Hello Folks! Tässä artikkelissa kuvaan luonnollisen kielen prosessoinnissa käytettävää algoritmia: Latentti semanttinen analyysi ( LSA ).
Tämän edellä mainitun menetelmän tärkeimmät sovellukset ovat laajoja kielitieteessä: Dokumenttien vertailu matalaulotteisissa tiloissa (Document Similarity), Toistuvien aiheiden löytäminen dokumenttien väliltä (Topic Modeling), Termien välisten suhteiden löytäminen (Text Synoymity).

Introduction
Latentin semanttisen analyysin malli on teoria siitä, miten merkitys
representaatioita voidaan oppia kohtaamalla suuria kielinäytteitä ilman eksplisiittisiä ohjeita siitä, miten ne rakentuvat.
Käsillä oleva ongelma ei ole valvottu, eli meillä ei ole korpukselle annettuja kiinteitä leimoja tai kategorioita.
LSA noudattaa luonnostaan tiettyjä oletuksia, jotta voimme poimia ja ymmärtää kuvioita dokumenteista:
1) Lauseiden tai dokumenttien merkitys on kaikkien niissä esiintyvien sanojen merkitysten summa. Kaiken kaikkiaan tietyn sanan merkitys on keskiarvo kaikista asiakirjoista, joissa se esiintyy.
2) LSA:ssa oletetaan, että sanojen väliset semanttiset assosiaatiot eivät ole eksplisiittisesti vaan vain piilevästi läsnä suuressa kielinäytteessä.
Matemaattinen näkökulma
Latenttinen semanttinen analyysi (Latent Semantic Analysis, LSA) käsittää tietyt matemaattiset operaatiot, joiden avulla voidaan saada käsitys asiakirjasta. Tämä algoritmi muodostaa aihepiirien mallintamisen perustan. Ydinajatuksena on ottaa matriisi siitä, mitä meillä on – dokumentit ja termit – ja purkaa se erilliseksi dokumentti-aihe-matriisiksi ja aihe-termi-matriisiksi.
Ensimmäinen vaihe on dokumentti-termi-matriisimme luominen Tf-IDF-vektorointiajoa käyttäen. Se voidaan rakentaa myös käyttämällä Bag-of-Words-mallia, mutta tulokset ovat harvalukuisia eivätkä anna mitään merkitystä asialle.
Jos sanastossamme on m dokumenttia ja n-sanaa, voimme rakentaa
m × n-matriisin A, jossa jokainen rivi edustaa dokumenttia ja jokainen sarake sanaa.
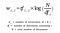
Intuusiivisesti termillä on suuri painoarvo silloin, kun termi esiintyy usein dokumentissa, mutta harvoin korpuksessa.
Muodostamme dokumentti-termi-matriisin A käyttämällä tätä muunnosmenetelmää(tf-IDF) korpuksemme vektoroimiseksi. ( tavalla, jota myöhempi mallimme voi käsitellä tai arvioida, koska emme vielä työskentele merkkijonojen parissa!)
Mutta siinä on hienovarainen haittapuoli, emme voi päätellä mitään tarkkailemalla A:ta, koska se on meluisa ja harva matriisi. ( Joskus liian suuri edes laskettavaksi jatkoprosesseja varten).
Koska teemamallinnus on luonnostaan valvomaton algoritmi, meidän on määriteltävä latentit aiheet etukäteen. Se on analoginen K-Means Clusteringin kanssa siten, että määrittelemme klusterien määrän etukäteen.
Tässä tapauksessa suoritamme Low-Rank Approximation -menetelmän käyttäen dimensioiden pienentämistekniikkaa käyttäen typistettyä Singular Value Decomposition (SVD) -menetelmää.
Singular Value Decomposition on lineaarialgebran tekniikka, joka faktorisoi minkä tahansa matriisin M kolmen erillisen matriisin tuloksi:
Lyhennetty SVD vähentää dimensiota valitsemalla vain t suurinta singulaariarvoa ja säilyttämällä vain U:n ja V:n ensimmäiset t saraketta. Tässä tapauksessa t on hyperparametri, jonka voimme valita ja säätää sen mukaan, kuinka monta aihealuetta haluamme löytää.
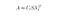
Huomaa: Truncated SVD tekee dimensionaalisuuden vähentämisen eikä SVD:tä!

Näillä dokumenttivektoreilla ja termivektoreilla voimme nyt helposti soveltaa mittareita, kuten kosinin samankaltaisuuden arviointiin:
- erilaisten dokumenttien samankaltaisuutta
- erilaisten sanojen samankaltaisuutta
- termien (tai ”kyselyjen”) ja dokumenttien samankaltaisuutta (mikä tulee hyödylliseksi tiedonhaussa, kun haluamme hakea hakukyselymme kannalta olennaisimmat kohdat).
Loppuhuomautukset
Tätä algoritmia käytetään pääasiassa erilaisissa NLP-pohjaisissa tehtävissä, ja se on perusta vankemmille menetelmille, kuten Probabilistic LSA ja Latent Dirichlet Allocation (LDA).
Kushal Vala, Junior Data Scientist at Datametica Solutions Pvt Ltd
.