Myanmar es actualmente el único país del mundo con una presencia significativa en Internet que no se ha estandarizado con Unicode, el estándar internacional de codificación de texto. En su lugar, Zawgyi es el tipo de letra dominante utilizado para codificar los caracteres de la lengua birmana. Esta falta de una norma única ha provocado problemas técnicos para muchas empresas que ofrecen aplicaciones y servicios móviles en Myanmar. Dificulta la comunicación en las plataformas digitales, ya que el contenido escrito en Unicode aparece confuso para los usuarios de Zawgyi y viceversa. Esto es un problema para aplicaciones como Facebook y Messenger, ya que las publicaciones, los mensajes y los comentarios escritos en una codificación no son legibles en otra. La falta de estandarización en torno a Unicode dificulta la automatización y la detección proactiva de los contenidos infractores, puede debilitar la seguridad de las cuentas, hace que la denuncia de contenidos potencialmente dañinos en Facebook sea menos eficaz y supone una menor compatibilidad con los idiomas de Myanmar más allá del birmano.
El año pasado, para apoyar la transición de Myanmar a Unicode, eliminamos el zawgyi como opción de idioma de la interfaz para los nuevos usuarios de Facebook. A continuación, nos aseguramos de que nuestros clasificadores de discursos de odio y otros contenidos que violan las políticas no tropezaran con el contenido Zawgyi y comenzamos a trabajar en la integración de convertidores de fuentes para mejorar la experiencia del contenido en los dispositivos Unicode. Hoy, para ayudar al país a continuar su transición a Unicode, anunciamos que hemos implementado convertidores de fuentes en Facebook y Messenger. Como sabemos que esta transición llevará tiempo, nuestro convertidor de Zawgyi a Unicode continuará permitiendo a las personas que están haciendo la transición a Unicode leer las publicaciones, los mensajes y los comentarios aunque sus amigos y familiares aún no hayan hecho la transición en sus dispositivos. Este post detallará los desafíos técnicos que implica la integración de estos convertidores, incluyendo cómo diferenciamos el texto Zawgyi del Unicode, cómo podemos saber si un dispositivo utiliza Zawgyi o Unicode, y cómo convertir entre los dos, así como algunas lecciones que hemos aprendido en el camino.
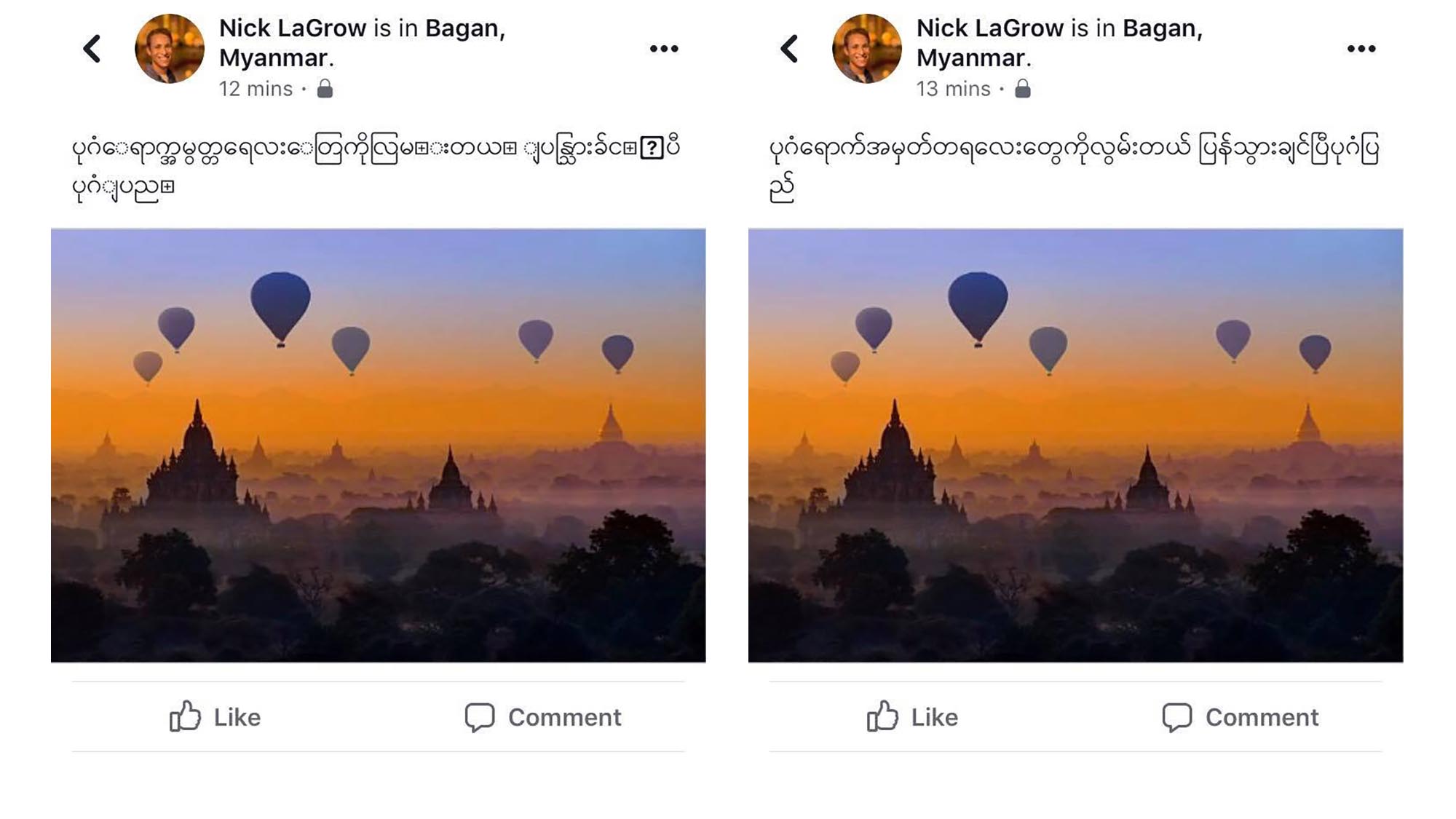
¿Por qué Unicode?
Unicode se diseñó como un sistema global para que todos los habitantes del mundo pudieran utilizar su propio idioma en sus dispositivos. Pero la mayoría de los dispositivos en Myanmar todavía utilizan Zawgyi, que es incompatible con Unicode. Lo que significa que las personas que utilizan esos dispositivos se enfrentan ahora a problemas de compatibilidad entre plataformas, sistemas operativos y lenguajes de programación. Para llegar mejor a su público, los productores de contenidos en Myanmar suelen publicar en Zawgyi y en Unicode en una misma entrada, sin olvidar el inglés u otros idiomas. La codificación Zawgyi utiliza múltiples puntos de código para los caracteres y las representaciones combinadas; requiere el doble de puntos de código para representar sólo un subconjunto de la escritura; y los puntos de código de las vocales pueden aparecer antes o después de una consonante (por lo que CAT o CTA se leen igual), lo que provoca problemas de búsqueda y comparación, incluso dentro de un mismo documento. Esto hace que cualquier tipo de comunicación entre sistemas sea un gran reto.
Facebook apoya Unicode porque ofrece soporte y un estándar consistente para todos los idiomas. En Myanmar, en particular, apoyamos la transición a Unicode porque:
- Permite a los habitantes de Myanmar utilizar nuestras aplicaciones y servicios en otros idiomas además del birmano. Zawgyi solo admite la introducción de texto en birmano, mientras que Unicode permite introducir las lenguas minoritarias que se hablan en Myanmar, como el shan y el mon.
- Ofrece una forma normalizada para las lenguas de Myanmar, lo que nos ayuda a proteger a las personas que utilizan nuestras aplicaciones detectando el contenido que viola las políticas y mejora enormemente el rendimiento de las herramientas de búsqueda.
- Hace que sea más eficiente para nosotros revisar los informes de contenido potencialmente dañino en Facebook, y los revisores de contenido podrán revisar los problemas sin necesidad de saber cómo se codificó el contenido.
Un enfoque triple
Cuando empezamos a estudiar la codificación de Myanmar, nuestra principal prioridad era asegurarnos de que nuestros sistemas que detectan el contenido dañino, como el discurso de odio, no tropezaran con Zawgyi. Explicamos nuestros objetivos al respecto en esta entrada del blog. Los mismos retos (como los múltiples puntos de código y las representaciones combinadas) que dificultan la comunicación de los sistemas mediante Zawgyi también dificultan el entrenamiento de nuestros clasificadores y sistemas de IA para detectar eficazmente los contenidos que violan las políticas.
Afortunadamente, no somos la única empresa que está trabajando en este tema, y pudimos utilizar la biblioteca de código abierto myanmar-tools de Google para implementar nuestra solución. La biblioteca myanmar-tools fue una mejora importante, en términos de precisión de detección y conversión, sobre la biblioteca basada en regex que habíamos estado utilizando. Hace aproximadamente un año, integramos la detección y conversión de fuentes para convertir todo el contenido en Unicode antes de pasar por nuestros clasificadores. Implementar la autoconversión en todos nuestros productos no fue una tarea sencilla. Cada uno de los requisitos para la autoconversión -detección de la codificación del contenido, detección de la codificación del dispositivo y conversión- tenía sus propios retos.
Detección de la codificación del contenido
Para realizar la autoconversión, primero necesitamos conocer la codificación del contenido, es decir, la codificación utilizada cuando se introdujo el texto por primera vez. Lamentablemente, Zawgyi y Unicode utilizan el mismo rango de puntos de código para representar los caracteres en birmano y otros idiomas. Por ello, no podemos saber si una lista de puntos de código que representa una cadena debe representarse con Zawgyi o con Unicode. Además, no todas las cadenas de puntos de código tienen sentido en ambas codificaciones. Con un modelo entrenado en texto creado en Zawgyi y Unicode, podemos evaluar la probabilidad de que una cadena dada fue creada con un teclado Zawgyi o Unicode.

Nuestra detección se basa en el enfoque de la biblioteca myanmar-tools. Entrenamos un modelo de aprendizaje automático (ML) en muestras de contenido público de Facebook del que ya conocemos la codificación del contenido. Este modelo hace un seguimiento de la probabilidad de que una serie de puntos de código aparezca en Unicode y en Zawgyi para cada muestra. Más tarde, al determinar la codificación del contenido de una persona, nos fijamos en la predicción del modelo para saber si es más probable que esa secuencia de puntos de código se haya introducido en Unicode o en Zawgyi, y utilizamos ese resultado como codificación del contenido.
Detección de la codificación del dispositivo
A continuación, necesitamos saber qué codificación utilizó el teléfono de una persona (es decir, la codificación del dispositivo) para saber si tenemos que realizar una conversión de la codificación de la fuente. Para ello, podemos aprovechar el hecho de que en una codificación, la combinación de varios puntos de código combinará fragmentos de texto para crear un único carácter, mientras que en la otra codificación esos dos puntos de código podrían representar caracteres separados. Si creamos una cadena en el dispositivo y comprobamos el ancho de esa cadena, podemos saber qué codificación de fuente está utilizando el dispositivo para representar la cadena. Una vez que tengamos esta información, podremos indicar al servidor, en futuras peticiones web, que el dispositivo está utilizando Zawgyi o Unicode y asegurarnos de que cualquier contenido que se obtenga coincida. En Myanmar, nuestra lógica del lado del cliente determina si el dispositivo en cuestión es Zawgyi o Unicode y envía esa codificación como parte del campo locale en la solicitud web (por ejemplo, my_Qaag_MM).
Conversión
A continuación, el servidor comprueba si está cargando contenido en birmano. Si la codificación del contenido y la del dispositivo no coinciden, hay que convertir el contenido a un formato que el dispositivo del lector pueda representar correctamente. Por ejemplo, si una entrada se introdujo con una codificación de contenido Unicode, pero se está leyendo en un dispositivo con codificación Zawgyi, convertimos el texto de la entrada a Zawgyi antes de renderizarlo en el dispositivo Zawgyi.
Es importante entrenar este modelo en el contenido de Facebook en lugar de en otros contenidos de acceso público en la web. La gente escribe de forma diferente en Facebook que en una página web o en un artículo académico: Los mensajes de Facebook suelen ser más cortos y menos formales, y contienen abreviaturas, jerga y errores tipográficos. Queremos que nuestras predicciones sean lo más precisas posible para el contenido que la gente comparte y lee en nuestras aplicaciones.
Integración de la autoconversión a escala de Facebook
El siguiente reto era integrar esta conversión en los diferentes tipos de contenido que la gente puede crear en nuestras aplicaciones. El texto Zawgyi se ha introducido para las actualizaciones de estado, así como para los nombres de usuario, los comentarios, los subtítulos de los vídeos, los mensajes privados, etc. Ejecutar nuestra detección y conversión cada vez que alguien obtiene cualquier tipo de contenido sería prohibitivo en términos de tiempo y recursos necesarios. No hay un único conducto por el que pase todo el contenido posible de Facebook, lo que hace difícil capturar el contenido de Zawgyi en todos los lugares en los que alguien pueda entrar. Además, no todas las solicitudes web se realizan desde el dispositivo de una persona. Por ejemplo, cuando las notificaciones y los mensajes se envían a los dispositivos, no podemos ejecutar la lógica de codificación del dispositivo. Además, los mensajes y los comentarios suelen ser muy cortos, lo que reduce la precisión de la detección.
El convertidor de fuentes ya está totalmente implementado en Facebook y Messenger. Estas herramientas supondrán una gran diferencia para los millones de personas de Myanmar que utilizan nuestras aplicaciones para comunicarse con sus amigos y familiares. Para seguir apoyando a los habitantes de Myanmar en esta transición a Unicode, estamos estudiando la posibilidad de ampliar nuestras herramientas de autoconversión a más productos de la familia de Facebook, así como de mejorar la calidad de nuestra detección y conversión automáticas. También tenemos la intención de seguir contribuyendo a la biblioteca de código abierto myanmar-tools para ayudar a otros a construir herramientas para apoyar esta transición.