Locality-sensitive hashing
Doel: Documenten vinden met een Jaccard-soortgelijkheid van minstens t
Het algemene idee van LSH is om een algoritme te vinden dat, als we handtekeningen van 2 documenten invoeren, ons vertelt of die 2 documenten een kandidaat-paar vormen of niet, d.w.z. dat hun overeenkomst groter is dan een drempel t. Vergeet niet dat we de overeenkomst van de handtekeningen beschouwen als een proxy voor de Jaccard-overeenkomst tussen de originele documenten.
Specifiek voor min-hash handtekening matrix:
- Hash kolommen van handtekening matrix M met behulp van verschillende hash functies
- Als 2 documenten hash in dezelfde emmer voor ten minste een van de hash-functie kunnen we de 2 documenten als een kandidaat-paar
Nu is de vraag hoe je verschillende hash-functies te creëren. Hiervoor doen we band partitie.
Bandpartitie

Hier volgt het algoritme:
- Verdel de handtekeningenmatrix in b banden, elke band heeft r rijen
- Voor elke band, hash zijn deel van elke kolom in een hashtabel met k emmers
- Kandidaat-kolom paren zijn die welke in dezelfde emmer hashen voor minstens 1 band
- Stel b en r zo af dat de meeste gelijkende paren worden gevangen maar weinig niet gelijkende paren
Er zijn een paar overwegingen hier. Idealiter willen we voor elke band k gelijk stellen aan alle mogelijke combinaties van waarden die een kolom binnen een band kan aannemen. Dit komt neer op identiteitsvergelijking. Maar op deze manier zal k een enorm getal zijn, hetgeen rekentechnisch niet haalbaar is. Bijvoorbeeld: Als we voor een band 5 rijen hebben. Als de elementen in de handtekening 32 bit gehele getallen zijn, dan zal k in dit geval (2³²)⁵ ~ 1.4615016e+48 zijn. U ziet wat hier het probleem is. Normaal gesproken wordt k rond 1 miljoen genomen.
Het idee is dat als 2 documenten op elkaar lijken, zij als kandidaat-paar in ten minste één van de banden zullen voorkomen.
Keuze van b & r
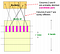
Als we b groot nemen, d.w.z. meer hashfuncties, dan verminderen we r omdat b*r een constante is (aantal rijen in handtekeningenmatrix). Intuïtief betekent dit dat we de kans op het vinden van een kandidaat-paar vergroten. Dit geval is equivalent aan het nemen van een kleine t (similariteitsdrempel)
Laten we zeggen dat je handtekeningenmatrix 100 rijen heeft. Beschouw 2 gevallen:
b1 = 10 → r = 10
b2 = 20 → r = 5
In het tweede geval is er een grotere kans dat 2 documenten ten minste eenmaal in dezelfde emmer voorkomen omdat ze meer kansen hebben (20 vs 10) en minder elementen van de handtekening worden vergeleken (5 vs 10).
Hogere b impliceert een lagere similariteitsdrempel (hogere fout-positieven) en lagere b impliceert een hogere similariteitsdrempel (hogere fout-negatieven)
Laten we dit proberen te begrijpen aan de hand van een voorbeeld.
Setup:
- 100k documenten opgeslagen als handtekening van lengte 100
- Signatuurmatrix: 100*100000
- Brute force vergelijking van handtekeningen zal resulteren in 100C2 vergelijkingen = 5 miljard (vrij veel!)
- Laten we b = 20 → r = 5
gelijkenis drempel (t) : 80%
We willen 2 documenten (D1 & D2) met 80% gelijkenis in dezelfde emmer gehasht hebben voor ten minste een van de 20 banden.
P(D1 & D2 identiek in een bepaalde band) = (0.8)⁵ = 0.328
P(D1 & D2 zijn niet gelijk in alle 20 banden) = (1-0.328)^20 = 0.00035
Dit betekent in dit scenario hebben we ~.035% kans op een vals negatief @ 80% soortgelijke documenten.
Ook willen we 2 documenten (D3 & D4) met 30% gelijkenis niet worden gehasht in dezelfde emmer voor een van de 20 banden (drempel = 80%).
P(D3 & D4 identiek in een bepaalde band) = (0,3)⁵ = 0.00243
P(D3 & D4 zijn gelijk in minstens één van de 20 banden) = 1 – (1-0.00243)^20 = 0.0474
Dit betekent dat we in dit scenario ~4.74% kans hebben op een vals-positief @ 30% gelijkende documenten.
Dus we kunnen zien dat we enkele vals-positieven en weinig vals-negatieven hebben. Deze verhouding zal variëren met de keuze van b en r.
Wat we hier willen is iets als hieronder. Als we 2 documenten die gelijkenis groter dan de drempel hebben dan waarschijnlijkheid van hen delen dezelfde emmer in ten minste een van de banden moet 1 anders 0.

Het slechtste geval is als we b = aantal rijen in de handtekeningenmatrix hebben, zoals hieronder wordt getoond.

Het algemene geval voor elke b en r wordt hieronder getoond.

Kies b en r om de beste S-curve te krijgen i.e minimaal vals-negatief en vals-positief percentage

LSH samenvatting
- Stel M, b, r om bijna alle documentparen met gelijkaardige handtekeningen te krijgen, maar elimineer de meeste paren die geen gelijkaardige handtekeningen hebben
- Controleer in hoofdgeheugen dat kandidaat-paren werkelijk gelijkaardige handtekeningen hebben