Locality-sensitive hashing
Tavoite: Etsiä dokumentit, joiden Jaccard- samankaltaisuus on vähintään t
Locality Sensitive Hashing -algoritmin yleisenä ideana on löytää sellainen algoritmi, että jos syötämme kahden dokumentin allekirjoitukset, se kertoo, että nämä kaksi dokumenttia muodostavat ehdollisen parin tai eivät muodosta, ts. niiden samankaltaisuus on kynnysarvoa t suurempi. On muistettava, että allekirjoitusten samankaltaisuutta käytetään alkuperäisten asiakirjojen Jaccard- samankaltaisuuden korvikkeena.
Kohtaisesti min-hash-allekirjoitusmatriisia varten:
- Hashataan allekirjoitusmatriisin M sarakkeet useilla hash-funktioilla
- Jos 2 dokumenttia hashataan samaan kauhaan vähintään yhdellä hash-funktiolla, voimme ottaa 2 dokumenttia ehdokkaiden pariksi
Kysymys kuuluu, miten luodaan erilaisia hash-funktioita. Tätä varten teemme band partition.
Band partition

Tässä on algoritmi:
- Jaa allekirjoitusmatriisi b-kaistoihin, joissa kussakin kaistassa on r riviä
- Kunkin kaistan osalta, Hashaa sen osuus kustakin sarakkeesta hash-taulukkoon, jossa on k ämpäriä
- Kandidaattisarakepareja ovat ne, jotka hashataan samaan ämpäriin vähintään yhdessä kaistassa
- Viritä b ja r niin, että saadaan kiinni useimmat samankaltaiset, mutta vain vähän ei- samankaltaisia pareja
Tässä on muutama huomio. Ihannetapauksessa jokaisessa kaistassa haluamme k:n olevan yhtä suuri kuin kaikki mahdolliset arvojen yhdistelmät, joita sarake voi ottaa kaistan sisällä. Tämä vastaa identiteettisovitusta. Mutta tällä tavalla k on valtava luku, joka on laskennallisesti mahdoton toteuttaa. Esimerkiksi: Jos kaistassa on 5 riviä. Jos allekirjoituksen elementit ovat 32-bittisiä kokonaislukuja, k on tässä tapauksessa (2³²)⁵ ~ 1.4615016e+48. Voit nähdä, mikä on ongelma tässä. Normaalisti k:n arvoksi otetaan noin miljoona.
Ajatuksena on, että jos kaksi asiakirjaa on samankaltaisia, ne esiintyvät ehdokasparina vähintään yhdessä kaistassa.
Valinta b & r
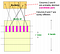
Jos otamme b:n suureksi eli enemmän hash-funktioiden lukumäärää, pienennämme r:ää, koska b*r on vakio (allekirjoitustaulukkomatriisin rivien lukumäärä). Intuitiivisesti se tarkoittaa, että lisäämme ehdokasparin löytämisen todennäköisyyttä. Tämä tapaus vastaa sitä, että otamme pienen t:n (samankaltaisuuskynnys)
Sanotaan, että allekirjoitusmatriisissa on 100 riviä. Tarkastellaan 2 tapausta:
b1 = 10 → r = 10
b2 = 20 → r = 5
Kakkostapauksessa on suurempi todennäköisyys, että 2 dokumenttia esiintyy samassa kauhassa vähintään kerran, koska niillä on enemmän mahdollisuuksia (20 vs. 10) ja vähemmän allekirjoituksen elementtejä vertaillaan (5 vs. 10).
Korkeampi b merkitsee matalampaa samankaltaisuuskynnystä (korkeammat väärät positiiviset) ja matalampi b merkitsee korkeampaa samankaltaisuuskynnystä (korkeammat väärät negatiiviset)
Yritetään ymmärtää tämä esimerkin avulla.
Asetukset:
- 100k dokumenttia tallennettuna allekirjoituksena, jonka pituus on 100
- Allekirjoitusmatriisi: 100*100000
- Allekirjoitusten brute force-vertailu johtaa 100C2 vertailuun = 5 miljardia (aika paljon!)
- Viedään b = 20 → r = 5
Samankaltaisuuskynnys (t) : 80 %
Tahdomme, että 2 dokumenttia (D1 & D2), joilla on 80 %:n samankaltaisuus, on hashattuna samassa ämpäreessä vähintään yhdessä 20:stä kaistaleesta.
P(D1 & D2 identtiset tietyssä kaistassa) = (0.8)⁵ = 0.328
P(D1 & D2 eivät ole samanlaisia kaikissa 20 kaistassa) = (1-0.328)^20 = 0.00035
Tämä tarkoittaa tässä skenaariossa ~.035 %:n mahdollisuus väärään negatiiviseen tulokseen 80 %:n samankaltaisten asiakirjojen kohdalla.
Tahdomme myös, että 2 asiakirjaa (D3 & D4), joilla on 30 %:n samankaltaisuus, eivät ole hashattuja samassa kaapissa missään 20:stä kaistasta (kynnysarvo = 80 %).
P(D3 & D4 identtinen tietyssä kaistassa) = (0.3)⁵ = 0.00243
P(D3 & D4 ovat samanlaisia vähintään yhdessä 20:stä kaistasta) = 1 – (1-0.00243)^20 = 0.0474
Tämä tarkoittaa, että tässä skenaariossa meillä on ~4.74 %:n mahdollisuus vääriin positiivisiin tuloksiin 30 %:n samankaltaisten asiakirjojen kohdalla.
Voidaan siis havaita, että meillä on jonkin verran vääriä positiivisia tuloksien tuloksia ja vain vähän vääriä negatiivisia. Nämä osuudet vaihtelevat b:n ja r:n valinnan mukaan.
Haluamme tässä tapauksessa jotain alla olevan kaltaista. Jos meillä on kaksi asiakirjaa, joiden samankaltaisuus on suurempi kuin kynnysarvo, todennäköisyyden, että ne jakavat saman kaistan ainakin yhdessä kaistassa, pitäisi olla 1 tai 0.

Pahin tapaus on, jos meillä on b = allekirjoitustaulukkomatriisin rivien lukumäärä alla olevan kuvan mukaisesti.

Yleistetty tapaus minkä tahansa b:n ja r:n tapauksessa on esitetty alla.

Valitaan b ja r, jotta saadaan paras S-käyrä i.e minimaalinen väärien negatiivisten ja väärien positiivisten osuus

LSH-yhteenveto
- Viritä M, b, r niin, että saadaan lähes kaikki dokumenttiparit, joilla on samankaltaiset allekirjoitukset, mutta eliminoidaan suurin osa pareista, joilla ei ole samankaltaisia allekirjoituksia
- Tarkistetaan keskusmuistissa, että ehdokaspareilla todella on samankaltaiset allekirjoitukset