
あなたの組織はデータを集約・分析して傾向を知りたい、しかしプライバシーは保護された方法で、と考えていませんか? あるいは、すでに差分プライバシー ツールを使用しているが、知識を増やしたい (または共有したい) とお考えでしょうか。 どちらの場合でも、このブログ シリーズはあなたのためにあります。
なぜこのシリーズを行うのか? 昨年、NISTはプライバシーエンジニアリングおよびリスク管理をサポートするオープンソースのツール、ソリューション、およびプロセスを集約するために、プライバシーエンジニアリングコラボレーションスペースを立ち上げました。 コラボレーション スペースのモデレーターとして、私たちは NIST が識別解除というトピック領域の下に差分プライバシー ツールを集める手助けをしてきました。 NISTはまた、プライバシーフレームワークを発表しました。 A Tool for Improving Privacy through Enterprise Risk Management)」と、それに付随するロードマップを発表し、非識別化のトピックを含む、プライバシーに関する多くの課題領域を認識させました。 今回、私たちはコラボレーションスペースを活用し、ロードマップにある非識別化に関するギャップを埋める手助けをしたいと考えています。
各記事は、ビジネス プロセスのオーナーやプライバシー プログラムの担当者などの専門家が、危険なほど十分に学べるように、概念の基礎と実用的な使用例から始まります (これは冗談です)。 基本をカバーした後、実装の詳細に関心のあるプライバシー エンジニアや IT 専門家のために、利用可能なツールやその技術的アプローチについて見ていきます。 すべての人がスピードアップできるように、この最初の投稿では、差分プライバシーに関する背景を説明し、このシリーズの残りの部分で使用するいくつかの重要な概念について説明します。
- “How many people live in Vermont?”
- “How many people named Joe Near live in Vermont?”
最初の質問は集団全体の特性を明らかにし、2番目は1人の情報を明らかにしている。 特定の個人について何か新しいことを知ることができないようにしながら、母集団の傾向について知ることができるようにする必要があります。 これは、米国国勢調査局が発表する統計など、多くのデータの統計解析や、より広範な機械学習の目標である。 これらの設定のそれぞれにおいて、モデルは集団の傾向を明らかにすることを目的としており、特定の個人に関する情報を反映するものではありません。
しかし、最初の質問 “バーモント州には何人住んでいますか?” にどのように答えることができるのでしょうか。 – という 2 番目の質問に答えられないようにしながら、クエリとして参照することができます。 最も広く使われている解決策は、データセットから識別情報を取り除く、非識別化(または匿名化)と呼ばれるものである。 (一般に、データセットには多数の個人から収集した情報が含まれていると仮定する)。 もうひとつの方法は、データの平均値など、総計的なクエリのみを許可することです。 しかし残念ながら、どちらの方法もプライバシーを強く保護するものではないことが分かってきた。 個人を特定できないデータセットは、データベース・リンケージ攻撃の対象になる。 集計は、集計されるグループが十分に大きい場合にのみプライバシーを保護するが、その場合でも、プライバシー攻撃は可能である。
Differential Privacy
Differential Privacyは、プライバシーを持つということが何を意味するのかを数学的に定義したものである。 これは非識別化のような特定のプロセスではなく、あるプロセスが持ち得る特性です。 例えば、特定のアルゴリズムが差分プライバシーを「満たす」ことを証明することができます。
非公式には、差分プライバシーは分析のためにデータを提供する各個人に対して次のことを保証しています:あなたがデータを提供するかどうかにかかわらず、差分プライバシーの分析の出力はほぼ同じになります。 差延的プライバシーの解析はしばしばメカニズムと呼ばれ、ℳと表記する。
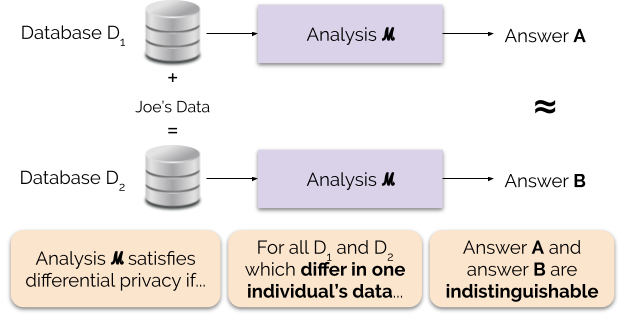
我々は、プライバシー損失またはプライバシー予算とも呼ばれるプライバシーパラメータεを調整することによって、プライバシー保証の強さを制御する。
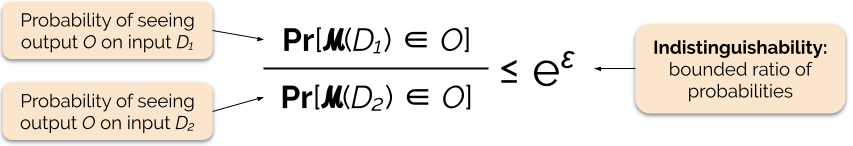
クエリの答えにいくつかのランダムノイズを追加することにより、差分プライバシーで答えることがしばしば可能である。 課題はどこにどの程度のノイズを加えるかを決定することにあります。 ノイズを追加するための最も一般的なメカニズムの1つはラプラスメカニズムです。
高い感度を持つクエリは、差分プライバシーの特定のイプシロン量を満たすために、より多くのノイズを加える必要があり、この余分なノイズは結果を有用でなくする可能性を秘めています。
Benefits of Differential Privacy
Differential Privacy には、以前のプライバシー技術と比較して、いくつかの重要な利点があります:
- すべての情報が識別情報であると仮定し、データのすべての識別要素を考慮するという難しい (そして時には不可能) 作業を省くことができます。
- 補助的な情報に基づくプライバシー攻撃に対して耐性があるため、非識別化データで可能なリンク攻撃を効果的に防ぐことができる。
- 構成的であり、2つの分析の個々のプライバシー損失を単に合計することにより、同じデータに対して異なるプライバシー分析を行うことによるプライバシー損失を決定することができる。 Compositionalityは、同じデータから複数の分析結果をリリースする場合でも、プライバシーについて意味のある保証をすることができることを意味します。 de-identificationのような技術は構成的ではなく、これらの技術による複数のリリースはプライバシーの壊滅的な損失につながる可能性がある。
これらの利点は、実務家が他のデータプライバシー技術ではなく差分プライバシーを選択する主な理由となるものである。 差分プライバシーの現在の欠点は、それがかなり新しく、堅牢なツール、標準、およびベストプラクティスが学術研究コミュニティ以外では容易にアクセスできないことです。 しかし、データ プライバシーのための堅牢で使いやすいソリューションへの需要が高まっているため、この制限は近い将来に克服できると予測しています。
Coming Up Next
Stay tuned: 次回の投稿では、今回に続き、差分プライバシーの中央モデルとローカルモデルの違いを含む、差分プライバシー用システムの展開に関わるセキュリティ問題を探究します。 あなたは助けることができます。 これらの投稿について質問がある場合も、知識を共有できる場合も、私たちが一緒にこの学問を発展させられるように、私たちと関わってくださることを願っています。
Garfinkel, Simson, John M. Abowd, and Christian Martindale. “公開データに対するデータベース再構築攻撃の理解” Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “When the signal is in the noise: exploiting diffix’s sticky noise.”(シグナルがノイズの中にあるとき:diffixのスティッキーノイズを利用する)。 28th USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, and Kobbi Nissim. “プライバシーを守りながら情報を明らかにする”. Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of Database Systems. 2003.
Sweeney, Latanya. “単純な人口統計はしばしば人々を一意に特定する” Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis.”. Theory of cryptography conference. このような場合、「個人情報保護法」の適用を受けることになる。 「差分プライバシー: 非技術的な聴衆のための入門書”. Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, and Aaron Roth. “The algorithmic foundations of differential privacy”. ファウンデーション・アンド・トレンド・イン・セオリーコンピュータサイエンス 9, no. 3-4 (2014): 211-407.