
Vill din organisation sammanställa och analysera data för att ta reda på trender, men på ett sätt som skyddar integriteten? Eller kanske använder ni redan differentierade integritetsverktyg, men vill utöka (eller dela) era kunskaper? I båda fallen är den här bloggserien för dig.
Varför gör vi den här serien? Förra året lanserade NIST ett samarbetsområde för integritetsutveckling för att samla verktyg, lösningar och processer med öppen källkod som stöder integritetsutveckling och riskhantering. Som moderatorer för Collaboration Space har vi hjälpt NIST att samla olika integritetsverktyg under ämnesområdet avidentifiering. NIST har också publicerat Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management (ett verktyg för att förbättra integriteten genom riskhantering för företag) och en tillhörande färdplan där ett antal utmaningsområden för integritetsskydd, inklusive ämnet avidentifiering, erkänns. Nu vill vi utnyttja samarbetsutrymmet för att hjälpa till att fylla färdplanens luckor när det gäller avidentifiering. Vårt slutmål är att stödja NIST när det gäller att omvandla den här serien till mer djupgående riktlinjer om differentiell integritet.
Varje inlägg kommer att börja med konceptuella grunder och praktiska användningsfall, som syftar till att hjälpa yrkesverksamma, t.ex. ägare av affärsprocesser eller personal inom sekretessprogrammen, att lära sig tillräckligt mycket för att det ska bli farligt (jag skojade bara). Efter att ha behandlat grunderna kommer vi att titta på tillgängliga verktyg och deras tekniska tillvägagångssätt för integritetsingenjörer eller IT-personal som är intresserade av detaljer om genomförandet. För att få alla att komma igång kommer det här första inlägget att ge en bakgrund till differentiell integritet och beskriva några nyckelbegrepp som vi kommer att använda i resten av serien.
Utmaningen
Hur kan vi använda data för att lära oss mer om en population, utan att lära oss mer om specifika individer inom populationen? Tänk på dessa två frågor:
- ”Hur många människor bor i Vermont?”
- ”Hur många personer som heter Joe Near bor i Vermont?”
Den första avslöjar en egenskap hos hela populationen, medan den andra avslöjar information om en person. Vi måste kunna lära oss om tendenser i populationen samtidigt som vi förhindrar möjligheten att lära oss något nytt om en viss individ. Detta är målet för många statistiska analyser av data, t.ex. den statistik som publiceras av U.S. Census Bureau, och maskininlärning i vidare bemärkelse. I alla dessa sammanhang är modellerna avsedda att avslöja trender i populationer, inte att återspegla information om en enskild individ.
Men hur kan vi besvara den första frågan ”Hur många människor bor i Vermont?”? – som vi kommer att kalla en fråga – samtidigt som vi förhindrar att den andra frågan besvaras ”Hur många personer som heter Joe Near bor i Vermont?”. Den mest använda lösningen kallas avidentifiering (eller anonymisering), vilket innebär att identifierande information avlägsnas från datasetet. (Vi utgår i allmänhet från att en datamängd innehåller information som samlats in från många individer). Ett annat alternativ är att endast tillåta aggregerade frågor, t.ex. ett genomsnitt av uppgifterna. Tyvärr förstår vi nu att inget av dessa tillvägagångssätt faktiskt ger ett starkt integritetsskydd. Avidentifierade datamängder är utsatta för databaskopplingsattacker. Aggregering skyddar endast integriteten om de grupper som aggregeras är tillräckligt stora, och även då är integritetsattacker fortfarande möjliga .
Differentiell integritet
Differentiell integritet är en matematisk definition av vad det innebär att ha integritet. Det är inte en specifik process som avidentifiering, utan en egenskap som en process kan ha. Det är till exempel möjligt att bevisa att en specifik algoritm ”uppfyller” differentiell integritet.
Informellt sett garanterar differentiell integritet följande för varje individ som bidrar med data för analys: resultatet av en differentiellt privat analys kommer att vara ungefär detsamma, oavsett om du bidrar med dina data eller inte. En differentiellt privat analys kallas ofta för en mekanism, och vi betecknar den ℳ.
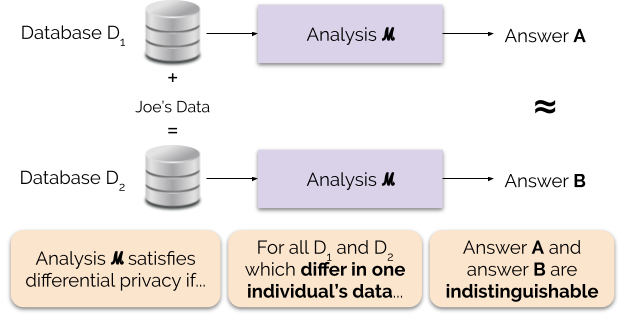
Figur 1 illustrerar denna princip. Svar ”A” beräknas utan Joes uppgifter, medan svar ”B” beräknas med Joes uppgifter. Differentiell sekretess innebär att de två svaren inte ska kunna särskiljas. Detta innebär att den som ser resultatet inte kommer att kunna avgöra om Joes uppgifter användes eller inte, eller vad Joes uppgifter innehöll.
Vi kontrollerar integritetsgarantins styrka genom att ställa in integritetsparametern ε, även kallad integritetsförlust eller integritetsbudget. Ju lägre värde på parametern ε, desto mer omöjliga att särskilja resultaten och desto mer skyddas därför varje individs uppgifter.
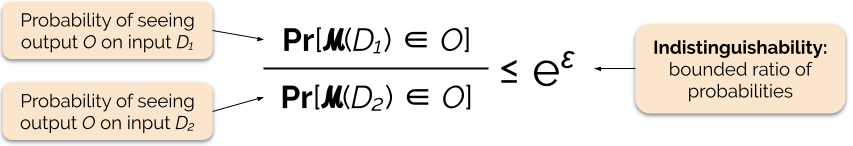
Vi kan ofta besvara en fråga med differentiell sekretess genom att lägga till lite slumpmässigt brus i svaret på frågan. Utmaningen ligger i att bestämma var bruset ska läggas till och hur mycket det ska läggas till. En av de vanligaste mekanismerna för att lägga till brus är Laplace-mekanismen .
Frågor med högre känslighet kräver att mer brus läggs till för att uppfylla en viss `epsilon`-mängd av differentiell sekretess, och detta extra brus har potential att göra resultaten mindre användbara. Vi kommer att beskriva känslighet och denna avvägning mellan integritet och användbarhet mer i detalj i framtida blogginlägg.
Fördelar med differentiell integritet
Differentiell integritet har flera viktiga fördelar jämfört med tidigare integritetstekniker:
- Den utgår från att all information är identifierande information, vilket eliminerar den utmanande (och ibland omöjliga) uppgiften att redovisa alla identifierande element i data.
- Den är motståndskraftig mot integritetsangrepp baserade på tilläggsinformation, så den kan effektivt förhindra de länkningsangrepp som är möjliga på avidentifierade uppgifter.
- Den är kompositionell – vi kan bestämma integritetsförlusten av att köra två differentiellt privata analyser på samma uppgifter genom att helt enkelt addera de individuella integritetsförlusterna för de två analyserna. Kompositionalitet innebär att vi kan ge meningsfulla garantier om integritet även när vi släpper flera analysresultat från samma data. Tekniker som avidentifiering är inte kompositionella, och flera offentliggöranden enligt dessa tekniker kan resultera i en katastrofal förlust av integritet.
Dessa fördelar är de främsta skälen till varför en yrkesutövare kan välja differentiell sekretess framför någon annan teknik för dataskydd. En nuvarande nackdel med differentiell sekretess är att den är ganska ny och att robusta verktyg, standarder och bästa praxis inte är lättillgängliga utanför den akademiska forskarvärlden. Vi förutspår dock att denna begränsning kan övervinnas inom en snar framtid på grund av den ökande efterfrågan på robusta och lättanvända lösningar för dataintegritet.
Nästa inlägg
Stay tuned: vårt nästa inlägg kommer att bygga vidare på det här genom att utforska de säkerhetsfrågor som är involverade i att använda system för differentiell sekretess, inklusive skillnaden mellan de centrala och lokala modellerna för differentiell sekretess.
Förresten vill vi att den här serien och efterföljande NIST-riktlinjer ska bidra till att göra differentiell sekretess mer tillgänglig. Du kan hjälpa till. Oavsett om du har frågor om dessa inlägg eller kan dela med dig av dina kunskaper hoppas vi att du vill engagera dig med oss så att vi kan utveckla denna disciplin tillsammans.
Garfinkel, Simson, John M. Abowd och Christian Martindale. ”Förståelse av databaserekonstruktionsattacker på offentliga data”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. ”When the signal is in the noise: exploiting diffix’s sticky noise”. 28th USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit och Kobbi Nissim. ”Att avslöja information med bibehållen integritet”. Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. ”Enkla demografiska uppgifter identifierar ofta människor på ett unikt sätt”. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. ”Calibrating noise to sensitivity in private data analysis”. Theory of cryptography conference. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke och Salil Vadhan. ”Differential privacy”: A primer for a non-technical audience”. Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia och Aaron Roth. ”The algorithmic foundations of differential privacy”. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.