あらゆる数値データセットには、その配列値の重みを表す平均値が存在します。 平均値にはいろいろな種類がある! 今日はその中でも代表的な3つの平均値をご紹介します。 平均値、中央値、最頻値です。

Mean, Median and Mode are average values or central tendency of a numerical data set.これは数値データの平均値または中心傾向を表します。

最初に学ぶ指標は平均値です。 平均は、すべてのデータポイントを追加し、データポイントの数で割ることによって計算することができます。
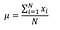
NYに適用されます。 を観測すると、NYのピザ価格のMeanは:

注釈:NYのピザ価格。 平均は中心的傾向の最も一般的な尺度ですが、外れ値(データセット内の他の値より有意に大きい値)の影響を受けやすいため、大きな欠点があります。
Median
Median はソートされたデータセットの中央の値で、すべてのデータポイントを並べて、中央の1つを選びます(または2つの中央の数字がある場合、その2つの数字の平均を取ります)。 6600>

ご覧のように、NYでは合計11件の観測値があり、真ん中の位置は6位のインデックスで、 (11+1)/2=6 と計算できることがおわかりいただけるでしょう。 つまり、NYのピザ価格の中央値は$6.00
LAはどうでしょうか。 LAには10件の観測結果があるので、中央の位置は5位と6位の間であり、(10+1)/2=5.5と計算できます。 つまりLAのピザ価格の中央値は$5.50
注:中央値は外れ値($66.00)の影響を受けない
Mode
Modeは最頻値、つまり最も多く出現する数字である。

ニューヨークのデータセットでは、$3.00は2回出現していて最も出現率が高いことが分かる。 ニューヨークのピザの最頻値は$3.00
LAのデータセットでは、2回(またはそれ以上)現れる数字はないことがわかる。 6600>
一般に、2つか3つのモードが頻繁に出現します。
どの測定値がベストか?
ベストというものはありませんが、1つだけ使うのは最悪です!
中心傾向のこれらの測定値は独立して使うより一緒に使ったほうがよいでしょう。 特定のシナリオによって、測定値のいくつかは他のものよりも意味がありますが、それらを一緒に使用することは個別よりも優れています。
Finding Mean, Median, and Mode in Microsoft Excel and Python
Excel は最も人気のあるソフトウェアで、Microsoft Office パッケージのデータを扱うのに簡単に使用することができます。 Excel では、平均、中央値、および最頻値を見つけるために 3 つの数式があります:

Note: your_data_set is your data set, should be 1 dimension array.
Python は Excel よりも強力で柔軟です。 しかし、プログラミング言語であるため、コードをコンパイルするために IDE をインストールする必要があります。
まず、統計ライブラリをインポートします
…その後、statisticsライブラリを短い名前statsで呼び出すことができます。 2行目と9行目にあるように、NYとLAのデータセットを含む配列を作成する必要があります。 そして、statisticsの定義済み関数を使って、平均、中央値、最頻値を求めます。
Spyderの変数探索ウィンドウを確認してみましょう。
NYデータセットの平均、中央、最頻値が11、6、3になっており、手計算やエクセルで得た数値と全く同じになっていますね。 LAでは最頻値を除き、平均値、中央値も同じです。 なぜでしょうか? mode_la

mode_la)なぜならLAのピザ価格には最頻値はないからです。 前にも述べたように、LAのデータセットのすべての値は、2回以上出現しません。
Conclusion:
- 平均:平均値.
- 中央値:並べ替えられたデータセットの中央値.
- Mode: データセットの最も出現する値。
- (Mean, Median, Mode の中で) 最高の測定はないが、1つだけを使うのは間違いなく最悪だ!
LAデータセットにモードは存在しない.LAデータセットにモードは存在しない.LAデータセットにモードは存在しない. Median:平均値.Medianは中央値.