Hej, folkens! I denne artikel vil jeg beskrive en algoritme, der anvendes i Natural Language Processing: Latent Semantic Analysis ( LSA ).
De vigtigste anvendelser af denne førnævnte metode er vidtfavnende inden for lingvistik: Denne metode er meget omfattende i sprogvidenskab: Sammenligning af dokumenter i lavdimensionelle rum (Document Similarity), Finde tilbagevendende emner på tværs af dokumenter (Topic Modeling), Finde relationer mellem termer (Text Synoymity).

Indledning
Den latente semantiske analysemodel er en teori om, hvordan betydnings
repræsentationer kan læres ved at møde store sprogprøver uden eksplicitte anvisninger om, hvordan det er struktureret.
Problemet ved hånden er ikke overvåget, dvs. vi har ikke faste etiketter eller kategorier tildelt korpusset.
For at udtrække og forstå mønstre fra dokumenterne følger LSA i sagens natur visse antagelser:
1) Betydningen af sætninger eller dokumenter er en sum af betydningen af alle de ord, der forekommer i dem. Samlet set er betydningen af et bestemt ord et gennemsnit på tværs af alle de dokumenter, det forekommer i.
2) LSA antager, at de semantiske associationer mellem ord ikke er til stede eksplicit, men kun latent i det store sprogprøve.
Matematisk perspektiv
Latent Semantic Analysis (LSA) omfatter visse matematiske operationer for at få indsigt i et dokument. Denne algoritme danner grundlaget for Topic Modeling. Den centrale idé er at tage en matrix af det, vi har – dokumenter og termer – og dekomponere den til en separat dokument-tema-matrix og en emne-term-matrix.
Det første skridt er at generere vores dokument-term-matrix ved hjælp af Tf-IDF Vectorizer. Den kan også konstrueres ved hjælp af en Bag-of-Words-model, men resultaterne er sparsomme og giver ikke nogen betydning for sagen.
Givet m dokumenter og n-ord i vores ordforråd kan vi konstruere en
m × n-matrix A, hvor hver række repræsenterer et dokument, og hver kolonne repræsenterer et ord.
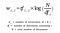
Intuitivt har et udtryk en stor vægt, når det forekommer hyppigt i hele dokumentet, men sjældent i hele korpusset.
Vi danner en dokument-term-matrix, A, ved hjælp af denne transformationsmetode (tf-IDF) for at vektorisere vores korpus. ( På en måde, som vores videre model kan behandle eller evaluere, da vi endnu ikke arbejder med strings!)
Men der er en subtil ulempe, vi kan ikke udlede noget ved at observere A, da det er en støjende og sparsom matrix. ( Nogle gange for stor til selv at beregne for yderligere processer).
Da Topic Modeling i sagens natur er en uovervåget algoritme, er vi nødt til at specificere de latente emner på forhånd. Det er analogt til K-Means Clustering, således at vi specificerer antallet af klynger på forhånd.
I dette tilfælde udfører vi en Low-Rank Approximation ved hjælp af en dimensionalitetsreduktionsteknik ved hjælp af en Truncated Singular Value Decomposition (SVD).
Singular value decomposition er en teknik i lineær algebra, der faktoriserer enhver matrix M til produktet af 3 separate matricer: M=U*S*V, hvor S er en diagonalmatrix af M’s singulære værdier.
Truncated SVD reducerer dimensionaliteten ved kun at udvælge de t største singulære værdier og kun beholde de første t kolonner i U og V. I dette tilfælde er t en hyperparameter, som vi kan vælge og justere for at afspejle det antal emner, vi ønsker at finde.
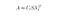
Bemærkning: Truncated SVD foretager dimensionalitetsreduktion og ikke SVD!

Med disse dokumentvektorer og termvektorer kan vi nu nemt anvende mål som cosinuslighed til at evaluere:
- ligheden mellem forskellige dokumenter
- ligheden mellem forskellige ord
- ligheden mellem termer (eller “forespørgsler”) og dokumenter (hvilket bliver nyttigt i informationssøgning, når vi ønsker at hente de passager, der er mest relevante for vores søgeforespørgsel).
Sluttende bemærkninger
Denne algoritme anvendes i høj grad i forskellige NLP-baserede opgaver og danner grundlag for mere robuste metoder som Probabilistisk LSA og Latent Dirichlet Allocation (LDA).
Kushal Vala, Junior Data Scientist at Datametica Solutions Pvt Ltd