Le Myanmar est actuellement le seul pays au monde avec une présence en ligne significative qui n’a pas normalisé sur Unicode, la norme internationale de codage de texte. Au lieu de cela, Zawgyi est la police de caractères dominante utilisée pour coder les caractères de la langue birmane. Cette absence de norme unique a entraîné des difficultés techniques pour de nombreuses entreprises qui fournissent des applications et des services mobiles au Myanmar. Elle rend la communication sur les plateformes numériques difficile, car le contenu écrit en Unicode apparaît déformé aux utilisateurs de Zawgyi et vice versa. C’est un problème pour des applications comme Facebook et Messenger, car les messages et les commentaires écrits dans un encodage ne sont pas lisibles dans un autre. Le manque de normalisation autour d’Unicode rend plus difficile l’automatisation et la détection proactive des contenus contrevenants, il peut affaiblir la sécurité des comptes, il rend moins efficace le signalement de contenus potentiellement préjudiciables sur Facebook, et il signifie moins de prise en charge des langues du Myanmar au-delà du birman.
L’année dernière, pour soutenir la transition du Myanmar vers Unicode, nous avons supprimé Zawgyi comme option de langue d’interface pour les nouveaux utilisateurs de Facebook. Ensuite, nous avons travaillé pour nous assurer que nos classificateurs pour les discours haineux et autres contenus violant les politiques n’allaient pas trébucher sur le contenu Zawgyi et avons commencé à travailler sur l’intégration de convertisseurs de polices pour améliorer l’expérience du contenu sur les appareils Unicode. Aujourd’hui, pour aider le pays à poursuivre sa transition vers Unicode, nous annonçons que nous avons mis en place des convertisseurs de polices dans Facebook et Messenger. Parce que nous savons que cette transition prendra du temps, notre convertisseur Zawgyi-to-Unicode continuera à permettre aux personnes en transition vers Unicode de lire les publications, les messages et les commentaires même si leurs amis et leur famille n’ont pas encore effectué la transition sur leurs appareils. Ce post détaillera les défis techniques impliqués dans l’intégration de ces convertisseurs, y compris comment nous différencions le texte Zawgyi d’Unicode, comment nous pouvons dire si un appareil utilise Zawgyi ou Unicode, et comment convertir entre les deux, ainsi que certaines leçons que nous avons apprises en cours de route.
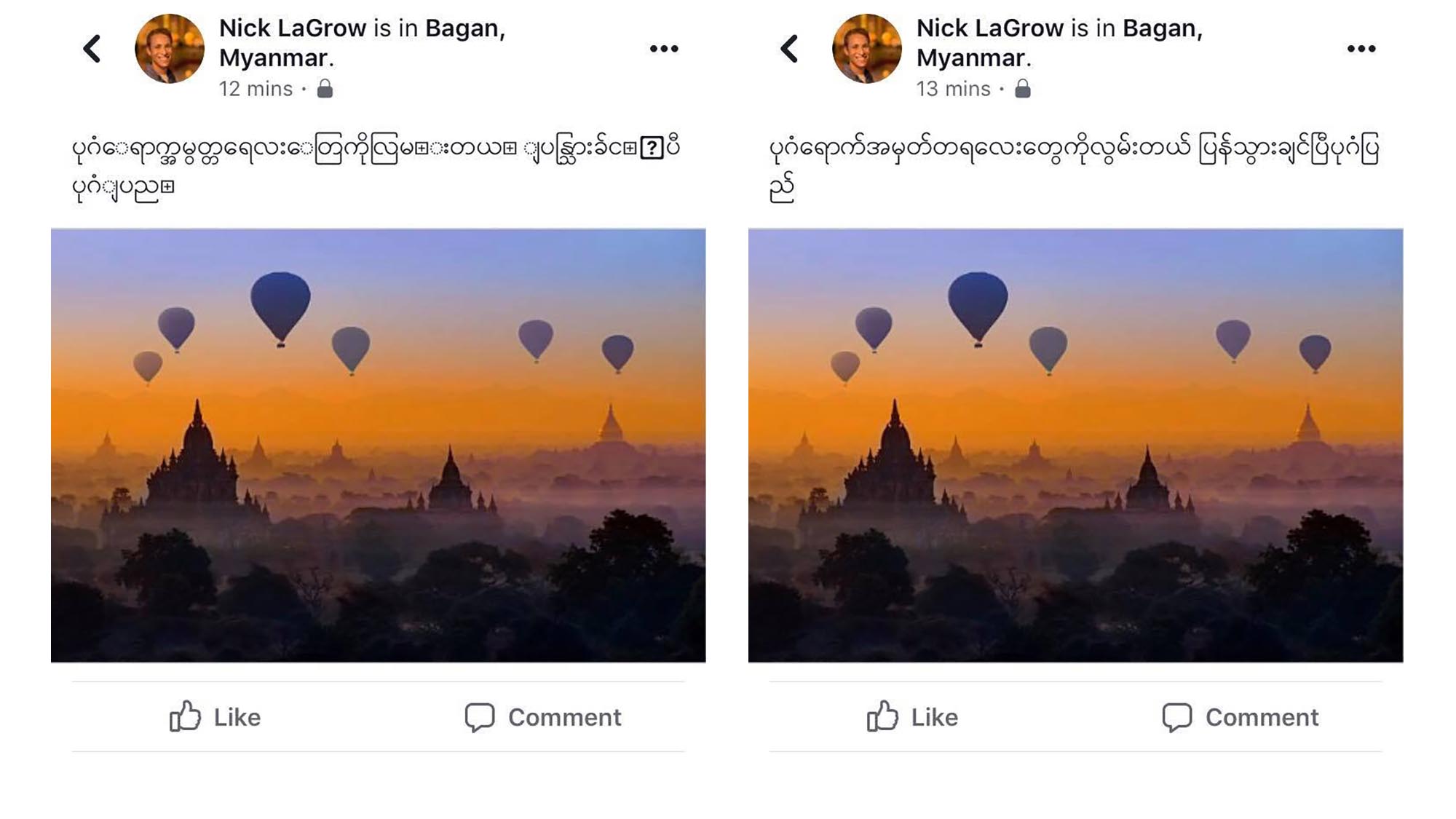
Pourquoi Unicode?
Unicode a été conçu comme un système global pour permettre à chacun dans le monde d’utiliser sa propre langue sur ses appareils. Mais la plupart des appareils au Myanmar utilisent encore le zawgyi, qui est incompatible avec Unicode. Les utilisateurs de ces appareils sont donc confrontés à des problèmes de compatibilité entre les plateformes, les systèmes d’exploitation et les langages de programmation. Afin de mieux toucher leur public, les producteurs de contenu au Myanmar publient souvent dans un même message à la fois en Zawgyi et en Unicode, sans parler de l’anglais ou d’autres langues. Le codage Zawgyi utilise de multiples points de code pour les caractères et les rendus combinés ; il nécessite deux fois plus de points de code pour représenter seulement un sous-ensemble de l’écriture ; et les points de code des voyelles peuvent apparaître avant ou après une consonne (de sorte que CAT ou CTA se lisent de la même façon), ce qui entraîne des problèmes de recherche et de comparaison, même au sein d’un seul document. Cela fait de tout type de communication entre systèmes un énorme défi.
Facebook soutient Unicode car il offre un support et une norme cohérente pour chaque langue. Au Myanmar, en particulier, nous soutenons la transition vers Unicode parce que :
- Il permet aux personnes au Myanmar d’utiliser nos apps et services dans des langues autres que le birman. Zawgyi prend en charge la saisie de texte uniquement en birman, tandis qu’Unicode permet de saisir les langues minoritaires parlées au Myanmar, comme le shan et le mon.
- Il offre une forme normalisée pour les langues du Myanmar, ce qui nous aide à protéger les personnes qui utilisent nos apps en détectant les contenus violant les politiques et améliore considérablement les performances des outils de recherche.
- Il nous permet d’examiner plus efficacement les rapports de contenu potentiellement préjudiciable sur Facebook, et les réviseurs de contenu pourront examiner les problèmes sans avoir besoin de savoir comment le contenu a été encodé.
Une approche à trois volets
Lorsque nous avons commencé à examiner l’encodage en birman, notre priorité absolue était de nous assurer que nos systèmes qui détectent le contenu préjudiciable, comme les discours de haine, ne trébuchent pas sur le zawgyi. Nous avons expliqué nos objectifs à cet égard dans cet article de blog. Les mêmes défis (tels que les points de code multiples et les rendus combinés) qui rendent difficile la communication des systèmes à l’aide de Zawgyi rendent également difficile l’entraînement de nos classificateurs et systèmes d’IA pour détecter efficacement les contenus violant les politiques.
Heureusement, nous ne sommes pas la seule entreprise à travailler sur ce problème, et nous avons pu utiliser la bibliothèque open source myanmar-tools de Google pour mettre en œuvre notre solution. La bibliothèque myanmar-tools a constitué une amélioration majeure, en termes de précision de détection et de conversion, par rapport à la bibliothèque basée sur les regex que nous utilisions. Il y a environ un an, nous avons intégré la détection et la conversion des polices pour convertir tout le contenu en Unicode avant de passer par nos classificateurs. La mise en œuvre de la conversion automatique dans tous nos produits n’a pas été une tâche simple. Chacune des exigences de l’autoconversion – détection de l’encodage du contenu, détection de l’encodage du périphérique et conversion – avait ses propres défis.
Détection de l’encodage du contenu
Pour effectuer l’autoconversion, nous devons d’abord connaître l’encodage du contenu, c’est-à-dire l’encodage utilisé lors de la première entrée du texte. Malheureusement, Zawgyi et Unicode utilisent la même gamme de points de code pour représenter les caractères du birman et d’autres langues. Pour cette raison, nous ne pouvons pas dire si une liste de points de code représentant une chaîne doit être rendue avec Zawgyi ou Unicode. En outre, toutes les chaînes de points de code n’ont pas de sens dans les deux codages. Avec un modèle entraîné sur du texte créé en Zawgyi et en Unicode, nous pouvons évaluer la probabilité qu’une chaîne donnée ait été créée avec un clavier Zawgyi ou Unicode.

Notre détection est basée sur l’approche de la bibliothèque myanmar-tools. Nous entraînons un modèle d’apprentissage automatique (ML) sur des échantillons de contenu public Facebook dont nous connaissons déjà l’encodage du contenu. Ce modèle garde la trace de la probabilité qu’une série de points de code apparaisse en Unicode ou en Zawgyi pour chaque échantillon. Plus tard, lorsque nous déterminons l’encodage du contenu de quelqu’un, nous regardons la prédiction du modèle pour savoir si cette séquence de points de code était plus susceptible d’avoir été saisie en Unicode ou en Zawgyi – et nous utilisons ce résultat comme encodage du contenu.
Détection de l’encodage de l’appareil
Puis, nous devons savoir quel encodage a été utilisé par le téléphone d’une personne (c’est-à-dire l’encodage de l’appareil) pour comprendre si nous devons effectuer une conversion de l’encodage de la police. Pour ce faire, nous pouvons tirer parti du fait que dans un encodage, la combinaison de plusieurs points de code permettra de combiner des fragments de texte pour créer un seul caractère, alors que dans l’autre encodage, ces deux points de code pourraient représenter des caractères distincts. Si nous créons une chaîne sur le périphérique et que nous vérifions la largeur de cette chaîne, nous pouvons savoir quel encodage de police le périphérique utilise pour rendre la chaîne. Une fois que nous disposons de cette information, nous pouvons indiquer au serveur, dans les futures requêtes Web, que l’appareil utilise Zawgyi ou Unicode et nous assurer que le contenu récupéré correspond. Dans Myanmar, notre logique côté client détermine si le périphérique en question est Zawgyi ou Unicode et envoie cet encodage comme partie du champ locale dans la requête web (par exemple, my_Qaag_MM).
Conversion
Puis, le serveur vérifie s’il charge du contenu birman. Si l’encodage du contenu et celui de l’appareil ne correspondent pas, nous devons convertir le contenu dans un format que l’appareil du lecteur rendra correctement. Par exemple, si un billet a été saisi avec un encodage de contenu Unicode, mais qu’il est lu sur un appareil encodé en Zawgyi, nous convertissons le texte du billet en Zawgyi avant de le rendre sur l’appareil Zawgyi.
Il est important d’entraîner ce modèle sur du contenu Facebook plutôt que sur d’autres contenus accessibles au public sur le web. Les gens écrivent différemment sur Facebook qu’ils le feraient sur une page web ou dans un article savant : Les publications et les messages Facebook sont généralement plus courts et moins formels, et ils contiennent des abréviations, de l’argot et des fautes de frappe. Nous voulons que nos prédictions soient aussi précises que possible pour le contenu que les gens partagent et lisent sur nos apps.
Intégrer l’autoconversion à l’échelle de Facebook
Le défi suivant était d’intégrer cette conversion à travers les différents types de contenu que les gens peuvent créer sur nos apps. Le texte zawgyi a été saisi pour les mises à jour de statut ainsi que pour les noms d’utilisateur, les commentaires, les sous-titres de vidéos, les messages privés, et plus encore. L’exécution de notre détection et de notre conversion chaque fois que quelqu’un va chercher n’importe quel type de contenu serait prohibitive en termes de temps et de ressources nécessaires. Il n’y a pas de pipeline unique par lequel passe tout le contenu possible de Facebook, ce qui rend difficile la capture du contenu Zawgyi partout où quelqu’un pourrait le saisir. En outre, toutes les requêtes web ne sont pas effectuées à partir de l’appareil d’une personne. Par exemple, lorsque les notifications et les messages sont envoyés aux appareils, nous ne pouvons pas exécuter la logique d’encodage des appareils. De plus, les messages et les commentaires sont souvent très courts, ce qui diminue la précision de la détection.
Le convertisseur de polices est maintenant entièrement mis en œuvre sur Facebook et Messenger. Ces outils feront une grande différence pour les millions de personnes au Myanmar qui utilisent nos applications pour communiquer avec leurs amis et leur famille. Pour continuer à soutenir les habitants du Myanmar dans cette transition vers Unicode, nous envisageons d’étendre nos outils de conversion automatique à d’autres produits de la famille Facebook, ainsi que d’améliorer la qualité de notre détection et de notre conversion automatiques. Nous avons également l’intention de continuer à contribuer à la bibliothèque open source myanmar-tools pour aider d’autres personnes à construire des outils pour soutenir cette transition.