Disclaimer 1 : Este artículo es sólo una introducción a las características de MFCC y está destinado a aquellos que necesitan una comprensión fácil y rápida de la misma. No se discuten las matemáticas detalladas ni las complejidades.
Al no haber trabajado nunca en el área del procesamiento del habla, al recordar la palabra «MFCC» (utilizada a menudo por los compañeros) me quedé con la comprensión inadecuada de que es el nombre dado a un tipo particular de «característica» extraída de las señales de audio (similar a los bordes que constituyen un tipo de característica extraída de las imágenes).


Características extraídas de señales de voz. Me costó bastante leer de varias fuentes para entender lo que son las características MFCC. Así que he decidido ayudar a los compañeros que lo necesitan recopilando la información que he recogido de una manera fácil de entender.
Empecemos por ampliar el acrónimo MFCC – Mel Frequency Cepstral Co-efficients.
¿Has oído alguna vez la palabra cepstral? Probablemente no. Es espectral con la especificación invertida. ¿Pero por qué? Para una comprensión muy básica, el cepstrum es la información de la tasa de cambio en las bandas espectrales. En el análisis convencional de las señales temporales, cualquier componente periódico (por ejemplo, los ecos) aparece como picos agudos en el espectro de frecuencias correspondiente (es decir, el espectro de Fourier. Éste se obtiene aplicando una transformada de Fourier a la señal temporal). Esto se puede ver en la siguiente imagen.

Al tomar el logaritmo de la magnitud de este espectro de Fourier y, a continuación, volver a tomar el espectro de este logaritmo mediante una transformación del coseno (sé que parece complicado, pero ¡tenga paciencia conmigo, por favor!), observamos un pico allí donde hay un elemento periódico en la señal temporal original. Dado que aplicamos una transformación sobre el propio espectro de frecuencias, el espectro resultante no está ni en el dominio de la frecuencia ni en el dominio del tiempo, por lo que Bogert et al. decidieron llamarlo el dominio de la quefrecuencias. Y a este espectro del logaritmo del espectro de la señal temporal lo denominaron cepstrum (¡ta-da!).
La siguiente imagen es un resumen de los pasos explicados anteriormente.

El cepstrum se introdujo por primera vez para caracterizar los ecos sísmicos resultantes debido a los terremotos.
El tono es una de las características de una señal de voz y se mide como la frecuencia de la señal. La escala Mel es una escala que relaciona la frecuencia percibida de un tono con la frecuencia real medida. La escala de Mel es una escala que relaciona la frecuencia percibida de un tono con la frecuencia real medida. Esta escala se ha obtenido a partir de conjuntos de experimentos con sujetos humanos. Permítame darle una explicación intuitiva de lo que capta la escala mel.
El rango de la audición humana es de 20Hz a 20kHz. Imagina una melodía a 300 Hz. Esto sonaría algo así como el tono de marcación estándar de un teléfono fijo. Ahora imagine una melodía a 400 Hz (un tono de marcación un poco más alto). Compare la distancia entre ambos, sea cual sea la percepción de su cerebro. Ahora imagine una señal de 900 Hz (similar al sonido de retroalimentación de un micrófono) y un sonido de 1kHz. La distancia percibida entre estos dos sonidos puede parecer mayor que la de los dos primeros, aunque la diferencia real sea la misma (100 Hz). La escala mel trata de captar estas diferencias. Una frecuencia medida en Hertz (f) puede convertirse a la escala Mel mediante la siguiente fórmula :
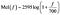
Cualquier sonido generado por los seres humanos está determinado por la forma de su tracto vocal (incluyendo la lengua, los dientes, etc). Si esta forma puede determinarse correctamente, cualquier sonido producido puede representarse con precisión. La envolvente del espectro de potencia temporal de la señal de voz es representativa del tracto vocal y la MFCC (que no es más que los coeficientes que componen el cepstrum de frecuencias Mel) representa con precisión esta envolvente. El siguiente diagrama de bloques es un resumen paso a paso de cómo llegamos a los MFCC:
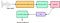
Aquí, el Banco de Filtros se refiere a los filtros mel (que cubren la escala mel) y los Coeficientes Cepstrales no son otra cosa que los MFCC.
TL; DR – Los rasgos MFCC representan fonemas (unidades distintas de sonido) ya que en ellos se manifiesta la forma del tracto vocal (responsable de la generación del sonido).
Disclaimer 2 : Todas las imágenes son de Google images.