Myanmar er i øjeblikket det eneste land i verden med en betydelig online tilstedeværelse, som ikke har standardiseret Unicode, den internationale tekstkodningsstandard. I stedet er Zawgyi den dominerende skrifttype, der bruges til at kode burmesiske sprogtegn. Denne mangel på en fælles standard har resulteret i tekniske udfordringer for mange virksomheder, der leverer mobile apps og tjenester i Myanmar. Det gør det vanskeligt at kommunikere på digitale platforme, da indhold skrevet i Unicode forekommer forvrænget for Zawgyi-brugere og omvendt. Det er et problem for apps som Facebook og Messenger, fordi indlæg, beskeder og kommentarer, der er skrevet i én kodning, ikke kan læses i en anden. Den manglende standardisering omkring Unicode gør det sværere at automatisere og proaktivt opdage krænkende indhold, det kan svække kontosikkerheden, det gør det mindre effektivt at rapportere potentielt skadeligt indhold på Facebook, og det betyder mindre understøttelse af sprog i Myanmar ud over burmesisk.
For at støtte Myanmars overgang til Unicode fjernede vi sidste år zawgyi som en grænsefladesprogmulighed for nye Facebook-brugere. Dernæst arbejdede vi på at sikre, at vores klassifikatorer for hadefuld tale og andet indhold, der overtræder politikken, ikke ville snuble over Zawgyi-indhold, og vi begyndte at arbejde på at integrere skrifttypekonvertere for at forbedre indholdsoplevelsen på Unicode-enheder. For at hjælpe landet med at fortsætte overgangen til Unicode annoncerer vi i dag, at vi har implementeret skriftkonverteringer i Facebook og Messenger. Da vi ved, at denne overgang vil tage tid, vil vores Zawgyi-til-Unicode-konverter fortsat give folk, der er ved at gå over til Unicode, mulighed for at læse indlæg, beskeder og kommentarer, selv om deres venner og familie de endnu ikke har overgået til Unicode på deres enheder. Dette indlæg vil beskrive de tekniske udfordringer, der er forbundet med at integrere disse konvertere, herunder hvordan vi skelner mellem Zawgyi-tekst og Unicode, hvordan vi kan se, om en enhed bruger Zawgyi eller Unicode, og hvordan man konverterer mellem de to, samt nogle af de erfaringer, vi har gjort undervejs.
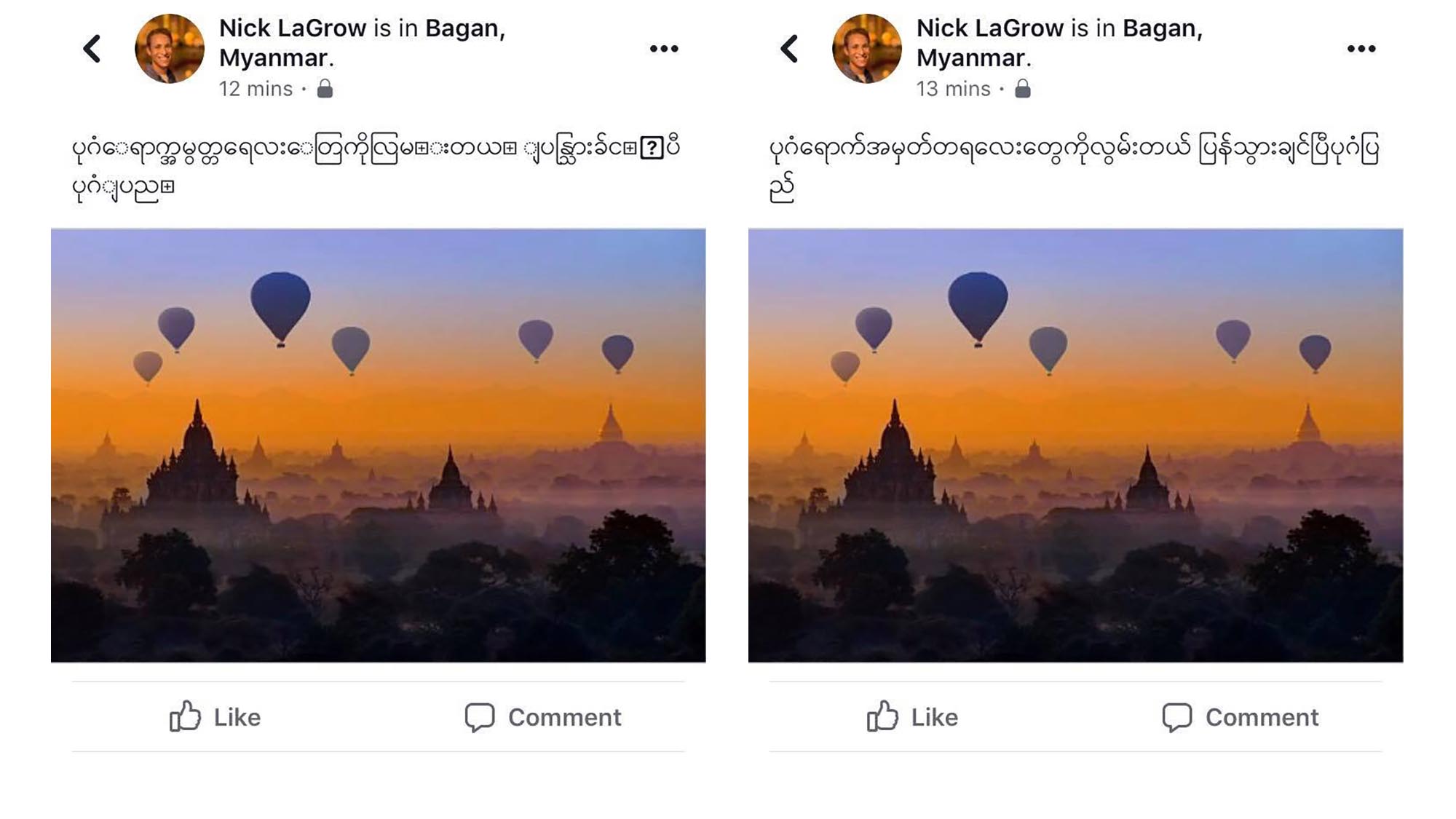
Hvorfor Unicode?
Unicode blev designet som et globalt system, så alle i verden kan bruge deres eget sprog på deres enheder. Men de fleste enheder i Myanmar bruger stadig zawgyi, som er inkompatibelt med Unicode. Hvilket betyder, at de mennesker, der bruger disse enheder, nu står over for kompatibilitetsproblemer på tværs af platforme, operativsystemer og programmeringssprog. For bedre at nå ud til deres publikum skriver indholdsproducenter i Myanmar ofte på både zawgyi og Unicode i et enkelt indlæg, for ikke at tale om engelsk eller andre sprog. Zawgyi-kodning anvender flere kodepunkter for tegn og kombinerede gengivelser; det kræver dobbelt så mange kodepunkter for kun at repræsentere en delmængde af skriften; og vokalkodepunkter kan forekomme før eller efter en konsonant (så CAT eller CTA læses ens), hvilket fører til søge- og sammenligningsproblemer, selv inden for et enkelt dokument. Dette gør enhver form for kommunikation mellem systemer til en stor udfordring.
Facebook støtter Unicode, fordi det giver støtte og en ensartet standard for alle sprog. Især i Myanmar støtter vi overgangen til Unicode, fordi:
- Det gør det muligt for folk i Myanmar at bruge vores apps og tjenester på andre sprog end burmesisk. Zawgyi understøtter kun indtastning af burmesisk tekst, mens Unicode gør det muligt at indtaste minoritetssprog, der tales i Myanmar, f.eks. shan og mon.
- Det giver en normaliseret form for sprog i Myanmar, hvilket hjælper os med at beskytte de mennesker, der bruger vores apps, ved at opdage indhold, der overtræder vores politik, og forbedrer søgeværktøjernes ydeevne betydeligt.
- Det gør det mere effektivt for os at gennemgå rapporter om potentielt skadeligt indhold på Facebook, og indholdsrevisorer vil kunne gennemgå problemer uden at skulle vide, hvordan indholdet er kodet.
En trestrenget tilgang
Da vi først begyndte at se på kodning af Myanmar, var vores højeste prioritet at sikre, at vores systemer, der registrerer skadeligt indhold, f.eks. hadefuld tale, ikke snublede over Zawgyi. Vi forklarede vores mål for dette i dette blogindlæg. De samme udfordringer (såsom flere kodepunkter og kombinerede gengivelser), der gør det svært for systemer at kommunikere ved hjælp af Zawgyi, gør det også svært at træne vores klassifikatorer og AI-systemer til effektivt at opdage politikovertrædende indhold.
Glukkeligvis er vi ikke den eneste virksomhed, der arbejder med dette problem, og vi var i stand til at bruge Googles open source-bibliotek myanmar-tools til at implementere vores løsning. Myanmar-tools-biblioteket var en stor opgradering, hvad angår nøjagtighed af detektion og konvertering, i forhold til det regex-baserede bibliotek, som vi havde brugt. For ca. et år siden integrerede vi skrifttypedetektering og -konvertering for at konvertere alt indhold til Unicode, inden det gik gennem vores klassifikatorer. Det var ikke nogen enkel opgave at implementere autokonvertering i alle vores produkter. Hvert af kravene til autokonvertering – detektion af indholdskodning, detektion af enhedskodning og konvertering – havde sine egne udfordringer.
Detektion af indholdskodning
For at udføre autokonvertering skal vi først kende indholdskodningen, dvs. den kodning, der blev anvendt, da teksten blev indtastet første gang. Desværre bruger Zawgyi og Unicode den samme række af kodepunkter til at repræsentere tegn på burmesisk og andre sprog. På grund af dette kan vi ikke se, om en liste af kodepunkter, der repræsenterer en streng, skal gengives med Zawgyi eller Unicode. Det er heller ikke alle strenge af kodepunkter, der giver mening i begge kodninger. Med en model, der er trænet på tekst oprettet i Zawgyi og Unicode, kan vi vurdere sandsynligheden for, at en given streng er oprettet med et Zawgyi- eller et Unicode-tastatur.

Vores detektion er baseret på myanmar-tools-bibliotekets fremgangsmåde. Vi træner en maskinlæringsmodel (ML) på offentlige Facebook-indholdsprøver, som vi allerede kender indholdskodningen for. Denne model holder styr på, hvor sandsynligt det er, at en række kodepunkter forekommer i Unicode versus i Zawgyi for hver prøve. Når vi senere skal bestemme indholdskodningen af en persons indhold, ser vi på modellens forudsigelse af, om det var mere sandsynligt, at den pågældende sekvens af kodepunkter var blevet indtastet i Unicode eller i Zawgyi – og vi bruger det resultat som indholdskodning.
Detektion af enhedskodning
Næst skal vi vide, hvilken kodning der blev brugt af en persons telefon (dvs. enhedskodningen) for at forstå, om vi skal foretage en konvertering af skrifttypekodningen. For at gøre dette kan vi drage fordel af det faktum, at i den ene kodning vil kombinationen af flere kodepunkter kombinere tekstfragmenter til et enkelt tegn, mens disse to kodepunkter i den anden kodning kan repræsentere separate tegn. Hvis vi opretter en streng på enheden og kontrollerer bredden af denne streng, kan vi se, hvilken skrifttypekodning enheden bruger til at gengive strengen. Når vi har disse oplysninger, kan vi i fremtidige webanmodninger fortælle serveren, at enheden bruger Zawgyi eller Unicode, og sikre os, at det indhold, der hentes, stemmer overens. I Myanmar bestemmer vores logik på klientsiden, om den pågældende enhed anvender Zawgyi eller Unicode, og sender den pågældende kodning som en del af feltet locale i webanmodningen (f.eks. my_Qaag_MM).
Konvertering
Dernæst kontrollerer serveren, om den indlæser burmesisk indhold. Hvis indholdskodningen og enhedskodningen ikke stemmer overens, skal vi konvertere indholdet til et format, som læserens enhed vil gengive korrekt. Hvis et indlæg f.eks. blev indtastet med en Unicode-indholdskodning, men det læses på en Zawgyi-kodet enhed, konverterer vi teksten i indlægget til Zawgyi, før vi gengiver den på Zawgyi-enheden.
Det er vigtigt at træne denne model på Facebook-indhold i stedet for på andet offentligt tilgængeligt indhold på nettet. Folk skriver anderledes på Facebook, end de ville gøre på en webside eller i en videnskabelig artikel: Facebook-opslag og -beskeder er generelt kortere og mindre formelle, og de indeholder forkortelser, slang og stavefejl. Vi ønsker, at vores forudsigelser skal være så præcise som muligt for det indhold, som folk deler og læser i vores apps.
Integration af autokonvertering på Facebook-skala
Den næste udfordring var at integrere denne konvertering på tværs af de forskellige typer indhold, som folk kan oprette i vores apps. Zawgyi-tekst er blevet indtastet til statusopdateringer såvel som til brugernavne, kommentarer, video-undertekster, private beskeder og meget mere. At køre vores detektion og konvertering hver gang nogen henter en hvilken som helst type indhold ville være uoverkommeligt med hensyn til den tid og de ressourcer, der kræves. Der er ingen enkelt pipeline, som alt muligt Facebook-indhold passerer igennem, hvilket gør det vanskeligt at opfange Zawgyi-indhold overalt, hvor nogen måtte indtaste det. Desuden er det ikke alle webforespørgsler, der foretages fra en persons enhed. Når meddelelser og beskeder f.eks. skubbes til enheder, kan vi ikke køre enhedskodningslogikken. Desuden er meddelelser og kommentarer ofte meget korte, hvilket sænker detektionsnøjagtigheden.
Fontkonverteren er nu fuldt implementeret på Facebook og Messenger. Disse værktøjer vil gøre en stor forskel for de millioner af mennesker i Myanmar, der bruger vores apps til at kommunikere med venner og familie. For fortsat at støtte befolkningen i Myanmar gennem denne overgang til Unicode undersøger vi muligheden for at udvide vores autokonverteringsværktøjer til flere af Facebook-familiens produkter samt forbedre kvaliteten af vores automatiske detektion og konvertering. Vi har også til hensigt at fortsætte med at bidrage til open source-biblioteket myanmar-tools for at hjælpe andre med at opbygge værktøjer til at støtte denne overgang.