Hallo Mensen! In dit artikel zal ik een algoritme beschrijven dat in Natural Language Processing wordt gebruikt: Latente Semantische Analyse ( LSA ).
De belangrijkste toepassingen van deze voornoemde methode zijn veelomvattend in de linguïstiek: Het vergelijken van de documenten in laag-dimensionale ruimtes (Document Similarity), Het vinden van terugkerende onderwerpen over documenten heen (Topic Modeling), Het vinden van relaties tussen termen (Text Synoymity).

Inleiding
Het Latente Semantische Analyse model is een theorie voor hoe betekenis
representaties kunnen worden geleerd van het tegenkomen van grote taalmonsters zonder expliciete aanwijzingen over hoe het is gestructureerd.
Het probleem bij de hand is niet begeleid, dat wil zeggen we hebben geen vaste labels of categorieën toegewezen aan het corpus.
Om te extraheren en te begrijpen patronen uit de documenten, LSA inherent volgt bepaalde veronderstellingen:
1) Betekenis van zinnen of documenten is een som van de betekenis van alle woorden die voorkomen in het. Over het geheel genomen is de betekenis van een bepaald woord een gemiddelde over alle documenten waarin het voorkomt.
2) LSA gaat ervan uit dat de semantische associaties tussen woorden niet expliciet, maar slechts latent aanwezig zijn in de grote steekproef van taal.
Mathematisch Perspectief
Latente Semantische Analyse (LSA) bestaat uit bepaalde wiskundige bewerkingen om inzicht te krijgen in een document. Dit algoritme vormt de basis van Topic Modeling. Het kernidee is om een matrix te nemen van wat we hebben – documenten en termen – en deze te ontleden in een afzonderlijke document-topic matrix en een topic-term matrix.
De eerste stap is het genereren van onze document-term matrix met behulp van Tf-IDF Vectorizer. Het kan ook worden geconstrueerd met behulp van een Bag-of-Words Model, maar de resultaten zijn karig en geven geen betekenis aan de zaak.
Gegeven m documenten en n-woorden in onze woordenschat, kunnen we een
m × n matrix A construeren waarin elke rij een document voorstelt en elke kolom een woord.
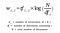
Intuïtief heeft een term een groot gewicht wanneer hij in het document vaak voorkomt, maar in het hele corpus niet vaak.
Wij vormen een document-termenmatrix, A met behulp van deze transformatiemethode (tf-IDF) om ons corpus te vectoriseren. (Op een manier, dat ons verdere model kan verwerken of evalueren, omdat we niet werken op strings tot nu toe!)
Maar er is een subtiel nadeel, we kunnen niets afleiden door het observeren van A, omdat het een ruisachtige en schaarse matrix is. (Soms te groot om zelfs maar te berekenen voor verdere processen).
Since Topic Modeling is inherent een algoritme zonder toezicht, we moeten de latente onderwerpen van tevoren specificeren. Het is analoog aan K-Means Clustering, waarbij we het aantal clusters van tevoren opgeven.
In dit geval voeren we een Low-Rank Approximation uit met behulp van een dimensionaliteitsreductietechniek waarbij gebruik wordt gemaakt van een afgeknotte Singular Value Decomposition (SVD).
Singular value decomposition is een techniek uit de lineaire algebra die een willekeurige matrix M ontbindt in het product van drie afzonderlijke matrices: M=U*S*V, waarbij S een diagonaalmatrix is van de singuliere waarden van M.
Truncated SVD vermindert de dimensionaliteit door alleen de t grootste singuliere waarden te selecteren, en alleen de eerste t kolommen van U en V te behouden. In dit geval is t een hyperparameter die we kunnen selecteren en aanpassen aan het aantal onderwerpen dat we willen vinden.
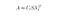
Note: Truncated SVD doet de dimensionaliteitsreductie en niet de SVD!

Met deze documentvectoren en termvectoren kunnen we nu gemakkelijk maatregelen zoals cosinusgelijkheid toepassen om te evalueren:
- de gelijkenis van verschillende documenten
- de gelijkenis van verschillende woorden
- de gelijkenis van termen (of “queries”) en documenten (wat nuttig wordt in information retrieval, wanneer we de passages willen terugvinden die het meest relevant zijn voor onze zoekopdracht).
Sluitende opmerkingen
Dit algoritme wordt veel gebruikt in verschillende NLP-gebaseerde taken en is de basis voor robuustere methoden zoals Probabilistic LSA en Latent Dirichlet Allocation (LDA).
Kushal Vala, Junior Data Scientist bij Datametica Solutions Pvt Ltd