Disclaimer 1 : Cet article n’est qu’une introduction aux caractéristiques de MFCC et est destiné à ceux qui ont besoin d’une compréhension facile et rapide de la même chose. Les mathématiques détaillées et les complexités ne sont pas discutées.
N’ayant jamais travaillé dans le domaine du traitement de la parole moi-même, l’harking sur le mot « MFCC » (assez souvent utilisé par les pairs) m’a laissé avec la compréhension inadéquate qu’il est le nom donné à un type particulier de « caractéristiques » extraites de signaux audio (similaire aux bords qui constituent un type de caractéristiques extraites des images).


Il m’a fallu pas mal de lectures de sources multiples pour saisir la compréhension du novice de ce que sont les caractéristiques MFCC. J’ai donc décidé d’aider les compagnons humains dans le besoin en compilant les informations que j’ai recueillies d’une manière facile à comprendre.
Commençons par développer l’acronyme MFCC – Mel Frequency Cepstral Co-efficients.
Vous avez déjà entendu le mot cepstral ? Probablement pas. C’est spectral avec la spécification inversée ! Mais pourquoi ? Pour une compréhension très basique, le cepstre est l’information du taux de changement dans les bandes spectrales. Dans l’analyse conventionnelle des signaux temporels, toute composante périodique (par exemple, les échos) se manifeste par des pics nets dans le spectre de fréquence correspondant (c’est-à-dire le spectre de Fourier). Celui-ci est obtenu en appliquant une transformée de Fourier sur le signal temporel). Cela peut être vu dans l’image suivante.

En prenant le logarithme de la magnitude de ce spectre de Fourier, puis en prenant à nouveau le spectre de ce logarithme par une transformation en cosinus (je sais que cela semble compliqué, mais soyez indulgent avec moi s’il vous plaît !), nous observons un pic partout où il y a un élément périodique dans le signal temporel original. Puisque nous appliquons une transformation sur le spectre de fréquence lui-même, le spectre résultant n’est ni dans le domaine de la fréquence ni dans le domaine du temps et c’est pourquoi Bogert et al. ont décidé de l’appeler le domaine de la fréquence. Et ce spectre du logarithme du spectre du signal temporel a été nommé cepstrum (ta-da !).
L’image suivante est un résumé des étapes expliquées ci-dessus.

Le cepstrum a été introduit pour la première fois pour caractériser les échos sismiques résultant en raison des tremblements de terre.
Le pitch est l’une des caractéristiques d’un signal vocal et est mesuré comme la fréquence du signal. L’échelle Mel est une échelle qui met en relation la fréquence perçue d’un son avec la fréquence réelle mesurée. Elle met la fréquence à l’échelle afin de correspondre plus étroitement à ce que l’oreille humaine peut entendre (les humains sont plus aptes à identifier les petits changements dans la parole à des fréquences plus basses). Cette échelle a été dérivée de séries d’expériences sur des sujets humains. Laissez-moi vous donner une explication intuitive de ce que l’échelle mel capte.
La gamme de l’audition humaine est de 20Hz à 20kHz. Imaginez une mélodie à 300 Hz. Cela ressemblerait à la tonalité standard d’un téléphone fixe. Imaginez maintenant une mélodie à 400 Hz (une tonalité de numéroteur un peu plus aiguë). Comparez maintenant la distance entre ces deux sons, quelle que soit la perception qu’en a votre cerveau. Imaginez maintenant un signal à 900 Hz (semblable à un son de retour de microphone) et un son à 1 kHz. La distance perçue entre ces deux sons peut sembler plus grande que celle des deux premiers, bien que la différence réelle soit la même (100 Hz). L’échelle mel tente de rendre compte de ces différences. Une fréquence mesurée en Hertz (f) peut être convertie en échelle Mel à l’aide de la formule suivante :
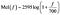
Tout son généré par les humains est déterminé par la forme de leur conduit vocal (y compris la langue, les dents, etc). Si cette forme peut être déterminée correctement, tout son produit peut être représenté avec précision. L’enveloppe du spectre de puissance temporelle du signal vocal est représentative du conduit vocal et le MFCC (qui n’est rien d’autre que les coefficients qui composent le cepstre de fréquence Mel) représente précisément cette enveloppe. Le schéma fonctionnel suivant est un résumé par étapes de la façon dont nous sommes arrivés aux MFCC:
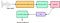
Ici, la banque de filtres fait référence aux filtres mel (couvrant l’échelle mel) et les coefficients cepstraux ne sont rien d’autre que des MFCC.
TL ; DR – Les caractéristiques MFCC représentent des phonèmes (unités distinctes de son) car la forme du tractus vocal (qui est responsable de la génération du son) y est manifeste.
Disclaimer 2 : Toutes les images proviennent de Google images.