
¿Su organización desea agregar y analizar datos para conocer tendencias, pero de una manera que proteja la privacidad? O tal vez ya está utilizando herramientas de privacidad diferenciales, pero quiere ampliar (o compartir) sus conocimientos? En cualquier caso, esta serie de blogs es para usted.
¿Por qué estamos haciendo esta serie? El año pasado, el NIST lanzó un Espacio de Colaboración de Ingeniería de Privacidad para agregar herramientas, soluciones y procesos de código abierto que apoyan la ingeniería de privacidad y la gestión de riesgos. Como moderadores del Espacio de Colaboración, hemos ayudado al NIST a reunir herramientas de privacidad diferenciales bajo el área temática de la desidentificación. El NIST también ha publicado el Privacy Framework: Una herramienta para mejorar la privacidad a través de la gestión del riesgo empresarial y una hoja de ruta complementaria que reconoce una serie de áreas de desafío para la privacidad, incluyendo el tema de la desidentificación. Ahora nos gustaría aprovechar el Espacio de Colaboración para ayudar a cerrar la brecha de la hoja de ruta sobre la desidentificación. Nuestro objetivo final es ayudar al NIST a convertir esta serie en directrices más profundas sobre la privacidad diferencial.
Cada post comenzará con los fundamentos conceptuales y los casos de uso práctico, con el objetivo de ayudar a los profesionales, como los propietarios de los procesos empresariales o el personal de los programas de privacidad, a aprender lo suficiente para ser peligrosos (es una broma). Después de cubrir los fundamentos, veremos las herramientas disponibles y sus enfoques técnicos para los ingenieros de privacidad o los profesionales de TI interesados en los detalles de la implementación. Para que todo el mundo se ponga al día, esta primera entrada proporcionará antecedentes sobre la privacidad diferencial y describirá algunos conceptos clave que utilizaremos en el resto de la serie.
El reto
¿Cómo podemos utilizar los datos para aprender sobre una población, sin aprender sobre individuos específicos dentro de la población? Considere estas dos preguntas:
- «¿Cuántas personas viven en Vermont?»
- «¿Cuántas personas llamadas Joe Near viven en Vermont?»
La primera revela una propiedad de toda la población, mientras que la segunda revela información sobre una persona. Tenemos que ser capaces de aprender sobre las tendencias de la población al tiempo que evitamos la capacidad de aprender algo nuevo sobre un individuo en particular. Este es el objetivo de muchos análisis estadísticos de datos, como las estadísticas publicadas por la Oficina del Censo de Estados Unidos, y del aprendizaje automático en general. En cada uno de estos entornos, los modelos pretenden revelar tendencias en las poblaciones, no reflejar información sobre un solo individuo.
Pero ¿cómo podemos responder a la primera pregunta «¿Cuántas personas viven en Vermont?» – a la que nos referiremos como consulta- y al mismo tiempo evitar que se responda a la segunda pregunta «¿Cuántas personas de nombre Joe Near viven en Vermont?». La solución más utilizada es la llamada desidentificación (o anonimización), que elimina la información de identificación del conjunto de datos. (Por lo general, asumiremos que un conjunto de datos contiene información recogida de muchos individuos). Otra opción es permitir sólo consultas agregadas, como una media de los datos. Desgraciadamente, ahora entendemos que ninguno de los dos enfoques proporciona realmente una fuerte protección de la privacidad. Los conjuntos de datos desidentificados están sujetos a ataques de vinculación de bases de datos. La agregación sólo protege la privacidad si los grupos que se agregan son lo suficientemente grandes, e incluso entonces, los ataques a la privacidad siguen siendo posibles.
Privacidad diferencial
La privacidad diferencial es una definición matemática de lo que significa tener privacidad. No es un proceso específico como la desidentificación, sino una propiedad que puede tener un proceso. Por ejemplo, es posible demostrar que un algoritmo específico «satisface» la privacidad diferencial.
Informalmente, la privacidad diferencial garantiza lo siguiente para cada individuo que contribuye con datos para el análisis: el resultado de un análisis diferencialmente privado será aproximadamente el mismo, independientemente de que usted contribuya o no con sus datos. Un análisis diferencialmente privado suele llamarse mecanismo, y lo denotamos ℳ.
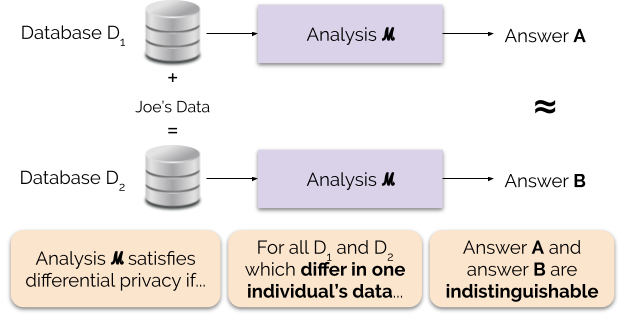
La figura 1 ilustra este principio. La respuesta «A» se calcula sin los datos de Joe, mientras que la respuesta «B» se calcula con los datos de Joe. La privacidad diferencial dice que las dos respuestas deben ser indistinguibles. Esto implica que quien vea el resultado no podrá saber si se usaron o no los datos de Joe, o qué contenían los datos de Joe.
Controlamos la fuerza de la garantía de privacidad ajustando el parámetro de privacidad ε, también llamado pérdida de privacidad o presupuesto de privacidad. Cuanto menor sea el valor del parámetro ε, más indistinguibles serán los resultados y, por tanto, más protegidos estarán los datos de cada individuo.
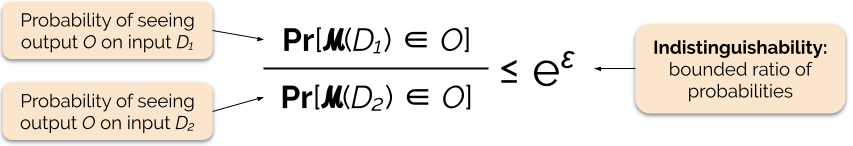
A menudo podemos responder a una consulta con privacidad diferencial añadiendo algo de ruido aleatorio a la respuesta de la consulta. El reto consiste en determinar dónde añadir el ruido y cuánto añadir. Uno de los mecanismos más utilizados para añadir ruido es el mecanismo de Laplace .
Las consultas con mayor sensibilidad requieren la adición de más ruido para satisfacer una cantidad particular de «epsilon» de privacidad diferencial, y este ruido extra tiene el potencial de hacer que los resultados sean menos útiles. Describiremos la sensibilidad y este compromiso entre privacidad y utilidad con más detalle en futuras entradas del blog.
Beneficios de la privacidad diferencial
La privacidad diferencial tiene varias ventajas importantes sobre las técnicas de privacidad anteriores:
- Asume que toda la información es información de identificación, eliminando la difícil (y a veces imposible) tarea de contabilizar todos los elementos de identificación de los datos.
- Es resistente a los ataques a la privacidad basados en la información auxiliar, por lo que puede prevenir eficazmente los ataques de vinculación que son posibles en los datos desidentificados.
- Es composicional: podemos determinar la pérdida de privacidad de ejecutar dos análisis diferencialmente privados en los mismos datos simplemente sumando las pérdidas de privacidad individuales de los dos análisis. La composicionalidad significa que podemos hacer garantías significativas sobre la privacidad incluso cuando se liberan los resultados de múltiples análisis de los mismos datos. Las técnicas como la desidentificación no son compositivas, y la publicación múltiple con estas técnicas puede dar lugar a una pérdida catastrófica de privacidad.
Estas ventajas son las principales razones por las que un profesional podría elegir la privacidad diferencial en lugar de alguna otra técnica de privacidad de datos. Uno de los inconvenientes actuales de la privacidad diferencial es que es bastante nueva, y no es fácil acceder a herramientas sólidas, estándares y mejores prácticas fuera de las comunidades de investigación académica. Sin embargo, predecimos que esta limitación puede superarse en un futuro próximo debido a la creciente demanda de soluciones robustas y fáciles de usar para la privacidad de datos.
Próximo artículo
Esté atento: nuestro próximo artículo se basará en este explorando los problemas de seguridad que implica el despliegue de sistemas para la privacidad diferencial, incluyendo la diferencia entre los modelos central y local de la privacidad diferencial.
Antes de irnos – queremos que esta serie y las subsiguientes directrices del NIST contribuyan a hacer más accesible la privacidad diferencial. Usted puede ayudar. Tanto si tienes preguntas sobre estos posts como si puedes compartir tus conocimientos, esperamos que te comprometas con nosotros para que podamos avanzar juntos en esta disciplina.
Garfinkel, Simson, John M. Abowd y Christian Martindale. «Understanding database reconstruction attacks on public data». Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. «Cuando la señal está en el ruido: explotando el ruido pegajoso de diffix». 28º Simposio de Seguridad de USENIX (USENIX Security 19). 2019.
Dinur, Irit, y Kobbi Nissim. «Revelando información mientras se preserva la privacidad». Actas del vigésimo segundo simposio ACM SIGMOD-SIGACT-SIGART sobre Principios de sistemas de bases de datos. 2003.
Sweeney, Latanya. «Los datos demográficos simples suelen identificar a las personas de forma única». Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. «Calibrating noise to sensitivity in private data analysis». Conferencia sobre teoría de la criptografía. Springer, Berlín, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, y Salil Vadhan. «Privacidad diferencial: Un manual para un público no técnico». Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, y Aaron Roth. «Los fundamentos algorítmicos de la privacidad diferencial». Fundamentos y tendencias en informática teórica 9, no. 3-4 (2014): 211-407.