Locality-sensitive hashing
Objetivo: Encontrar documentos con una similitud de Jaccard de al menos t
La idea general de LSH es encontrar un algoritmo tal que si introducimos las firmas de 2 documentos, nos diga que esos 2 documentos forman un par candidato o no, es decir, que su similitud es mayor que un umbral t. Recordemos que estamos tomando la similitud de las firmas como un proxy de la similitud de Jaccard entre los documentos originales.
Específicamente para la matriz de firmas min-hash:
- Hacemos un hash de las columnas de la matriz de firmas M usando varias funciones hash
- Si 2 documentos hacen hash en el mismo cubo para al menos una de las funciones hash podemos tomar los 2 documentos como un par candidato
Ahora la cuestión es cómo crear diferentes funciones hash. Para ello hacemos la partición de bandas.
Partición de bandas

Aquí está el algoritmo:
- Dividir la matriz de firmas en b bandas, cada banda tiene filas
- Para cada banda, hash de su porción de cada columna a una tabla de hash con k cubos
- Los pares de columnas candidatos son los que hash a la misma cubeta para al menos 1 banda
- Tune b y r para atrapar la mayoría de los pares similares pero pocos pares no similares
Hay algunas consideraciones aquí. Idealmente, para cada banda queremos que k sea igual a todas las posibles combinaciones de valores que puede tomar una columna dentro de una banda. Esto será equivalente a la coincidencia de identidades. Pero de esta manera k será un número enorme que es computacionalmente inviable. Por ejemplo: Si para una banda tenemos 5 filas en ella. Ahora bien, si los elementos de la firma son enteros de 32 bits entonces k en este caso será (2³²)⁵ ~ 1,4615016e+48. Puedes ver cuál es el problema aquí. Normalmente k se toma alrededor de 1 millón.
La idea es que si 2 documentos son similares entonces aparecerán como par candidato en al menos una de las bandas.
Elección de b & r
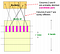
Si tomamos b grande, es decir, más número de funciones hash, entonces reducimos r ya que b*r es una constante (número de filas en la matriz de firmas). Intuitivamente significa que estamos aumentando la probabilidad de encontrar un par de candidatos. Este caso es equivalente a tomar un pequeño t (umbral de similitud)
Digamos que tu matriz de firmas tiene 100 filas. Consideremos 2 casos:
b1 = 10 → r = 10
b2 = 20 → r = 5
En el segundo caso, hay más posibilidades de que 2 documentos aparezcan en el mismo cubo al menos una vez ya que tienen más oportunidades (20 frente a 10) y se están comparando menos elementos de la firma (5 frente a 10).
Un b más alto implica un umbral de similitud más bajo (falsos positivos más altos) y un b más bajo implica un umbral de similitud más alto (falsos negativos más altos)
Intentemos entender esto a través de un ejemplo.
Configuración:
- 100k documentos almacenados como firma de longitud 100
- Matriz de firma: 100*100000
- La comparación por fuerza bruta de las firmas dará lugar a 100C2 comparaciones = 5.000 millones (¡bastante!)
- Tomemos b = 20 → r = 5
Triunfo de similitud (t) : 80%
Queremos que 2 documentos (D1 & D2) con un 80% de similitud estén hash en el mismo cubo para al menos una de las 20 bandas.
P(D1 & D2 idénticos en una banda concreta) = (0,8)⁵ = 0,328
P(D1 & D2 no son similares en las 20 bandas) = (1-0,328)^20 = 0,00035
Esto significa que en este escenario tenemos ~.035% de posibilidades de un falso negativo @ 80% de documentos similares.
También queremos que 2 documentos (D3 & D4) con un 30% de similitud no estén hash en el mismo cubo para ninguna de las 20 bandas (umbral = 80%).
P(D3 & D4 idénticos en una banda concreta) = (0,3)⁵ = 0.00243
P(D3 & D4 son similares en al menos una de las 20 bandas) = 1 – (1-0.00243)^20 = 0.0474
Esto significa que en este escenario tenemos ~4.74% de posibilidades de un falso positivo @ 30% de documentos similares.
Así que podemos ver que tenemos algunos falsos positivos y pocos falsos negativos. Esta proporción variará con la elección de b y r.
Lo que queremos aquí es algo como lo siguiente. Si tenemos 2 documentos que tienen una similitud mayor que el umbral, entonces la probabilidad de que compartan el mismo cubo en al menos una de las bandas debe ser 1, si no, 0.

El peor caso será si tenemos b = número de filas en la matriz de firmas como se muestra a continuación.

El caso generalizado para cualquier b y r se muestra a continuación.

Elija b y r para obtener la mejor curva S i.e tasa mínima de falsos negativos y falsos positivos

Resumen de LSH
- Ajuste M, b, r para obtener casi todos los pares de documentos con firmas similares, pero eliminar la mayoría de los pares que no tienen firmas similares
- Comprobar en la memoria principal que los pares candidatos realmente tienen firmas similares