Dadas as crescentes ameaças cibernéticas e a implementação de legislação de privacidade de dados como o GDPR na UE ou CCPA nos EUA, as empresas precisam garantir que os dados privados sejam usados o mínimo possível. A máscara de dados fornece uma forma de limitar o uso de dados privados, permitindo às empresas testar seus sistemas com dados o mais próximo possível de dados reais.
O custo médio de uma violação de dados foi de US$4 milhões em 2019. Isto cria um forte incentivo para as empresas investirem em soluções de segurança de informação, incluindo mascaramento de dados para proteger dados sensíveis. A máscara de dados é uma solução obrigatória para organizações que desejam cumprir com a GDPR ou usar dados realistas em um ambiente de teste.
- O que é máscara de dados?
- Por que o mascaramento de dados é importante agora?
- Como funciona o mascaramento de dados?
- Quais são os tipos de mascaramento de dados?
- Quais são as técnicas de máscara de dados?
- Adequadas para gerenciamento de dados de teste
- Substituição
- Mudanças
- Desvio de Número e Data
- Criptação
- Character Scrambling
- Adequado para compartilhar dados com usuários não autorizados
- Desactivação ou Eliminação
- Mascarando para fora
- Como o mascaramento de dados é diferente dos dados sintéticos?
- Que tipos de dados requerem mascaramento de dados?
- Como a GDPR promove o mascaramento de dados?
- Quais são alguns exemplos de estudos de casos de mascaramento de dados?
- Independência Grupo de Saúde
- Samsung
- Quais são as melhores práticas de mascaramento de dados?
- Quais são as principais ferramentas de mascaramento de dados?
O que é máscara de dados?
O mascaramento de dados também é referido como ofuscação de dados, anonimização de dados, ou pseudonimização. É o processo de substituição de dados confidenciais usando dados fictícios funcionais, como personagens ou outros dados. O principal objetivo do mascaramento de dados é proteger informações confidenciais e privadas em situações em que a empresa compartilha dados com terceiros.
Por que o mascaramento de dados é importante agora?
O número de violações de dados está aumentando a cada ano (em comparação com a metade do ano de 2018, o número de violações registradas aumentou 54% em 2019) Portanto, as organizações precisam melhorar seus sistemas de segurança de dados. A necessidade de máscara de dados está aumentando devido às seguintes razões:
- As organizações precisam de uma cópia dos dados de produção quando decidem usá-los por motivos não produtivos, tais como testes de aplicação ou modelagem analítica de negócios.
- A política de privacidade de dados da sua empresa também é ameaçada por pessoas internas. Portanto, as organizações ainda devem ter cuidado ao mesmo tempo em que permitem o acesso a funcionários internos. De acordo com a pesquisa Insider Data Breach de 2019,
- 79% dos CIOs acreditam que os funcionários colocaram os dados da empresa em risco acidentalmente nos últimos 12 meses, enquanto 61% pensam que os funcionários colocaram os dados da empresa em risco de forma maliciosa.
- 95% reconhecem que as ameaças à segurança interna são um perigo para a sua organização
- GDPR e CCPA forçam as empresas a reforçar os seus sistemas de protecção de dados, caso contrário as organizações têm de pagar multas pesadas.
Como funciona o mascaramento de dados?
O processo de mascaramento de dados é simples, no entanto, tem diferentes técnicas e tipos. Em geral, as organizações começam com a identificação de todos os dados sensíveis que a sua empresa possui. Depois, elas usam algoritmos para mascarar dados sensíveis e substituí-los por dados estruturalmente idênticos, mas numericamente diferentes. O que queremos dizer com “estruturalmente idênticos”? Por exemplo, os números de passaporte são 9 dígitos nos EUA e os indivíduos geralmente têm que compartilhar suas informações de passaporte com empresas aéreas. Quando uma companhia aérea constrói um modelo para analisar e testar o ambiente de negócios, eles criam um ID de passaporte diferente com 9 dígitos ou substituem alguns dígitos por caracteres.
Aqui está um exemplo de como o mascaramento de dados funciona:
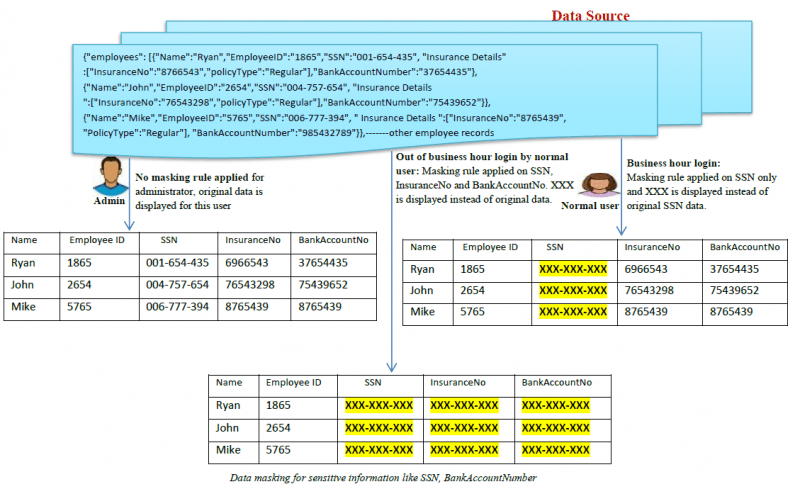
Quais são os tipos de mascaramento de dados?
- Mascaramento estático de dados (SDM): No SDM, os dados são mascarados no banco de dados original e depois duplicados em um ambiente de teste para que as empresas possam compartilhar o ambiente de dados de teste com fornecedores terceiros.
- Mascaramento dinâmico de dados (DDM): No DDM, não há necessidade de uma segunda fonte de dados para armazenar os dados mascarados de forma dinâmica. Os dados sensíveis originais permanecem no repositório e são acessíveis a uma aplicação
quando autorizados pelo sistema. Os dados nunca são expostos a usuários não autorizados, os conteúdos são embaralhados em tempo real sob demanda para que os conteúdos sejam mascarados. Somente usuários autorizados são capazes de ver dados autênticos. Um proxy reverso é geralmente usado para obter o DDM. Outros métodos dinâmicos para alcançar o DDM são geralmente chamados de máscara de dados on-the-fly.
Quais são as técnicas de máscara de dados?
Existem numerosas técnicas de mascaramento de dados e nós as classificamos de acordo com seu caso de uso.
Adequadas para gerenciamento de dados de teste
Substituição
Na abordagem de substituição, como seu nome indica, as empresas substituem os dados originais por dados aleatórios de um arquivo de pesquisa fornecido ou personalizado. Esta é uma forma eficaz de disfarçar dados, uma vez que as empresas preservam a aparência autêntica dos dados.
Mudanças
Mudanças é outro método comum de mascaramento de dados. No método de embaralhamento, assim como a substituição, as empresas substituem os dados originais por outros dados de aparência autêntica, mas embaralham as entidades na mesma coluna aleatoriamente.
Desvio de Número e Data
Para conjuntos de dados financeiros e com data, aplicar o mesmo desvio para criar um novo conjunto de dados não altera a precisão do conjunto de dados enquanto se mascara os dados. Usar o desvio para criar um novo conjunto de dados também é comumente usado na geração de dados sintéticos. Se pretende proteger a privacidade dos dados com esta técnica, recomendamos que leia o nosso guia completo para a geração de dados sintéticos.
Criptação
Criptação é o algoritmo de mascaramento de dados mais complexo. Os utilizadores só podem aceder aos dados se tiverem a chave de desencriptação.
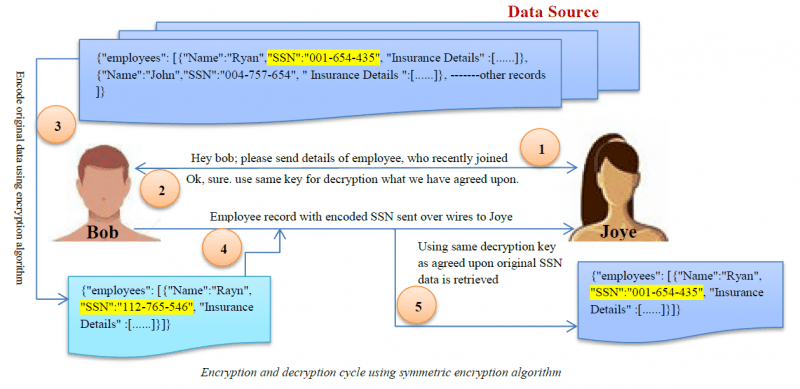
Character Scrambling
Este método envolve a reorganização aleatória da ordem dos caracteres. Este processo é irreversível para que os dados originais não possam ser obtidos a partir dos dados codificados.
>
Adequado para compartilhar dados com usuários não autorizados
Desactivação ou Eliminação
A substituição de dados sensíveis por valor nulo também é uma abordagem que as empresas podem preferir em seus esforços de mascaramento de dados. Embora reduza a precisão dos resultados dos testes, que são mantidos em sua maioria em outras abordagens, é uma abordagem mais simples quando as empresas não estão mascarando devido aos propósitos de validação do modelo.
Mascarando para fora
No método mascarando para fora, apenas alguma parte dos dados originais é mascarada. É semelhante ao nulling out, uma vez que não é eficaz no ambiente de teste. Por exemplo, nas compras on-line, apenas os últimos 4 dígitos do número do cartão de crédito são mostrados aos clientes para evitar fraudes.
>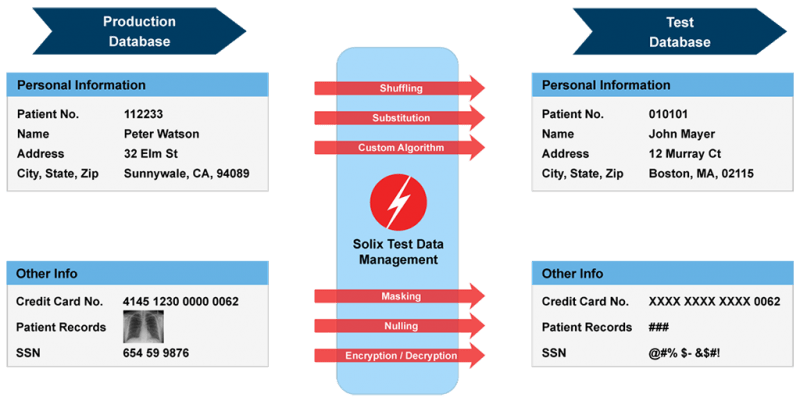
Source: Solix Technologies
Como o mascaramento de dados é diferente dos dados sintéticos?

Para criar dados de teste em conformidade com os regulamentos da GDPR, as organizações têm duas opções: gerar dados sintéticos ou máscara de dados com algoritmos diferentes. Embora estas duas técnicas de teste sirvam para o mesmo propósito, cada método tem diferentes benefícios e riscos.
O mascaramento de dados é o processo de criar uma cópia de dados do mundo real que é obscurecida em campos específicos dentro de um conjunto de dados. Entretanto, mesmo que a organização aplique as mais complexas e abrangentes técnicas de mascaramento de dados, há uma pequena chance de que alguém possa identificar pessoas individuais com base nas tendências dos dados mascarados. Portanto, há o risco de divulgar informações a terceiros.
No outro lado, dados sintéticos são dados criados artificialmente em vez de serem gerados por eventos reais. Ele não contém informações reais sobre indivíduos, ele é criado com base no modelo de dados ou modelos de mensagens que uma empresa utiliza para seus sistemas de produção. Para casos em que uma empresa está testando uma aplicação totalmente nova ou a empresa acredita que o mascaramento de dados não é suficiente, usando dados sintéticos é a resposta.
Que tipos de dados requerem mascaramento de dados?
- Informação pessoalmente identificável (PII): Qualquer dado que possa ser usado para identificar uma determinada pessoa. Por exemplo, nome completo, número da segurança social, número da carteira de motorista e número do passaporte.
- Informação de saúde protegida (PHI): PHI inclui informação demográfica, históricos médicos, resultados de testes e laboratórios, condições de saúde mental, informação sobre seguros, e outros dados que um profissional de saúde recolhe para identificar cuidados apropriados.
- Informação sobre cartão de pagamento (PCI-DSS): Há um padrão de segurança da informação a ser seguido pelas organizações ao lidar com cartões de crédito de marca dos principais esquemas de cartões.
- Propriedade Intelectual (IP): IP refere-se a criações da mente, tais como invenções; obras literárias e artísticas; desenhos; e símbolos, nomes e imagens usados no comércio.
Como a GDPR promove o mascaramento de dados?
O mascaramento de dados é aceito como uma técnica para proteger os dados dos indivíduos pela GDPR. Aqui estão os artigos relacionados onde GDPR incentiva as empresas a usar pseudonímia:
Artigo 6 (4-e): “a existência de salvaguardas apropriadas, que podem incluir criptografia ou pseudonímia”
Artigo 25 (1): “Tendo em conta o estado da técnica, o custo da implementação e a natureza, âmbito, contexto e finalidades do processamento, bem como os riscos de probabilidade e severidade variáveis para os direitos e liberdades das pessoas singulares colocados pelo processamento, o controlador deve, tanto no momento da determinação dos meios para o processamento como no momento do próprio processamento, implementar medidas técnicas e organizacionais adequadas, tais como a pseudonímia, que são concebidas para implementar os princípios de protecção de dados, tais como a minimização de dados, de forma eficaz e para integrar as salvaguardas necessárias no tratamento, a fim de cumprir os requisitos deste Regulamento e proteger os direitos das pessoas em causa”
Artigo 32 (a): “O responsável pelo tratamento e o processador deverão implementar medidas técnicas e organizacionais adequadas para garantir um nível de segurança adequado ao risco, incluindo, entre outros, conforme apropriado: a pseudonímia e a criptografia dos dados pessoais”
Artigo 40 (2): “As associações e outros organismos representativos de categorias de controladores ou processadores podem preparar códigos de conduta, ou alterar ou ampliar tais códigos, com a finalidade de especificar a aplicação deste Regulamento, como no que diz respeito a:
- (d) a pseudonimização de dados pessoais
Artigo 89 (1): “O processamento para fins de arquivamento no interesse público, fins de pesquisa científica ou histórica ou fins estatísticos, estará sujeito a salvaguardas apropriadas, incluindo minimização de dados e pseudonimização”
Quais são alguns exemplos de estudos de casos de mascaramento de dados?
Independência Grupo de Saúde
Independência Grupo de Saúde é a companhia de seguros de saúde líder que está oferecendo uma ampla gama de serviços, incluindo cobertura médica comercial, Medicare e Medicaid, administração de benefícios de terceiros, gestão de benefícios de farmácia e remuneração dos trabalhadores. A Independence Health queria permitir que os programadores on-shore e off-shore testassem aplicações usando dados reais, no entanto, eles precisavam mascarar os PHI e outras informações pessoalmente identificáveis. Eles decidiram usar o Informatica Dynamic Data Masking para disfarçar nomes de membros, datas de nascimento, números de segurança social (SSNs) e outros dados sensíveis em tempo real à medida que os programadores retiram conjuntos de dados.
Com uma solução de mascaramento de dados, a Independence Health é capaz de proteger melhor os dados sensíveis dos clientes, o que reduz o custo potencial de uma violação de dados.
Samsung
Samsung está a trabalhar na análise e produção de produtos de TV móvel e inteligente em todo o mundo. Enquanto realiza análises de produtos em milhões de dispositivos Samsung Galaxy Smartphone, a empresa tem que proteger informações pessoais privadas de acordo com as regras e procedimentos do regulamento local.
Para garantir a conformidade legal com a privacidade pessoal, a Samsung fez uma parceria com a Dataguise. A ferramenta Dataguise para Hadoop descobre automaticamente os dados de privacidade dos consumidores e encripta-os antes de migrar os dados para as ferramentas analíticas AWS para que apenas utilizadores autorizados possam aceder e realizar análises em dados reais.
Quais são as melhores práticas de mascaramento de dados?
>
- Certifique-se de descobrir todos os dados sensíveis no banco de dados da empresa antes de transferi-los para o ambiente de teste.
- Entenda seus dados sensíveis e identifique a técnica de mascaramento de dados mais adequada de acordo.
- Use métodos irreversíveis para que seus dados não possam ser transformados de volta à versão original.
Quais são as principais ferramentas de mascaramento de dados?
- CA Test Data Manager
- Dataguise Privacy on Demand Platform
- Delphix Dynamic Data Plataforma
- HPE SecureData Enterprise
- IBM Infosphere Optim
- Imperva Camuflage Data Masking
- Informatica Dynamic Data Masking (para DDM)
- Informatica Persistent Data Masking (para SDM)
- Mentis
- Oracle Advanced Security (para DDM)
- Oracle’s Data Masking and Subsetting Pack (para SDM)
- Privacy Analytics
- Solix Data Masking
Se estiver interessado em outras soluções de segurança para proteger os dados da sua empresa contra ameaças cibernéticas, abaixo está uma lista de leitura recomendada para você:
- Segurança do Ponto Final: in-Depth Guide
- O Guia Final de Inteligência de Ameaças Cibernéticas (CTI)
- Segurança do ATI: Defenda-se contra ataques cibernéticos alimentados por IA
- Serviços de Segurança Gerenciados (MSS): Guia abrangente
- Security Analytics: The Ultimate Guide
- Tecnologia de Decepção: in-Depth Guide