
Wilt uw organisatie gegevens aggregeren en analyseren om trends te leren kennen, maar op een manier die de privacy beschermt? Of misschien gebruikt u al verschillende privacytools, maar wilt u uw kennis uitbreiden (of delen)? In beide gevallen is deze blogreeks iets voor u.
Waarom doen we deze reeks? Vorig jaar heeft NIST een Privacy Engineering Collaboration Space gelanceerd om open-sourcetools, -oplossingen en -processen te verzamelen die privacy engineering en risicobeheer ondersteunen. Als moderators voor de Collaboration Space hebben we NIST geholpen bij het verzamelen van verschillende privacytools onder het onderwerp de-identificatie. NIST heeft ook het Privacy Framework gepubliceerd: A Tool for Improving Privacy through Enterprise Risk Management en een bijbehorende routekaart waarin een aantal uitdagingen voor privacy worden onderkend, waaronder het onderwerp de-identificatie. We willen nu graag gebruikmaken van de samenwerkingsruimte om het hiaat in de routekaart op het gebied van de-identificatie te helpen opvullen. Ons einddoel is om NIST te ondersteunen bij het omzetten van deze reeks in meer diepgaande richtlijnen voor differentiële privacy.
Elke post begint met conceptuele basisprincipes en praktische gebruikscases, bedoeld om professionals zoals eigenaren van bedrijfsprocessen of personeel van privacyprogramma’s net genoeg te leren om gevaarlijk te zijn (grapje). Nadat de basisbeginselen zijn behandeld, zullen we kijken naar de beschikbare hulpmiddelen en hun technische aanpak voor privacy-engineers of IT-professionals die geïnteresseerd zijn in implementatiedetails. Om iedereen op de hoogte te brengen, zal deze eerste post achtergrondinformatie geven over differentiële privacy en enkele sleutelbegrippen beschrijven die we in de rest van de serie zullen gebruiken.
De uitdaging
Hoe kunnen we gegevens gebruiken om meer te weten te komen over een populatie, zonder iets te weten te komen over specifieke individuen binnen die populatie? Beschouw deze twee vragen eens:
- “Hoeveel mensen wonen er in Vermont?”
- “Hoeveel mensen met de naam Joe Near wonen er in Vermont?”
De eerste onthult een eigenschap van de hele populatie, terwijl de tweede informatie over één persoon onthult. Wij moeten iets kunnen leren over tendensen in de bevolking, maar mogen niets nieuws te weten komen over een bepaald individu. Dit is het doel van veel statistische analyses van gegevens, zoals de statistieken gepubliceerd door het U.S. Census Bureau, en machinaal leren in ruimere zin. In elk van deze instellingen zijn modellen bedoeld om trends in populaties te onthullen, niet om informatie over een enkel individu weer te geven.
Maar hoe kunnen we de eerste vraag beantwoorden: “Hoeveel mensen wonen er in Vermont?” – waarnaar we zullen verwijzen als een query – en tegelijkertijd voorkomen dat de tweede vraag wordt beantwoord: “Hoeveel mensen met de naam Joe Near wonen in Vermont?” De meest gebruikte oplossing heet de-identificatie (of anonimisering), waarbij identificerende informatie uit de dataset wordt verwijderd. (We gaan er in het algemeen van uit dat een dataset informatie bevat die van veel individuen is verzameld). Een andere mogelijkheid is om alleen geaggregeerde zoekopdrachten toe te staan, zoals een gemiddelde over de gegevens. Jammer genoeg begrijpen we nu dat geen van beide benaderingen een sterke bescherming van de privacy biedt. Niet-geïdentificeerde gegevensreeksen zijn vatbaar voor database-linkage attacks. Aggregatie beschermt de privacy alleen als de groepen die worden geaggregeerd groot genoeg zijn, en zelfs dan zijn privacy-aanvallen nog mogelijk.
Differentiële privacy
Differentiële privacy is een wiskundige definitie van wat het betekent om privacy te hebben. Het is geen specifiek proces zoals de-identificatie, maar een eigenschap die een proces kan hebben. Het is bijvoorbeeld mogelijk te bewijzen dat een specifiek algoritme “voldoet” aan differentiële privacy.
Informeel garandeert differentiële privacy het volgende voor elk individu dat gegevens bijdraagt voor analyse: de output van een differentieel private analyse zal ruwweg dezelfde zijn, ongeacht of u uw gegevens bijdraagt of niet. Een differentieel private analyse wordt vaak een mechanisme genoemd, en we noemen het ℳ.
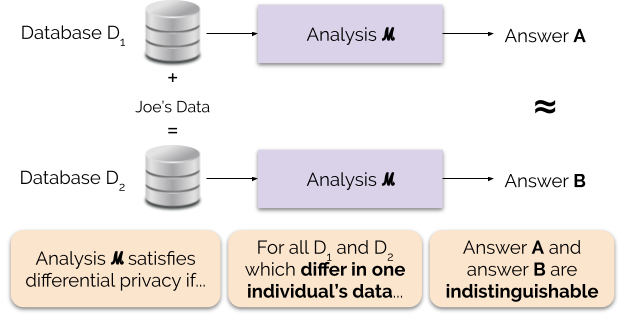
Figuur 1 illustreert dit principe. Antwoord “A” wordt berekend zonder de gegevens van Joe, terwijl antwoord “B” wordt berekend met de gegevens van Joe. Differentiële privacy zegt dat de twee antwoorden niet van elkaar te onderscheiden moeten zijn. Dit betekent dat degene die de uitvoer ziet, niet kan zien of de gegevens van Joe al dan niet zijn gebruikt, of wat de gegevens van Joe inhielden.
We regelen de sterkte van de privacy-garantie door de privacy-parameter ε in te stellen, ook wel privacyverlies of privacy-budget genoemd. Hoe lager de waarde van de ε-parameter, hoe ononderscheidelijker de resultaten, en dus hoe meer de gegevens van elk individu worden beschermd.
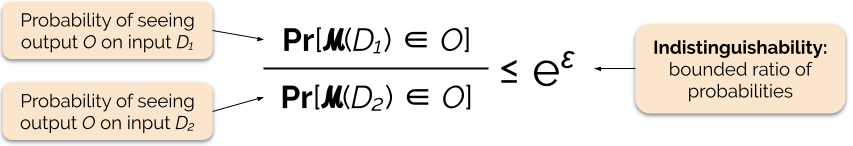
We kunnen een zoekopdracht vaak met differentiële privacy beantwoorden door wat willekeurige ruis toe te voegen aan het antwoord op de zoekopdracht. De uitdaging bestaat erin te bepalen waar en hoeveel ruis moet worden toegevoegd. Een van de meest gebruikte mechanismen om ruis toe te voegen is het Laplace-mechanisme.
Vragen met een hogere gevoeligheid vereisen het toevoegen van meer ruis om te voldoen aan een bepaalde `epsilon` hoeveelheid differentiële privacy, en deze extra ruis heeft de potentie om resultaten minder bruikbaar te maken. We zullen de gevoeligheid en deze afweging tussen privacy en bruikbaarheid in meer detail beschrijven in toekomstige blogposts.
Voordelen van differentiële privacy
Differentiële privacy heeft verschillende belangrijke voordelen ten opzichte van eerdere privacytechnieken:
- Het gaat ervan uit dat alle informatie identificerende informatie is, waardoor de uitdagende (en soms onmogelijke) taak om alle identificerende elementen van de gegevens te administreren, wordt geëlimineerd.
- Het is bestand tegen privacy-aanvallen op basis van hulpinformatie, zodat het op doeltreffende wijze de koppelingsaanvallen kan voorkomen die mogelijk zijn op ongeïdentificeerde gegevens.
- Het is compositorisch – we kunnen het privacyverlies bepalen van het uitvoeren van twee verschillend private analyses op dezelfde gegevens door eenvoudigweg de afzonderlijke privacyverliezen voor de twee analyses bij elkaar op te tellen. Compositie betekent dat we zinvolle garanties kunnen geven over de privacy, zelfs wanneer we meerdere analyseresultaten van dezelfde gegevens vrijgeven. Technieken zoals de-identificatie zijn niet compositorisch, en meervoudige vrijgave volgens deze technieken kan resulteren in een catastrofaal verlies van privacy.
Deze voordelen zijn de voornaamste redenen waarom een beoefenaar van de praktijk differentiële privacy zou verkiezen boven een andere techniek voor gegevensprivacy. Een nadeel van differentiële privacy is dat ze vrij nieuw is, en dat robuuste hulpmiddelen, normen en beste praktijken niet gemakkelijk toegankelijk zijn buiten de academische onderzoeksgemeenschappen. We voorspellen echter dat deze beperking in de nabije toekomst kan worden overwonnen door de toenemende vraag naar robuuste en gemakkelijk te gebruiken oplossingen voor gegevensprivacy.
Coming Up Next
Bewachting: onze volgende post zal voortbouwen op deze door de beveiligingskwesties te onderzoeken die betrokken zijn bij het implementeren van systemen voor differentiële privacy, inclusief het verschil tussen het centrale en lokale model van differentiële privacy.
Voordat we gaan – we willen dat deze serie en de daaropvolgende NIST-richtlijnen bijdragen aan het toegankelijker maken van differentiële privacy. U kunt daarbij helpen. Of u nu vragen hebt over deze berichten of uw kennis kunt delen, we hopen dat u met ons wilt samenwerken zodat we dit vakgebied samen kunnen bevorderen.
Garfinkel, Simson, John M. Abowd, en Christian Martindale. “Inzicht in database reconstructie aanvallen op openbare gegevens.” Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “When the signal is in the noise: exploiting diffix’s sticky noise.” 28e USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, en Kobbi Nissim. “Informatie onthullen met behoud van privacy.” Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. “Eenvoudige demografische gegevens identificeren mensen vaak op unieke wijze.” Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis.” Theorie van cryptografie conferentie. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan. “Differentiële privacy: A primer for a non-technical audience.” Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, en Aaron Roth. “De algoritmische grondslagen van differentiële privacy.” Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.