Disclaimer 1 : Dieser Artikel ist nur eine Einführung in die MFCC-Funktionen und ist für diejenigen gedacht, die ein einfaches und schnelles Verständnis derselben benötigen. Detaillierte Mathematik und Feinheiten werden nicht erörtert.
Da ich selbst nie auf dem Gebiet der Sprachverarbeitung gearbeitet habe, habe ich, als ich das Wort „MFCC“ hörte (das recht häufig von Kollegen verwendet wird), nur unzureichend verstanden, dass es sich dabei um die Bezeichnung für eine bestimmte Art von „Merkmal“ handelt, das aus Audiosignalen extrahiert wird (ähnlich wie Kanten eine Art von Merkmal darstellen, das aus Bildern extrahiert wird).


Es hat mich einiges an Lektüre aus verschiedenen Quellen gekostet, um zu verstehen, was MFCC-Merkmale sind. Also beschloss ich, meinen Mitmenschen in Not zu helfen, indem ich die gesammelten Informationen auf leicht verständliche Weise zusammenstellte.
Beginnen wir damit, die Abkürzung MFCC – Mel Frequency Cepstral Co-efficients – zu erweitern.
Haben Sie das Wort Cepstral schon einmal gehört? Wahrscheinlich nicht. Es ist ein Spektralbegriff mit umgekehrtem Vorzeichen! Aber warum? Für ein sehr grundlegendes Verständnis ist das Cepstrum die Information über die Änderungsrate in den Spektralbändern. Bei der herkömmlichen Analyse von Zeitsignalen zeigt sich jede periodische Komponente (z. B. Echos) als scharfe Spitzen im entsprechenden Frequenzspektrum (d. h. im Fourier-Spektrum). Dieses erhält man durch Anwendung einer Fourier-Transformation auf das Zeitsignal). Dies ist in der folgenden Abbildung zu sehen.

Wenn man den Logarithmus des Betrags dieses Fourier-Spektrums nimmt und dann wiederum das Spektrum dieses Logarithmus durch eine Kosinustransformation (ich weiß, es klingt kompliziert, aber haben Sie bitte Geduld!), so stellt man überall dort eine Spitze fest, wo es ein periodisches Element im ursprünglichen Zeitsignal gibt. Da wir eine Transformation auf das Frequenzspektrum selbst anwenden, liegt das resultierende Spektrum weder im Frequenz- noch im Zeitbereich, weshalb Bogert et al. beschlossen, es als Quefrency Domain zu bezeichnen. Und dieses Spektrum des Logarithmus des Spektrums des Zeitsignals wurde Cepstrum genannt (ta-da!).
Das folgende Bild ist eine Zusammenfassung der oben beschriebenen Schritte.

Cepstrum wurde zuerst eingeführt, um die seismischen Echos zu charakterisieren, die durch Erdbeben entstehen.
Tonhöhe ist eines der Merkmale eines Sprachsignals und wird als Frequenz des Signals gemessen. Die Mel-Skala ist eine Skala, die die wahrgenommene Frequenz eines Tons mit der tatsächlich gemessenen Frequenz in Beziehung setzt. Sie skaliert die Frequenz, um sie besser an das menschliche Gehör anzupassen (Menschen können kleine Veränderungen in der Sprache bei niedrigeren Frequenzen besser wahrnehmen). Diese Skala wurde aus einer Reihe von Experimenten mit menschlichen Probanden abgeleitet. Ich möchte Ihnen intuitiv erklären, was die mel-Skala erfasst.
Der Bereich des menschlichen Gehörs reicht von 20Hz bis 20kHz. Stellen Sie sich eine Melodie bei 300 Hz vor. Das würde etwa so klingen wie der Standardwählton eines Festnetztelefons. Nun stellen Sie sich einen Ton mit 400 Hz vor (ein etwas höherer Wählton). Vergleichen Sie nun den Abstand zwischen diesen beiden, wie auch immer er von Ihrem Gehirn wahrgenommen werden mag. Stellen Sie sich nun ein 900-Hz-Signal (ähnlich einem Mikrofon-Rückkopplungston) und einen 1-kHz-Ton vor. Der wahrgenommene Abstand zwischen diesen beiden Tönen mag größer erscheinen als bei den ersten beiden, obwohl der tatsächliche Unterschied derselbe ist (100 Hz). Die mel-Skala versucht, solche Unterschiede zu erfassen. Eine in Hertz (f) gemessene Frequenz kann mit folgender Formel in die Mel-Skala umgerechnet werden:
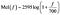
Jeder vom Menschen erzeugte Ton wird durch die Form seines Vokaltrakts (einschließlich Zunge, Zähne usw.) bestimmt. Wenn diese Form korrekt bestimmt werden kann, kann jeder erzeugte Ton genau dargestellt werden. Die Einhüllende des zeitlichen Leistungsspektrums des Sprachsignals ist repräsentativ für den Vokaltrakt, und der MFCC (der nichts anderes ist als die Koeffizienten, aus denen das Mel-Frequenz-Cepstrum besteht) stellt diese Einhüllende genau dar. Das folgende Blockdiagramm fasst schrittweise zusammen, wie wir zu den MFCCs gekommen sind:
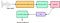
Hier bezieht sich die Filterbank auf die Mel-Filter (die die Mel-Skala abdecken) und die Cepstral-Koeffizienten sind nichts anderes als MFCCs.
TL; DR – MFCC-Merkmale repräsentieren Phoneme (unterschiedliche Einheiten von Klängen), da die Form des Vokaltrakts (der für die Klangerzeugung verantwortlich ist) sich in ihnen manifestiert.
Disclaimer 2 : Alle Bilder sind von Google images.