¡Hola amigos! En este artículo, voy a describir un algoritmo utilizado en el Procesamiento del Lenguaje Natural: El Análisis Semántico Latente ( LSA ).
Las principales aplicaciones de este método mencionado son de gran alcance en la lingüística: Comparar los documentos en espacios de baja dimensión (Similitud de Documentos), Encontrar temas recurrentes a través de documentos (Modelado de Temas), Encontrar relaciones entre términos (Sinoymidad de Texto).

Introducción
El modelo de Análisis Semántico Latente es una teoría sobre cómo las representaciones de significado
podrían ser aprendidas a partir del encuentro con grandes muestras de lenguaje sin indicaciones explícitas sobre cómo está estructurado.
El problema en cuestión no está supervisado, es decir, no tenemos etiquetas o categorías fijas asignadas al corpus.
Para extraer y comprender patrones de los documentos, el LSA sigue intrínsecamente ciertos supuestos:
1) El significado de las oraciones o documentos es una suma del significado de todas las palabras que aparecen en él. En general, el significado de una determinada palabra es una media de todos los documentos en los que aparece.
2) El LSA asume que las asociaciones semánticas entre las palabras no están presentes de forma explícita, sino sólo de forma latente en la gran muestra de lenguaje.
Perspectiva matemática
El Análisis Semántico Latente (LSA) se compone de ciertas operaciones matemáticas para obtener información sobre un documento. Este algoritmo constituye la base del Modelado Temático. La idea central es tomar una matriz de lo que tenemos -documentos y términos- y descomponerla en una matriz documento-tema separada y una matriz tema-término.
El primer paso es generar nuestra matriz documento-término utilizando el Vectorizador Tf-IDF. También se puede construir utilizando un Modelo de Bolsa de Palabras, pero los resultados son escasos y no aportan ninguna importancia al asunto.
Dados m documentos y n-palabras en nuestro vocabulario, podemos construir una
m × n matriz A en la que cada fila representa un documento y cada columna representa una palabra.
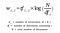
Intuitivamente, un término tiene un gran peso cuando aparece con frecuencia en el documento pero con poca frecuencia en el corpus.
Formamos una matriz documento-término, A, utilizando este método de transformación (tf-IDF) para vectorizar nuestro corpus. (De manera que nuestro modelo posterior pueda procesar o evaluar, ya que todavía no trabajamos con cadenas).
Pero hay un sutil inconveniente, no podemos inferir nada observando A, ya que es una matriz ruidosa y escasa. (A veces demasiado grande incluso para computar para otros procesos).
Dado que el Modelado de Tópicos es inherentemente un algoritmo no supervisado, tenemos que especificar los temas latentes de antemano. Es análogo al K-Means Clustering de tal manera que especificamos el número de cluster de antemano.
En este caso, realizamos una aproximación de bajo rango utilizando una técnica de reducción de la dimensionalidad utilizando una descomposición del valor singular truncado (SVD).
La descomposición del valor singular es una técnica de álgebra lineal que factoriza cualquier matriz M en el producto de 3 matrices separadas: M=U*S*V, donde S es una matriz diagonal de los valores singulares de M.
La SVD truncada reduce la dimensionalidad seleccionando sólo los t valores singulares más grandes, y manteniendo sólo las primeras t columnas de U y V. En este caso, t es un hiperparámetro que podemos seleccionar y ajustar para reflejar el número de temas que queremos encontrar.
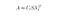
Nota: ¡El SVD truncado hace la reducción de la dimensionalidad y no el SVD!

Con estos vectores de documentos y vectores de términos, ahora podemos aplicar fácilmente medidas como la similitud del coseno para evaluar:
- la similitud de diferentes documentos
- la similitud de diferentes palabras
- la similitud de términos (o «queries») y documentos (lo que resulta útil en la recuperación de información, cuando queremos recuperar los pasajes más relevantes para nuestra consulta de búsqueda).
Observaciones finales
Este algoritmo se utiliza principalmente en varias tareas basadas en la PNL y es la base de métodos más robustos como el LSA probabilístico y el Latent Dirichlet Allocation (LDA).
Kushal Vala, científico de datos junior en Datametica Solutions Pvt Ltd