Locality-sensitive hashing
Ziel: Finden von Dokumenten mit einer Jaccard-Ähnlichkeit von mindestens t
Die allgemeine Idee von LSH ist es, einen Algorithmus zu finden, der bei der Eingabe der Signaturen von zwei Dokumenten angibt, ob diese zwei Dokumente ein Kandidatenpaar bilden oder nicht, d.h. ob ihre Ähnlichkeit größer als ein Schwellenwert t ist. Es sei daran erinnert, dass wir die Ähnlichkeit der Unterschriften als Ersatz für die Jaccard-Ähnlichkeit zwischen den Originaldokumenten betrachten.
Speziell für Min-Hash-Signaturmatrix:
- Hash-Spalten der Signaturmatrix M mit verschiedenen Hash-Funktionen
- Wenn 2 Dokumente in denselben Bucket für mindestens eine der Hash-Funktionen hashen, können wir die 2 Dokumente als Kandidatenpaar betrachten
Nun stellt sich die Frage, wie man verschiedene Hash-Funktionen erstellt. Dazu führen wir eine Bandpartitionierung durch.
Bandpartition

Hier ist der Algorithmus:
- Teilen Sie die Signaturmatrix in b Bänder auf, wobei jedes Band r Zeilen hat
- Für jedes Band, seinen Teil jeder Spalte in eine Hash-Tabelle mit k Buckets
- Kandidaten-Spaltenpaare sind diejenigen, die für mindestens 1 Band in denselben Bucket hashen
- Stimmen Sie b und r so ab, dass die meisten ähnlichen Paare, aber nur wenige nicht ähnliche Paare erfasst werden
Es gibt hier einige Überlegungen. Idealerweise sollte k für jedes Band gleich allen möglichen Kombinationen von Werten sein, die eine Spalte innerhalb eines Bandes annehmen kann. Dies ist gleichbedeutend mit einem Identitätsabgleich. Auf diese Weise wird k jedoch eine riesige Zahl sein, die rechnerisch nicht machbar ist. Beispiel: In einem Band gibt es 5 Zeilen. Wenn nun die Elemente in der Signatur 32-Bit-Ganzzahlen sind, dann ist k in diesem Fall (2³²)⁵ ~ 1,4615016e+48. Sie können sehen, wo das Problem liegt. Normalerweise wird k um 1 Million herum angenommen.
Die Idee ist, dass, wenn 2 Dokumente ähnlich sind, sie als Kandidatenpaar in mindestens einem der Bänder erscheinen werden.
Wahl von b & r
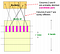
Wenn wir b groß nehmen, d.h. eine größere Anzahl von Hash-Funktionen, dann reduzieren wir r, da b*r eine Konstante ist (Anzahl der Zeilen in der Signaturmatrix). Intuitiv bedeutet dies, dass wir die Wahrscheinlichkeit erhöhen, ein Kandidatenpaar zu finden. Dieser Fall ist gleichbedeutend mit einem kleinen t (Ähnlichkeitsschwelle)
Angenommen, Ihre Signaturmatrix hat 100 Zeilen. Betrachten Sie 2 Fälle:
b1 = 10 → r = 10
b2 = 20 → r = 5
Im 2. Fall ist die Wahrscheinlichkeit höher, dass 2 Dokumente mindestens einmal im selben Bucket auftauchen, da sie mehr Möglichkeiten haben (20 gegenüber 10) und weniger Elemente der Signatur verglichen werden (5 gegenüber 10).
Ein höheres b impliziert einen niedrigeren Ähnlichkeitsschwellenwert (höhere Falsch-Positive) und ein niedrigeres b impliziert einen höheren Ähnlichkeitsschwellenwert (höhere Falsch-Negative)
Lassen Sie uns versuchen, dies anhand eines Beispiels zu verstehen.
Aufbau:
- 100k Dokumente, die als Signatur der Länge 100 gespeichert sind
- Signaturmatrix: 100*100000
- Brute-Force-Vergleich von Signaturen ergibt 100C2 Vergleiche = 5 Milliarden (ziemlich viel!)
- Lassen Sie uns b = 20 → r = 5
Ähnlichkeitsschwelle (t) : 80%
Wir wollen, dass 2 Dokumente (D1 & D2) mit 80% Ähnlichkeit im gleichen Bucket für mindestens eines der 20 Bänder gehasht werden.
P(D1 & D2 identisch in einem bestimmten Band) = (0.8)⁵ = 0.328
P(D1 & D2 sind nicht in allen 20 Bändern ähnlich) = (1-0.328)^20 = 0.00035
Das bedeutet, dass wir in diesem Szenario eine ~.035% Chance auf ein falsches Negativ bei 80% ähnlichen Dokumenten.
Auch wollen wir, dass 2 Dokumente (D3 & D4) mit 30% Ähnlichkeit in keinem der 20 Bänder (Schwellenwert = 80%) im gleichen Bucket gehasht werden.
P(D3 & D4 identisch in einem bestimmten Band) = (0.3)⁵ = 0.00243
P(D3 & D4 sind in mindestens einer der 20 Banden ähnlich) = 1 – (1-0.00243)^20 = 0.0474
Das bedeutet, dass wir in diesem Szenario eine ~4.74%ige Chance auf ein falsches Positiv bei 30% ähnlichen Dokumenten haben.
So können wir sehen, dass wir einige falsch Positive und wenige falsch Negative haben. Dieser Anteil variiert mit der Wahl von b und r.
Was wir hier wollen, ist etwas wie unten. Wenn wir 2 Dokumente haben, deren Ähnlichkeit größer als der Schwellenwert ist, dann sollte die Wahrscheinlichkeit, dass sie in mindestens einem der Bänder denselben Bucket haben, 1 sein, sonst 0.

Im ungünstigsten Fall ist b = Anzahl der Zeilen in der Signaturmatrix wie unten dargestellt.

Der verallgemeinerte Fall für beliebige b und r ist unten dargestellt.

Wählen Sie b und r so, dass Sie die beste S-Kurve erhalten, d.e minimale Falsch-Negativ- und Falsch-Positiv-Rate

LSH-Zusammenfassung
- Stimmen Sie M, b, r, um fast alle Dokumentenpaare mit ähnlichen Signaturen zu erhalten, aber die meisten Paare, die keine ähnlichen Signaturen haben, zu eliminieren
- Überprüfen Sie im Hauptspeicher, dass die Kandidatenpaare wirklich ähnliche Signaturen haben