, včetně rozdílu mezi centrálním a lokálním modelem diferenciální ochrany soukromí.
Předtím než odejdeme – chceme, aby tento seriál a následné pokyny NIST přispěly k větší dostupnosti diferenciální ochrany soukromí. Můžete nám pomoci. Ať už máte otázky k těmto příspěvkům, nebo se můžete podělit o své znalosti, doufáme, že se s námi zapojíte, abychom mohli tuto disciplínu společně rozvíjet.
Garfinkel, Simson, John M. Abowd a Christian Martindale. „Porozumění útokům na rekonstrukci databází na veřejných datech“. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea a kol. „When the signal is in the noise: exploiting diffix’s stick noise.“ (Když je signál v šumu: využití lepkavého šumu diffixu). 28th USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit a Kobbi Nissim. „Odhalování informací při zachování soukromí“. Sborník dvacátého druhého sympozia ACM SIGMOD-SIGACT-SIGART o principech databázových systémů. 2003.
Sweeney, Latanya. „Jednoduché demografické údaje často jedinečně identifikují lidi.“ Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. „Calibrating noise to sensitivity in private data analysis“. Konference o teorii kryptografie. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke a Salil Vadhan. „Differential privacy: A primer for a non-technical audience.“ (Základní informace pro netechnické publikum). Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia a Aaron Roth. „Algoritmické základy diferenciálního soukromí“. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.