Myanmar är för närvarande det enda land i världen med en betydande närvaro på nätet som inte har standardiserat Unicode, den internationella standarden för textkodning. I stället är Zawgyi det dominerande typsnittet som används för att koda tecken på det burmesiska språket. Denna brist på en enda standard har lett till tekniska utmaningar för många företag som tillhandahåller mobilappar och tjänster i Myanmar. Det försvårar kommunikationen på digitala plattformar, eftersom innehåll som är skrivet i Unicode ser förvrängt ut för Zawgyi-användare och vice versa. Detta är ett problem för appar som Facebook och Messenger eftersom inlägg, meddelanden och kommentarer som skrivits i en kodning inte kan läsas i en annan. Bristen på standardisering kring Unicode gör det svårare att automatisera och proaktivt upptäcka kränkande innehåll, det kan försvaga kontosäkerheten, det gör det mindre effektivt att rapportera potentiellt skadligt innehåll på Facebook och det innebär mindre stöd för språk i Myanmar utöver burmesiska.
Förra året, för att stödja Myanmars övergång till Unicode, tog vi bort zawgyi som gränssnittsspråksalternativ för nya Facebookanvändare. Därefter arbetade vi för att säkerställa att våra klassificerare för hatretorik och annat innehåll som bryter mot policyn inte skulle snubbla över Zawgyi-innehåll, och vi påbörjade arbetet med att integrera teckensnittskonverterare för att förbättra innehållsupplevelsen på Unicode-enheter. För att hjälpa landet att fortsätta sin övergång till Unicode meddelar vi idag att vi har implementerat teckensnittskonverterare i Facebook och Messenger. Eftersom vi vet att övergången kommer att ta tid kommer vår konverterare från Zawgyi till Unicode att fortsätta göra det möjligt för personer som övergår till Unicode att läsa inlägg, meddelanden och kommentarer även om deras vänner och familj de ännu inte har övergått till Unicode på sina enheter. Det här inlägget kommer att redogöra för de tekniska utmaningarna med att integrera dessa konverterare, inklusive hur vi skiljer Zawgyi-text från Unicode, hur vi kan avgöra om en enhet använder Zawgyi eller Unicode och hur man konverterar mellan de två, samt några lärdomar som vi lärt oss på vägen.
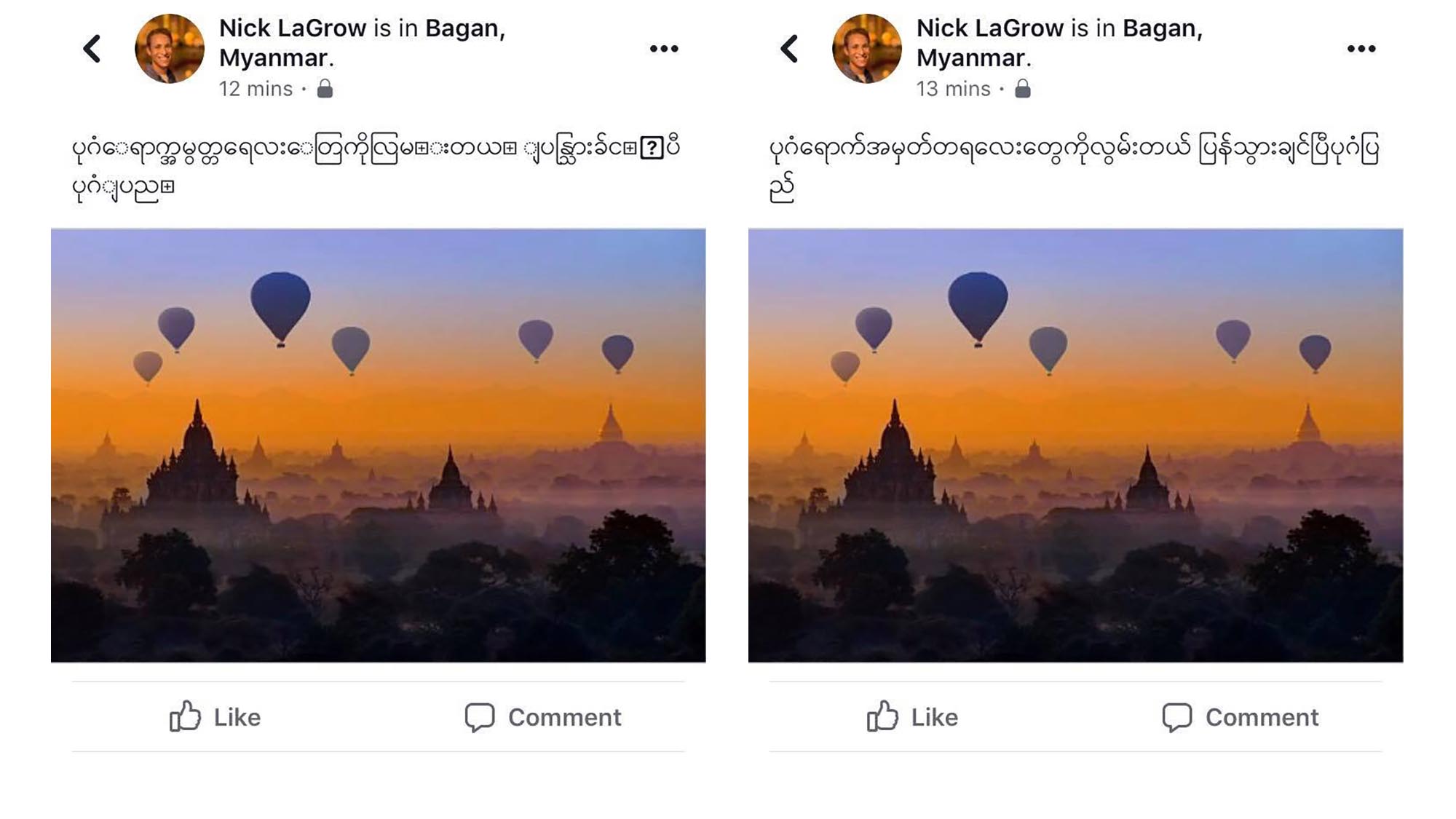
Varför Unicode?
Unicode utformades som ett globalt system som skulle göra det möjligt för alla människor i världen att använda sitt eget språk på sina enheter. Men de flesta enheter i Myanmar använder fortfarande zawgyi, som är inkompatibelt med Unicode. Vilket innebär att de personer som använder dessa enheter nu har problem med kompatibilitetsproblem mellan olika plattformar, operativsystem och programmeringsspråk. För att bättre nå ut till sin publik lägger innehållsproducenter i Myanmar ofta upp inlägg på både zawgyi och Unicode i ett enda inlägg, för att inte tala om engelska eller andra språk. Zawgyi-kodningen använder flera kodpunkter för tecken och kombinerade återgivningar, kräver dubbelt så många kodpunkter för att bara representera en delmängd av skriften, och vokalkodpunkter kan förekomma före eller efter en konsonant (så att CAT eller CTA läses på samma sätt), vilket leder till problem med sökning och jämförelser, även inom ett och samma dokument. Detta gör all slags kommunikation mellan systemen till en stor utmaning.
Facebook stöder Unicode eftersom det erbjuder stöd och en konsekvent standard för alla språk. I Myanmar stöder vi särskilt övergången till Unicode eftersom:
- Det gör det möjligt för människor i Myanmar att använda våra appar och tjänster på andra språk än burmesiska. Zawgyi stöder endast inmatning av burmesisk text, medan Unicode möjliggör inmatning av minoritetsspråk som talas i Myanmar, t.ex. shan och mon.
- Det erbjuder en normaliserad form för språk i Myanmar, vilket hjälper oss att skydda de människor som använder våra appar genom att upptäcka innehåll som strider mot policyn och förbättrar sökverktygens prestanda avsevärt.
- Det gör det effektivare för oss att granska rapporter om potentiellt skadligt innehåll på Facebook, och innehållsgranskare kommer att kunna granska problem utan att behöva veta hur innehållet kodades.
En tredelad strategi
När vi först började titta på kodning av Myanmar var vår högsta prioritet att se till att våra system som upptäcker skadligt innehåll, som till exempel hatretorik, inte snubblade över Zawgyi. Vi förklarade våra mål för detta i det här blogginlägget. Samma utmaningar (t.ex. flera kodpunkter och kombinerade renderingar) som gör det svårt för system att kommunicera med Zawgyi gör det också svårt att träna våra klassificerare och AI-system för att effektivt upptäcka policyvidrigt innehåll.
Turligtvis är vi inte det enda företaget som arbetar med den här frågan, och vi kunde använda Googles open source-bibliotek myanmar-tools för att implementera vår lösning. Biblioteket myanmar-tools var en stor uppgradering, när det gäller noggrannhet vid upptäckt och konvertering, jämfört med det regex-baserade bibliotek vi hade använt. För ungefär ett år sedan integrerade vi upptäckt och konvertering av teckensnitt för att konvertera allt innehåll till Unicode innan det gick igenom våra klassificerare. Att införa automatisk konvertering i alla våra produkter var inte en enkel uppgift. Varje krav för autokonvertering – detektering av innehållskodning, detektering av enhetskodning och konvertering – hade sina egna utmaningar.
Detektering av innehållskodning
För att utföra autokonvertering måste vi först känna till innehållskodningen, det vill säga den kodning som användes när texten först matades in. Tyvärr använder Zawgyi och Unicode samma antal kodpunkter för att representera tecken på burmesiska och andra språk. På grund av detta kan vi inte avgöra om en lista med kodpunkter som representerar en sträng ska återges med Zawgyi eller Unicode. Det är inte heller alla strängar av kodpunkter som är meningsfulla i båda kodningarna. Med en modell som tränats på text som skapats i Zawgyi och Unicode kan vi bedöma sannolikheten för att en viss sträng skapats med ett Zawgyi- eller ett Unicode-tangentbord.

Vår upptäckt bygger på myanmar-tools-bibliotekets tillvägagångssätt. Vi tränar en modell för maskininlärning (ML) på offentliga innehållsprover från Facebook för vilka vi redan känner till innehållskodningen. Modellen håller reda på hur sannolikt det är att en serie kodpunkter förekommer i Unicode respektive Zawgyi för varje prov. När vi senare fastställer innehållskodningen för någons innehåll tittar vi på modellens förutsägelse om huruvida det var mer sannolikt att sekvensen av kodpunkter hade angetts i Unicode eller Zawgyi – och vi använder det resultatet som innehållskodning.
Detektering av enhetskodning
Nästan måste vi veta vilken kodning som användes av en persons telefon (dvs. enhetskodningen) för att förstå om vi behöver utföra en konvertering av teckensnittskodningen. För att göra detta kan vi dra nytta av det faktum att i en kodning kommer kombinationen av flera kodpunkter att kombinera textfragment till ett enda tecken, medan dessa två kodpunkter i den andra kodningen kan representera separata tecken. Om vi skapar en sträng på enheten och kontrollerar strängens bredd kan vi avgöra vilken teckensnittskodning enheten använder för att återge strängen. När vi har denna information kan vi i framtida webbförfrågningar tala om för servern att enheten använder Zawgyi eller Unicode och se till att allt innehåll som hämtas stämmer överens. I Myanmar fastställer vår logik på klientsidan om enheten i fråga använder Zawgyi eller Unicode och skickar den kodningen som en del av fältet locale i webbförfrågan (t.ex. my_Qaag_MM).
Konvertering
Nästan kontrollerar servern om den laddar in burmesiskt innehåll. Om innehållets kodning och enhetens kodning inte stämmer överens måste vi konvertera innehållet till ett format som läsarens enhet kan återge korrekt. Om ett inlägg till exempel matades in med en Unicode-innehållskodning, men det läses på en Zawgyi-kodad enhet, konverterar vi texten i inlägget till Zawgyi innan vi render den på Zawgyi-enheten.
Det är viktigt att träna den här modellen på Facebook-innehåll i stället för på annat offentligt tillgängligt innehåll på webben. Människor skriver annorlunda på Facebook än de skulle göra på en webbsida eller i en vetenskaplig artikel: Inlägg och meddelanden på Facebook är i allmänhet kortare och mindre formella, och de innehåller förkortningar, slang och stavfel. Vi vill att våra förutsägelser ska vara så exakta som möjligt för det innehåll som människor delar och läser i våra appar.
Integrera autokonvertering i Facebooks skala
Nästa utmaning var att integrera den här konverteringen i de olika typer av innehåll som människor kan skapa i våra appar. Zawgyi-text har lagts in för statusuppdateringar samt för användarnamn, kommentarer, videoundertexter, privata meddelanden med mera. Att köra vår detektering och konvertering varje gång någon hämtar någon typ av innehåll skulle vara oöverkomligt när det gäller den tid och de resurser som krävs. Det finns ingen enda pipeline genom vilken allt möjligt Facebook-innehåll passerar, vilket gör det svårt att fånga Zawgyi-innehållet överallt där någon kan komma att skriva in det. Dessutom görs inte alla webbförfrågningar från en persons enhet. När till exempel notiser och meddelanden skjuts till enheter kan vi inte köra logiken för enhetskodning. Dessutom är meddelanden och kommentarer ofta mycket korta, vilket sänker upptäcktsnoggrannheten.
Typsnittskonverteraren är nu helt implementerad på Facebook och Messenger. Dessa verktyg kommer att göra stor skillnad för de miljontals människor i Myanmar som använder våra appar för att kommunicera med vänner och familj. För att fortsätta stödja folket i Myanmar genom denna övergång till Unicode undersöker vi om vi kan utöka våra verktyg för autokonvertering till fler av Facebooks produktfamilj, samt förbättra kvaliteten på vår automatiska detektering och konvertering. Vi har också för avsikt att fortsätta att bidra till open source-biblioteket myanmar-tools för att hjälpa andra att bygga verktyg för att stödja denna övergång.