
Ønsker din organisation at samle og analysere data for at lære trends at kende, men på en måde, der beskytter privatlivets fred? Eller måske bruger du allerede differentierede værktøjer til beskyttelse af privatlivets fred, men ønsker at udvide (eller dele) din viden? I begge tilfælde er denne blogserie for dig.
Hvorfor laver vi denne serie? Sidste år lancerede NIST et Privacy Engineering Collaboration Space for at samle open source-værktøjer, -løsninger og -processer, der understøtter privacy engineering og risikostyring. Som moderatorer for Collaboration Space har vi hjulpet NIST med at samle forskellige værktøjer til beskyttelse af privatlivets fred under emneområdet de-identifikation. NIST har også offentliggjort Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management og en ledsagende køreplan, som anerkendte en række udfordringsområder for privatlivets fred, herunder emnet afidentifikation. Nu vil vi gerne udnytte Collaboration Space til at hjælpe med at lukke køreplanens mangler i forbindelse med afidentificering. Vores slutspil er at støtte NIST i at omdanne denne serie til mere dybdegående retningslinjer om differentieret fortrolighed.
Hvert indlæg vil begynde med konceptuelle grundbegreber og praktiske anvendelsestilfælde, der har til formål at hjælpe fagfolk som f.eks. forretningsprocesejere eller personale i fortrolighedsprogrammer med at lære lige nok til at være farlige (bare for sjov). Efter at have gennemgået det grundlæggende vil vi se på tilgængelige værktøjer og deres tekniske fremgangsmåder for privacy engineers eller it-professionelle, der er interesseret i implementeringsdetaljer. For at få alle i gang, vil dette første indlæg give baggrundsoplysninger om differentieret beskyttelse af personlige oplysninger og beskrive nogle nøglebegreber, som vi vil bruge i resten af serien.
Udfordringen
Hvordan kan vi bruge data til at lære om en population uden at lære om specifikke personer i populationen? Overvej disse to spørgsmål:
- “Hvor mange mennesker bor der i Vermont?”
- “Hvor mange personer ved navn Joe Near bor der i Vermont?”
Det første afslører en egenskab ved hele populationen, mens det andet afslører oplysninger om en enkelt person. Vi skal kunne få kendskab til tendenser i befolkningen, samtidig med at vi skal forhindre muligheden for at lære noget nyt om et bestemt individ. Dette er målet for mange statistiske analyser af data, som f.eks. de statistikker, der offentliggøres af U.S. Census Bureau, og maskinlæring i bredere forstand. I hver af disse indstillinger har modellerne til formål at afsløre tendenser i populationer og ikke at afspejle oplysninger om et enkelt individ.
Men hvordan kan vi besvare det første spørgsmål “Hvor mange mennesker bor der i Vermont?”? – som vi vil kalde en forespørgsel – samtidig med at vi forhindrer, at det andet spørgsmål bliver besvaret: “Hvor mange personer ved navn Joe Near bor i Vermont?” Den mest udbredte løsning kaldes de-identifikation (eller anonymisering), som fjerner identificerende oplysninger fra datasættet. (Vi antager generelt, at et datasæt indeholder oplysninger, der er indsamlet fra mange enkeltpersoner). En anden mulighed er kun at tillade aggregerede forespørgsler, f.eks. et gennemsnit over dataene. Desværre forstår vi nu, at ingen af disse to fremgangsmåder faktisk giver en stærk beskyttelse af privatlivets fred. Afidentificerede datasæt er udsat for database-linkage-angreb. Aggregering beskytter kun privatlivets fred, hvis de grupper, der aggregeres, er tilstrækkeligt store, og selv da er det stadig muligt at angribe privatlivets fred .
Differentielt privatliv
Differentielt privatliv er en matematisk definition af, hvad det vil sige at have privatliv. Det er ikke en specifik proces som f.eks. afidentifikation, men en egenskab, som en proces kan have. Det er f.eks. muligt at bevise, at en bestemt algoritme “opfylder” differentielt privatliv.
Informelt set garanterer differentielt privatliv følgende for hver enkelt person, der bidrager med data til analyse: resultatet af en differentielt privat analyse vil være nogenlunde det samme, uanset om du bidrager med dine data eller ej. En differentielt privat analyse kaldes ofte en mekanisme, og vi betegner den ℳ.
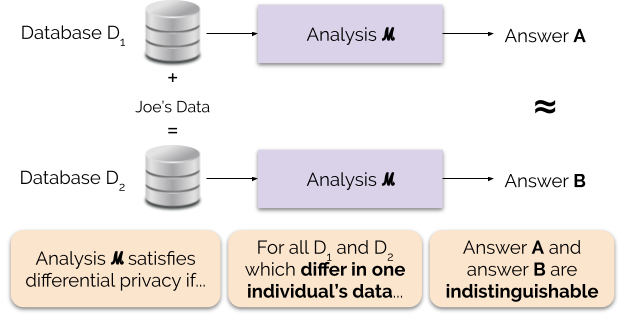
Figur 1 illustrerer dette princip. Svar “A” beregnes uden Joe’s data, mens svar “B” beregnes med Joe’s data. Differentielt privatliv siger, at de to svar skal være umulige at skelne fra hinanden. Det betyder, at den, der ser resultatet, ikke vil kunne se, om Joes data er blevet brugt eller ej, eller hvad Joes data indeholdt.
Vi styrer styrken af privatlivsgarantien ved at indstille privatlivsgarantiparameteren ε, også kaldet et privatlivstab eller privatlivsbudget. Jo lavere værdi af ε-parameteren er, jo mere utydelige er resultaterne, og jo mere er hver enkelt persons data derfor beskyttet.
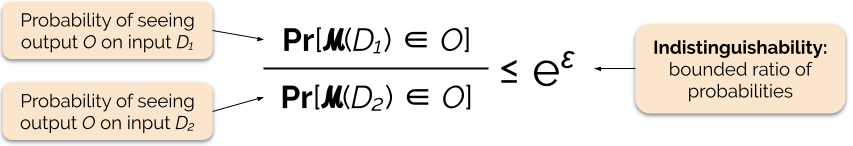
Vi kan ofte besvare en forespørgsel med differentiel fortrolighed ved at tilføje noget tilfældig støj til forespørgselssvaret. Udfordringen ligger i at bestemme, hvor og hvor meget støjen skal tilføjes. En af de mest almindeligt anvendte mekanismer til at tilføje støj er Laplace-mekanismen .
Spørgsmål med højere følsomhed kræver, at der tilføjes mere støj for at opfylde en bestemt `epsilon`-mængde af differentiel fortrolighed, og denne ekstra støj har potentiale til at gøre resultaterne mindre brugbare. Vi vil beskrive følsomhed og denne afvejning mellem privatliv og anvendelighed mere detaljeret i fremtidige blogindlæg.
Fordele ved differentiel fortrolighed
Differentiel fortrolighed har flere vigtige fordele i forhold til tidligere fortrolighedsteknikker:
- Den antager, at alle oplysninger er identificerende oplysninger, hvilket eliminerer den udfordrende (og nogle gange umulige) opgave med at redegøre for alle identificerende elementer i dataene.
- Den er modstandsdygtig over for privatlivsangreb baseret på hjælpeoplysninger, så den kan effektivt forhindre de sammenkædningsangreb, der er mulige på afidentificerede data.
- Den er kompositorisk – vi kan bestemme tabet af privatlivets fred ved at køre to differentielt private analyser på de samme data ved simpelthen at lægge de individuelle tab af privatlivets fred for de to analyser sammen. Kompositionalitet betyder, at vi kan give meningsfulde garantier om privatlivets fred, selv når vi frigiver flere analyseresultater fra de samme data. Teknikker som afidentifikation er ikke kompositionelle, og flere udgivelser under disse teknikker kan resultere i et katastrofalt tab af privatlivets fred.
Disse fordele er de primære grunde til, at en praktiker kan vælge differentiel fortrolighed frem for en anden teknik til beskyttelse af privatlivets fred for data. En nuværende ulempe ved differentieret beskyttelse af personlige oplysninger er, at den er ret ny, og at robuste værktøjer, standarder og bedste praksis ikke er let tilgængelige uden for akademiske forskningsmiljøer. Vi forudser dog, at denne begrænsning kan blive overvundet i den nærmeste fremtid på grund af den stigende efterspørgsel efter robuste og brugervenlige løsninger til databeskyttelse.
Næste afsnit
Stay tuned: vores næste indlæg vil bygge videre på dette indlæg ved at undersøge de sikkerhedsspørgsmål, der er involveret i implementering af systemer til differentiel beskyttelse af personlige oplysninger, herunder forskellen mellem de centrale og lokale modeller for differentiel beskyttelse af personlige oplysninger.
Hvor vi går – vi ønsker, at denne serie og de efterfølgende NIST-retningslinjer skal bidrage til at gøre differentiel beskyttelse af personlige oplysninger mere tilgængelig. Du kan hjælpe os. Uanset om du har spørgsmål til disse indlæg eller kan dele din viden, håber vi, at du vil engagere dig med os, så vi sammen kan fremme denne disciplin.
Garfinkel, Simson, John M. Abowd og Christian Martindale. “Understanding database reconstruction attacks on public data”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “When the signal is in the noise: exploiting diffix’s sticky noise.” 28th USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, og Kobbi Nissim. “Revealing information while preserving privacy.” Proceedings of the twenty-second ACM SIGMOD-SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. “Simple demografiske oplysninger identificerer ofte folk entydigt.” Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis.” Theory of cryptography conference. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, og Salil Vadhan. “Differential privacy”: A primer for a non-technical audience.” Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, og Aaron Roth. “Det algoritmiske grundlag for differentielt privatliv.” Foundations and Trends in Theoretical Computer Science 9, nr. 3-4 (2014): 211-407.