
Haluatko organisaatiosi koota ja analysoida tietoja oppiaksesi trendejä, mutta tavalla, joka suojaa yksityisyyttä? Tai ehkä käytät jo eriytettyjä tietosuojatyökaluja, mutta haluat laajentaa (tai jakaa) tietämystäsi? Kummassakin tapauksessa tämä blogisarja on sinulle.
Miksi teemme tämän sarjan? Viime vuonna NIST perusti Privacy Engineering Collaboration Space -yhteistyöalueen, jossa kootaan yhteen avoimen lähdekoodin työkaluja, ratkaisuja ja prosesseja, jotka tukevat yksityisyydensuojan suunnittelua ja riskienhallintaa. Collaboration Space -yhteistyöalueen moderaattoreina olemme auttaneet NIST:iä keräämään erilaisia tietosuojatyökaluja tunnistamisen poistamisen aihealueen alle. NIST on myös julkaissut tietosuojakehyksen: A Tool for Improving Privacy through Enterprise Risk Management (Työkalu yksityisyyden suojan parantamiseen yritysriskien hallinnan avulla) ja siihen liittyvän etenemissuunnitelman, jossa tunnistettiin useita yksityisyyden suojan haastealueita, mukaan lukien tunnistamisen poistamisen aihealue. Nyt haluaisimme hyödyntää Collaboration Space -yhteistyöaluetta auttaaksemme kuromaan umpeen etenemissuunnitelmaan sisältyvän, tunnistamisen poistamista koskevan aukon. Loppupelimme on tukea NIST:iä tämän sarjan muuttamisessa syvällisemmiksi ohjeiksi eriytetystä yksityisyyden suojasta.
Jokainen viesti alkaa käsitteellisillä perusteilla ja käytännön käyttötapauksilla, joiden tarkoituksena on auttaa ammattilaisia, kuten liiketoimintaprosessien omistajia tai yksityisyyden suojaa koskevien ohjelmien henkilöstöä, oppimaan juuri sen verran, että ne voivat olla vaarallisia (vitsi vain). Perusasioiden käsittelyn jälkeen tarkastelemme saatavilla olevia työkaluja ja niiden teknisiä lähestymistapoja yksityisyydensuojan insinööreille tai toteutuksen yksityiskohdista kiinnostuneille IT-ammattilaisille. Jotta kaikki pääsisivät vauhtiin, tässä ensimmäisessä postauksessa annetaan taustatietoa eriytetystä yksityisyyden suojasta ja kuvataan joitakin keskeisiä käsitteitä, joita käytämme sarjan loppuosassa.
Haaste
Kuinka voimme käyttää dataa oppiaksemme tietoa populaatiosta ilman, että saamme tietoa tietyistä yksilöistä populaation sisällä? Tarkastellaan näitä kahta kysymystä:
- ”Kuinka monta ihmistä asuu Vermontissa?”
- ”Kuinka monta Joe Near -nimistä ihmistä asuu Vermontissa?”
Ensimmäinen paljastaa koko populaation ominaisuuden, kun taas jälkimmäinen paljastaa tietoa yhdestä henkilöstä. Meidän on pystyttävä saamaan tietoa väestössä vallitsevista suuntauksista, mutta estettävä samalla mahdollisuus oppia mitään uutta yksittäisestä henkilöstä. Tämä on monien tilastollisten data-analyysien, kuten Yhdysvaltain väestönlaskentatoimiston julkaisemien tilastojen, ja laajemmin koneoppimisen tavoite. Kussakin näistä tilanteista mallien tarkoituksena on paljastaa populaatioiden trendejä, ei heijastaa tietoa yksittäisestä yksilöstä.
Mutta miten voimme vastata ensimmäiseen kysymykseen ”Kuinka monta ihmistä asuu Vermontissa?”. – jota kutsumme kyselyksi – samalla kun estämme vastaamasta toiseen kysymykseen ”Kuinka monta ihmistä nimeltä Joe Near asuu Vermontissa?”. Yleisimmin käytetty ratkaisu on niin sanottu tunnistamisen poistaminen (tai anonymisointi), jossa tunnistetiedot poistetaan tietokokonaisuudesta. (Oletamme yleensä, että tietokokonaisuus sisältää tietoja, jotka on kerätty monilta henkilöiltä). Toinen vaihtoehto on sallia vain aggregoidut kyselyt, kuten tietojen keskiarvo. Valitettavasti tiedämme nyt, että kumpikaan lähestymistapa ei todellisuudessa tarjoa vahvaa yksityisyyden suojaa. Tunnistamattomia tietokokonaisuuksia vastaan voidaan hyökätä tietokantayhteyksien avulla. Aggregointi suojaa yksityisyyttä vain, jos aggregoitavat ryhmät ovat riittävän suuria, ja silloinkin yksityisyyshyökkäykset ovat mahdollisia.
Differentiaalinen yksityisyys
Differentiaalinen yksityisyys on matemaattinen määritelmä siitä, mitä yksityisyys tarkoittaa. Se ei ole tietty prosessi, kuten tunnistuksen poistaminen, vaan ominaisuus, joka prosessilla voi olla. On esimerkiksi mahdollista todistaa, että tietty algoritmi ”täyttää” differentiaalisen yksityisyyden suojan.
Informaalisesti differentiaalinen yksityisyys takaa jokaiselle yksilölle, joka antaa tietoja analyysiä varten, seuraavan: differentiaalisesti yksityisen analyysin tulos on suunnilleen sama riippumatta siitä, annatko tietosi vai et. Differentiaalisesti yksityistä analyysia kutsutaan usein mekanismiksi, ja merkitsemme sitä ℳ.
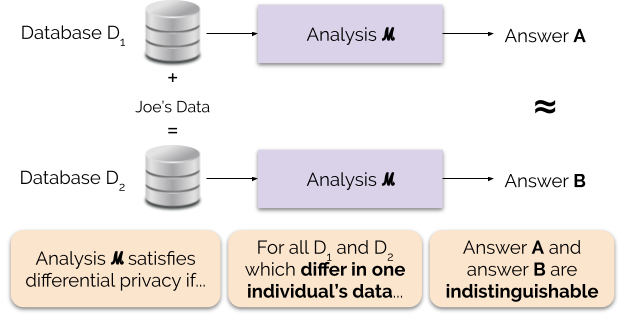
Kuvio 1 havainnollistaa tätä periaatetta. Vastaus ”A” lasketaan ilman Joen tietoja, kun taas vastaus ”B” lasketaan Joen tietojen avulla. Differentiaalinen yksityisyys sanoo, että näiden kahden vastauksen pitäisi olla erottamattomia. Tämä tarkoittaa, että kuka tahansa, joka näkee tuloksen, ei pysty kertomaan, käytettiinkö Joen tietoja vai ei, tai mitä Joen tiedot sisälsivät.
Hallitsemme yksityisyystakuun voimakkuutta virittämällä yksityisyysparametrin ε, jota kutsutaan myös yksityisyyshäviöksi tai yksityisyysbudjetiksi. Mitä pienempi ε-parametrin arvo on, sitä erottamattomammat tulokset ovat, ja näin ollen sitä enemmän kunkin yksilön tietoja suojataan.
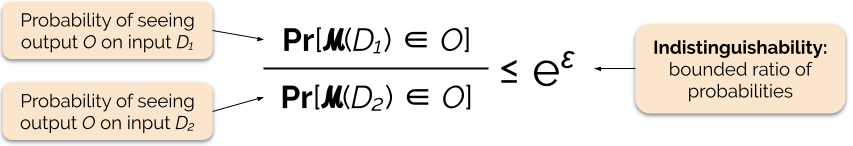
Voimme usein vastata kyselyyn differentiaalisella yksityisyydellä lisäämällä kyselyvastaukseen jonkin verran satunnaista kohinaa. Haasteena on määrittää, mihin kohinaa lisätään ja kuinka paljon. Yksi yleisimmin käytetyistä mekanismeista kohinan lisäämiseen on Laplace-mekanismi .
Kyselyt, joilla on suurempi herkkyys, vaativat suuremman kohinan lisäämistä, jotta tietty erisuuntaisen yksityisyyden ”epsilon”-suuruus täyttyisi, ja tämä ylimääräinen kohina voi tehdä tuloksista vähemmän käyttökelpoisia. Kuvaamme herkkyyttä ja tätä yksityisyyden ja hyödyllisyyden välistä kompromissia yksityiskohtaisemmin tulevissa blogikirjoituksissa.
Differentiaalisen yksityisyyden edut
Differentiaalisella yksityisyydellä on useita merkittäviä etuja aiempiin yksityisyystekniikoihin verrattuna:
- Se olettaa, että kaikki tieto on tunnistetietoa, mikä eliminoi haastavan (ja toisinaan myös mahdottoman) tehtävän, jonka tarkoituksena on huomioida kaikki datan tunnistetiedot.
- Se on vastustuskykyinen aputietoihin perustuville yksityisyyshyökkäyksille, joten sillä voidaan tehokkaasti estää linkityshyökkäykset, jotka ovat mahdollisia tunnistamattomille tiedoille.
- Se on kompositionaalinen – voimme määrittää yksityisyyden suojan menetyksen, joka aiheutuu siitä, että suoritamme kahta eri tavoin yksityistä suojaa vaativaa analyysiä samoille tiedoille, yksinkertaisesti laskemalla yhteen näiden kahden analyysin yksittäiset yksityisyyden suojan menetykset. Kompositionaalisuus tarkoittaa, että voimme antaa mielekkäitä takeita yksityisyydestä, vaikka julkaisisimme useita analyysituloksia samasta datasta. Tekniikat, kuten tunnistamisen poistaminen, eivät ole kompositionaalisia, ja useat julkaisut näillä tekniikoilla voivat johtaa katastrofaaliseen yksityisyyden menetykseen.
Nämä edut ovat ensisijaisia syitä siihen, miksi ammattilainen saattaa valita eriytetyn yksityisyyden suojan jonkin muun tietosuojaa koskevan tekniikan sijaan. Differentiaalisen yksityisyyden suojan haittapuolena on tällä hetkellä se, että se on melko uusi, eikä vankkoja työkaluja, standardeja ja parhaita käytäntöjä ole helposti saatavilla akateemisten tutkimusyhteisöjen ulkopuolella. Ennustamme kuitenkin, että tämä rajoitus voidaan voittaa lähitulevaisuudessa, koska vankkojen ja helppokäyttöisten tietosuojaratkaisujen kysyntä kasvaa.
Seuraava
Pysy kuulolla: seuraava kirjoituksemme rakentuu tälle kirjoitukselle tutkimalla tietoturvakysymyksiä, jotka liittyvät differentiaalisen yksityisyyden suojaa käyttävien järjestelmien käyttöönottoon, mukaan lukien differentiaalisen yksityisyyden suojan keskitetyn ja lokaalin mallin ero.
Etukäteen – haluamme, että tämä kirjoitussarja ja myöhemmät NIST:n ohjeet myötävaikuttavat osaltaan differentiaalisen yksityisyyden suojaa koskevan tiedon saatavuuden parantamiseen. Sinä voit auttaa. Riippumatta siitä, onko sinulla kysyttävää näistä viesteistä tai voitko jakaa tietämystäsi, toivomme, että osallistut kanssamme, jotta voimme yhdessä edistää tätä tieteenalaa.
Garfinkel, Simson, John M. Abowd ja Christian Martindale. ”Understanding database reconstruction attacks on public data”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. ”When the signal is in the noise: exploiting diffix’s sticky noise”. 28. USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit ja Kobbi Nissim. ”Tietojen paljastaminen yksityisyyden säilyttäen”. Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. ”Yksinkertaiset demografiset tiedot tunnistavat ihmiset usein yksiselitteisesti.” Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. ”Calibrating noise to sensitivity in private data analysis”. Theory of cryptography -konferenssi. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke ja Salil Vadhan. ”Differentiaalinen yksityisyys: A primer for a non-technical audience.” Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia ja Aaron Roth. ”Differentiaalisen yksityisyyden algoritmiset perusteet”. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.