
Möchte Ihre Organisation Daten aggregieren und analysieren, um Trends zu erkennen, aber auf eine Weise, die die Privatsphäre schützt? Oder verwenden Sie vielleicht bereits differenzierte Datenschutz-Tools, möchten aber Ihr Wissen erweitern (oder weitergeben)? In jedem Fall ist diese Blog-Serie für Sie gedacht.
Warum machen wir diese Serie? Letztes Jahr hat das NIST einen Privacy Engineering Collaboration Space ins Leben gerufen, um Open-Source-Tools, -Lösungen und -Prozesse zu bündeln, die Privacy Engineering und Risikomanagement unterstützen. Als Moderatoren des Collaboration Space haben wir NIST dabei geholfen, unterschiedliche Datenschutz-Tools unter dem Themenbereich De-Identifizierung zu sammeln. Das NIST hat außerdem das Privacy Framework veröffentlicht: A Tool for Improving Privacy through Enterprise Risk Management und eine dazugehörige Roadmap veröffentlicht, die eine Reihe von Herausforderungen für den Datenschutz, einschließlich des Themas De-Identifizierung, erkannt hat. Jetzt möchten wir den Collaboration Space nutzen, um die Lücke in der Roadmap zur De-Identifizierung zu schließen. Unser Ziel ist es, das NIST dabei zu unterstützen, diese Serie in detailliertere Richtlinien zum differenzierten Datenschutz umzuwandeln.
Jeder Beitrag wird mit konzeptionellen Grundlagen und praktischen Anwendungsfällen beginnen, die darauf abzielen, Fachleuten wie Geschäftsprozessverantwortlichen oder Mitarbeitern von Datenschutzprogrammen gerade genug Wissen zu vermitteln, um gefährlich zu sein (nur ein Scherz). Nach den Grundlagen werden wir uns mit den verfügbaren Tools und ihren technischen Ansätzen für Datenschutzingenieure oder IT-Fachleute befassen, die sich für die Details der Implementierung interessieren. Um alle auf den neuesten Stand zu bringen, wird dieser erste Beitrag Hintergrundinformationen zum differenzierten Datenschutz liefern und einige Schlüsselkonzepte beschreiben, die wir im Rest der Serie verwenden werden.
Die Herausforderung
Wie können wir Daten verwenden, um etwas über eine Population zu erfahren, ohne etwas über bestimmte Personen innerhalb der Population zu erfahren? Betrachten wir diese beiden Fragen:
- „Wie viele Menschen leben in Vermont?“
- „Wie viele Menschen mit dem Namen Joe Near leben in Vermont?“
Die erste Frage gibt Aufschluss über eine Eigenschaft der gesamten Bevölkerung, während die zweite Frage Informationen über eine Person liefert. Wir müssen in der Lage sein, etwas über Tendenzen in der Bevölkerung zu erfahren, ohne dass wir etwas Neues über eine bestimmte Person erfahren können. Dies ist das Ziel vieler statistischer Analysen von Daten, wie z. B. der vom U.S. Census Bureau veröffentlichten Statistiken, und des maschinellen Lernens im Allgemeinen. In jedem dieser Bereiche sollen die Modelle Trends in Populationen aufzeigen und nicht Informationen über eine einzelne Person wiedergeben.
Aber wie können wir die erste Frage „Wie viele Menschen leben in Vermont?“ beantworten? – die wir als Abfrage bezeichnen – und gleichzeitig verhindern, dass die zweite Frage beantwortet wird: „Wie viele Personen namens Joe Near leben in Vermont?“ Die am weitesten verbreitete Lösung ist die sogenannte De-Identifizierung (oder Anonymisierung), bei der identifizierende Informationen aus dem Datensatz entfernt werden. (Im Allgemeinen wird davon ausgegangen, dass ein Datensatz Informationen enthält, die von vielen Einzelpersonen gesammelt wurden.) Eine andere Möglichkeit besteht darin, nur aggregierte Abfragen zuzulassen, z. B. einen Durchschnitt über die Daten. Leider wissen wir jetzt, dass keiner der beiden Ansätze wirklich einen starken Schutz der Privatsphäre bietet. De-identifizierte Datensätze sind anfällig für Datenbank-Verknüpfungsangriffe. Die Aggregation schützt die Privatsphäre nur, wenn die zu aggregierenden Gruppen ausreichend groß sind, und selbst dann sind Angriffe auf die Privatsphäre noch möglich.
Differenzielle Privatsphäre
Differenzielle Privatsphäre ist eine mathematische Definition dessen, was es bedeutet, Privatsphäre zu haben. Es handelt sich nicht um einen spezifischen Prozess wie die De-Identifizierung, sondern um eine Eigenschaft, die ein Prozess haben kann. Es ist zum Beispiel möglich zu beweisen, dass ein bestimmter Algorithmus die differentielle Privatsphäre „erfüllt“.
Informell garantiert die differentielle Privatsphäre für jede Person, die Daten zur Analyse beiträgt, Folgendes: Das Ergebnis einer differentiell privaten Analyse wird ungefähr gleich sein, unabhängig davon, ob Sie Ihre Daten beitragen oder nicht. Eine differentiell private Analyse wird oft als Mechanismus bezeichnet, und wir bezeichnen sie als ℳ.
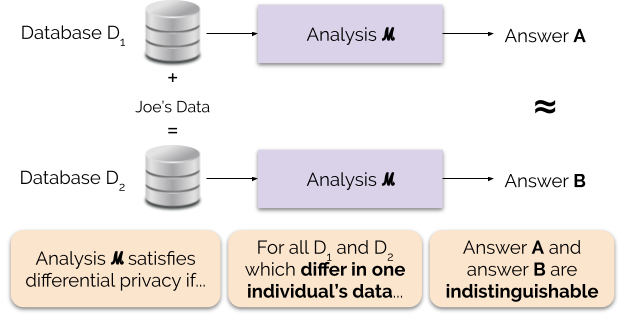
Abbildung 1 veranschaulicht dieses Prinzip. Antwort „A“ wird ohne die Daten von Joe berechnet, während Antwort „B“ mit den Daten von Joe berechnet wird. Die differentielle Geheimhaltung besagt, dass die beiden Antworten ununterscheidbar sein sollten. Das bedeutet, dass derjenige, der die Ausgabe sieht, nicht in der Lage sein wird, festzustellen, ob Joes Daten verwendet wurden oder nicht, oder was Joes Daten enthielten.
Wir kontrollieren die Stärke der Datenschutzgarantie, indem wir den Datenschutzparameter ε einstellen, der auch als Datenschutzverlust oder Datenschutzbudget bezeichnet wird. Je niedriger der Wert des Parameters ε ist, desto ununterscheidbarer sind die Ergebnisse und desto mehr sind die Daten jedes Einzelnen geschützt.
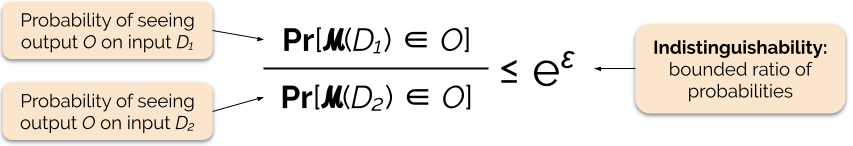
Wir können eine Abfrage oft mit differentieller Privatsphäre beantworten, indem wir der Antwort auf die Abfrage ein zufälliges Rauschen hinzufügen. Die Herausforderung besteht darin, zu bestimmen, wo das Rauschen hinzugefügt werden soll und wie viel. Einer der am häufigsten verwendeten Mechanismen zum Hinzufügen von Rauschen ist der Laplace-Mechanismus.
Bei Abfragen mit höherer Empfindlichkeit muss mehr Rauschen hinzugefügt werden, um eine bestimmte „Epsilon“-Größe der differentiellen Privatsphäre zu erfüllen, und dieses zusätzliche Rauschen kann die Ergebnisse weniger nützlich machen. Wir werden die Empfindlichkeit und diesen Kompromiss zwischen Privatsphäre und Nützlichkeit in zukünftigen Blog-Beiträgen ausführlicher beschreiben.
Vorteile der differentiellen Privatsphäre
Die differentielle Privatsphäre hat mehrere wichtige Vorteile gegenüber früheren Techniken zur Wahrung der Privatsphäre:
- Sie geht davon aus, dass alle Informationen identifizierende Informationen sind, wodurch die schwierige (und manchmal unmögliche) Aufgabe entfällt, alle identifizierenden Elemente der Daten zu berücksichtigen.
- Es ist resistent gegen Angriffe auf die Privatsphäre, die auf Zusatzinformationen beruhen, so dass es die Verknüpfungsangriffe, die bei nicht identifizierten Daten möglich sind, wirksam verhindern kann.
- Es ist kompositionell – wir können den Verlust der Privatsphäre bei der Durchführung von zwei unterschiedlich privaten Analysen mit denselben Daten bestimmen, indem wir einfach die individuellen Verluste der Privatsphäre für die beiden Analysen addieren. Kompositionalität bedeutet, dass wir sinnvolle Garantien für den Schutz der Privatsphäre geben können, selbst wenn wir mehrere Analyseergebnisse aus denselben Daten freigeben. Techniken wie die De-Identifizierung sind nicht kompositionell, und die mehrfache Freigabe dieser Techniken kann zu einem katastrophalen Verlust der Privatsphäre führen.
Diese Vorteile sind die Hauptgründe, warum ein Praktiker den differentiellen Datenschutz einer anderen Datenschutztechnik vorziehen könnte. Ein derzeitiger Nachteil des differentiellen Datenschutzes besteht darin, dass er relativ neu ist und robuste Werkzeuge, Standards und bewährte Verfahren außerhalb der akademischen Forschungsgemeinschaften nicht leicht zugänglich sind. Wir gehen jedoch davon aus, dass diese Einschränkung in naher Zukunft überwunden werden kann, da die Nachfrage nach robusten und benutzerfreundlichen Lösungen für den Datenschutz steigt.
Nächstes Mal
Bleiben Sie dran: Unser nächster Beitrag wird auf diesem Beitrag aufbauen, indem wir die Sicherheitsaspekte beim Einsatz von Systemen für den differenziellen Datenschutz untersuchen, einschließlich des Unterschieds zwischen dem zentralen und dem lokalen Modell des differenziellen Datenschutzes.
Bevor wir gehen – wir möchten, dass diese Serie und die nachfolgenden NIST-Leitlinien dazu beitragen, den differenziellen Datenschutz leichter zugänglich zu machen. You can help. Egal, ob Sie Fragen zu diesen Beiträgen haben oder Ihr Wissen weitergeben können, wir hoffen, dass Sie sich mit uns austauschen, damit wir diese Disziplin gemeinsam voranbringen können.
Garfinkel, Simson, John M. Abowd, und Christian Martindale. „Understanding database reconstruction attacks on public data“. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. „When the signal is in the noise: exploiting diffix’s sticky noise.“ 28th USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, and Kobbi Nissim. „Revealing information while preserving privacy.“ Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. „Einfache demografische Daten identifizieren Menschen oft eindeutig“. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. „Calibrating noise to sensitivity in private data analysis.“ Theory of cryptography conference. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan. „Differentieller Datenschutz: A primer for a non-technical audience“. Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, and Aaron Roth. „The algorithmic foundations of differential privacy“. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.