
Votre organisation souhaite-t-elle agréger et analyser des données pour connaître les tendances, mais d’une manière qui protège la confidentialité ? Ou peut-être utilisez-vous déjà des outils différentiels de protection de la vie privée, mais vous souhaitez élargir (ou partager) vos connaissances ? Dans les deux cas, cette série de blogs est pour vous.
Pourquoi faisons-nous cette série ? L’année dernière, le NIST a lancé un espace de collaboration pour l’ingénierie de la confidentialité afin de regrouper les outils, solutions et processus open source qui soutiennent l’ingénierie de la confidentialité et la gestion des risques. En tant que modérateurs de l’espace de collaboration, nous avons aidé le NIST à rassembler des outils différentiels de protection de la vie privée dans le domaine de la dé-identification. Le NIST a également publié le Privacy Framework : A Tool for Improving Privacy through Enterprise Risk Management (Cadre de protection de la vie privée : un outil pour améliorer la protection de la vie privée par la gestion des risques de l’entreprise) et une feuille de route qui l’accompagne et qui reconnaît un certain nombre de défis pour la protection de la vie privée, y compris le sujet de la désidentification. Nous aimerions maintenant tirer parti de l’espace de collaboration pour aider à combler les lacunes de la feuille de route en matière de désidentification. Notre objectif final est d’aider le NIST à transformer cette série en directives plus approfondies sur la confidentialité différentielle.
Chaque post commencera par des bases conceptuelles et des cas d’utilisation pratiques, visant à aider les professionnels tels que les propriétaires de processus d’affaires ou le personnel du programme de confidentialité à apprendre juste assez pour être dangereux (je plaisante). Après avoir couvert les bases, nous examinerons les outils disponibles et leurs approches techniques pour les ingénieurs en confidentialité ou les professionnels de l’informatique intéressés par les détails de mise en œuvre. Pour mettre tout le monde au courant, ce premier post fournira un contexte sur la confidentialité différentielle et décrira certains concepts clés que nous utiliserons dans le reste de la série.
Le défi
Comment pouvons-nous utiliser des données pour apprendre sur une population, sans apprendre sur des individus spécifiques au sein de la population ? Considérez ces deux questions :
- « Combien de personnes vivent dans le Vermont ? »
- « Combien de personnes nommées Joe Near vivent dans le Vermont ? »
La première révèle une propriété de la population entière, tandis que la seconde révèle des informations sur une personne. Nous devons être en mesure de connaître les tendances de la population tout en empêchant la possibilité d’apprendre quoi que ce soit de nouveau sur un individu particulier. C’est l’objectif de nombreuses analyses statistiques de données, telles que les statistiques publiées par le Bureau du recensement des États-Unis, et plus largement de l’apprentissage automatique. Dans chacun de ces contextes, les modèles sont destinés à révéler des tendances dans les populations, et non à refléter des informations sur un individu en particulier.
Mais comment pouvons-nous répondre à la première question « Combien de personnes vivent dans le Vermont ? » – que nous appellerons une requête – tout en empêchant de répondre à la seconde question « Combien de personnes s’appelant Joe Near vivent dans le Vermont ? ». La solution la plus répandue est la dé-identification (ou anonymisation), qui consiste à supprimer les informations d’identification de l’ensemble de données. (Nous supposerons généralement qu’un ensemble de données contient des informations recueillies auprès de nombreux individus). Une autre option consiste à n’autoriser que les requêtes agrégées, telles qu’une moyenne des données. Malheureusement, nous comprenons maintenant qu’aucune de ces deux approches n’offre une forte protection de la vie privée. Les ensembles de données dépersonnalisées sont sujets à des attaques de type « database-linkage ». L’agrégation ne protège la vie privée que si les groupes agrégés sont suffisamment grands, et même dans ce cas, les attaques contre la vie privée sont toujours possibles .
La confidentialité différentielle
La confidentialité différentielle est une définition mathématique de ce que signifie avoir de la confidentialité. Il ne s’agit pas d’un processus spécifique comme la dé-identification, mais d’une propriété qu’un processus peut avoir. Par exemple, il est possible de prouver qu’un algorithme spécifique « satisfait » à la confidentialité différentielle.
Informellement, la confidentialité différentielle garantit ce qui suit pour chaque individu qui fournit des données à analyser : le résultat d’une analyse différentiellement privée sera à peu près le même, que vous fournissiez ou non vos données. Une analyse différentiellement privée est souvent appelée un mécanisme, et nous la désignons par ℳ.
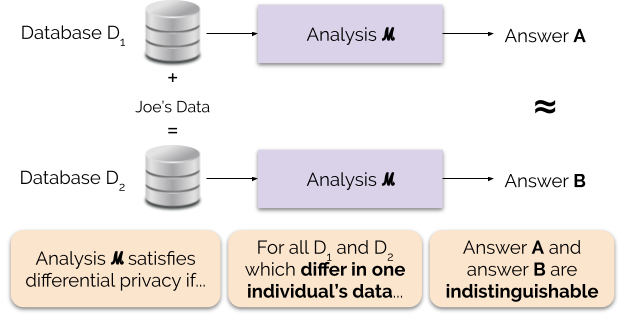
La figure 1 illustre ce principe. La réponse « A » est calculée sans les données de Joe, tandis que la réponse « B » est calculée avec les données de Joe. La confidentialité différentielle stipule que les deux réponses doivent être indiscernables. Cela implique que quiconque voit la sortie ne sera pas en mesure de dire si les données de Joe ont été utilisées ou non, ou ce que les données de Joe contenaient.
Nous contrôlons la force de la garantie de confidentialité en réglant le paramètre de confidentialité ε, également appelé perte de confidentialité ou budget de confidentialité. Plus la valeur du paramètre ε est faible, plus les résultats sont indiscernables, et donc plus les données de chaque individu sont protégées.
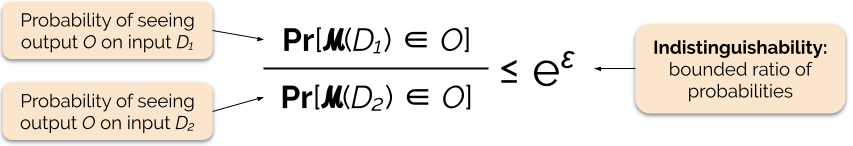
Nous pouvons souvent répondre à une requête avec une confidentialité différentielle en ajoutant un certain bruit aléatoire à la réponse de la requête. Le défi consiste à déterminer où ajouter le bruit et quelle quantité ajouter. L’un des mécanismes les plus couramment utilisés pour ajouter du bruit est le mécanisme de Laplace .
Les requêtes avec une sensibilité plus élevée nécessitent d’ajouter plus de bruit afin de satisfaire une quantité particulière `epsilon` de confidentialité différentielle, et ce bruit supplémentaire a le potentiel de rendre les résultats moins utiles. Nous décrirons la sensibilité et ce compromis entre la confidentialité et l’utilité plus en détail dans de futurs articles de blog.
Avantages de la confidentialité différentielle
La confidentialité différentielle présente plusieurs avantages importants par rapport aux techniques de confidentialité précédentes :
- Elle suppose que toutes les informations sont des informations d’identification, éliminant la tâche difficile (et parfois impossible) de comptabiliser tous les éléments d’identification des données.
- Il est résistant aux attaques de la vie privée basées sur des informations auxiliaires, de sorte qu’il peut efficacement empêcher les attaques de liaison qui sont possibles sur les données dépersonnalisées.
- Il est compositionnel – nous pouvons déterminer la perte de confidentialité de l’exécution de deux analyses différentiellement privées sur les mêmes données en ajoutant simplement les pertes de confidentialité individuelles pour les deux analyses. La compositionnalité signifie que nous pouvons faire des garanties significatives sur la vie privée, même lorsque nous publions plusieurs résultats d’analyse à partir des mêmes données. Les techniques comme la désidentification ne sont pas compositionnelles, et les divulgations multiples selon ces techniques peuvent entraîner une perte catastrophique de la vie privée.
Ces avantages sont les principales raisons pour lesquelles un praticien pourrait choisir la confidentialité différentielle plutôt qu’une autre technique de confidentialité des données. Un inconvénient actuel de la confidentialité différentielle est qu’elle est plutôt nouvelle, et les outils robustes, les normes et les meilleures pratiques ne sont pas facilement accessibles en dehors des communautés de recherche universitaires. Cependant, nous prévoyons que cette limitation peut être surmontée dans un avenir proche en raison de la demande croissante de solutions robustes et faciles à utiliser pour la confidentialité des données.
Coming Up Next
Rester à l’écoute : notre prochain post s’appuiera sur celui-ci en explorant les problèmes de sécurité impliqués dans le déploiement de systèmes pour la confidentialité différentielle, y compris la différence entre les modèles centraux et locaux de la confidentialité différentielle.
Avant de partir – nous voulons que cette série et les directives ultérieures du NIST contribuent à rendre la confidentialité différentielle plus accessible. Vous pouvez aider. Que vous ayez des questions sur ces postes ou que vous puissiez partager vos connaissances, nous espérons que vous vous engagerez avec nous afin que nous puissions faire progresser cette discipline ensemble.
Garfinkel, Simson, John M. Abowd, et Christian Martindale. « Comprendre les attaques de reconstruction de bases de données sur des données publiques ». Communications of the ACM 62.3 (2019) : 46-53.
Gadotti, Andrea, et al. « Quand le signal est dans le bruit : exploiter le bruit collant de diffix. » 28e symposium sur la sécurité de l’USENIX (USENIX Security 19). 2019.
Dinur, Irit, et Kobbi Nissim. « Révéler des informations tout en préservant la vie privée ». Actes du vingt-deuxième symposium ACM SIGMOD-SIGACT-SIGART sur les principes des systèmes de bases de données. 2003.
Sweeney, Latanya. « De simples données démographiques permettent souvent d’identifier les gens de manière unique ». Santé (San Francisco) 671 (2000) : 1-34.
Dwork, Cynthia, et al. « Calibrer le bruit à la sensibilité dans l’analyse des données privées. » Conférence sur la théorie de la cryptographie. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, et Salil Vadhan. « Confidentialité différentielle : A primer for a non-technical audience ». Vand. J. Ent. & Tech. L. 21 (2018) : 209.
Dwork, Cynthia, et Aaron Roth. « Les fondements algorithmiques de la vie privée différentielle ». Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014) : 211-407.