Myanmar este în prezent singura țară din lume cu o prezență online semnificativă care nu s-a standardizat pe Unicode, standardul internațional de codificare a textului. În schimb, Zawgyi este fontul dominant folosit pentru a codifica caracterele limbii birmane. Această lipsă a unui standard unic a dus la provocări tehnice pentru multe companii care furnizează aplicații și servicii mobile în Myanmar. Aceasta îngreunează comunicarea pe platformele digitale, deoarece conținutul scris în Unicode apare distorsionat pentru utilizatorii de Zawgyi și viceversa. Aceasta este o problemă pentru aplicații precum Facebook și Messenger, deoarece postările, mesajele și comentariile scrise într-o codificare nu sunt lizibile în alta. Lipsa de standardizare în jurul Unicode îngreunează automatizarea și detectarea proactivă a conținutului care încalcă legea, poate slăbi securitatea contului, face ca raportarea conținutului potențial dăunător pe Facebook să fie mai puțin eficientă și înseamnă mai puțin suport pentru limbile din Myanmar în afară de birmaneză.
Anul trecut, pentru a sprijini tranziția Myanmarului la Unicode, am eliminat Zawgyi ca opțiune de limbă de interfață pentru noii utilizatori Facebook. Apoi, am lucrat pentru a ne asigura că clasificatorii noștri pentru discursul instigator la ură și alte conținuturi care încalcă politicile nu se vor împiedica de conținutul Zawgyi și am început să lucrăm la integrarea convertoarelor de fonturi pentru a îmbunătăți experiența conținutului pe dispozitivele Unicode. Astăzi, pentru a ajuta țara să își continue tranziția la Unicode, anunțăm că am implementat convertoare de fonturi în Facebook și Messenger. Pentru că știm că această tranziție va dura ceva timp, convertorul nostru Zawgyi-în-Unicode va continua să le permită persoanelor care fac tranziția la Unicode să citească postările, mesajele și comentariile chiar dacă prietenii și familia lor nu au făcut încă tranziția la dispozitivele lor. Această postare va detalia provocările tehnice implicate în integrarea acestor convertoare, inclusiv modul în care diferențiem textul Zawgyi de Unicode, cum ne putem da seama dacă un dispozitiv folosește Zawgyi sau Unicode și cum să facem conversia între cele două, precum și unele lecții pe care le-am învățat pe parcurs.
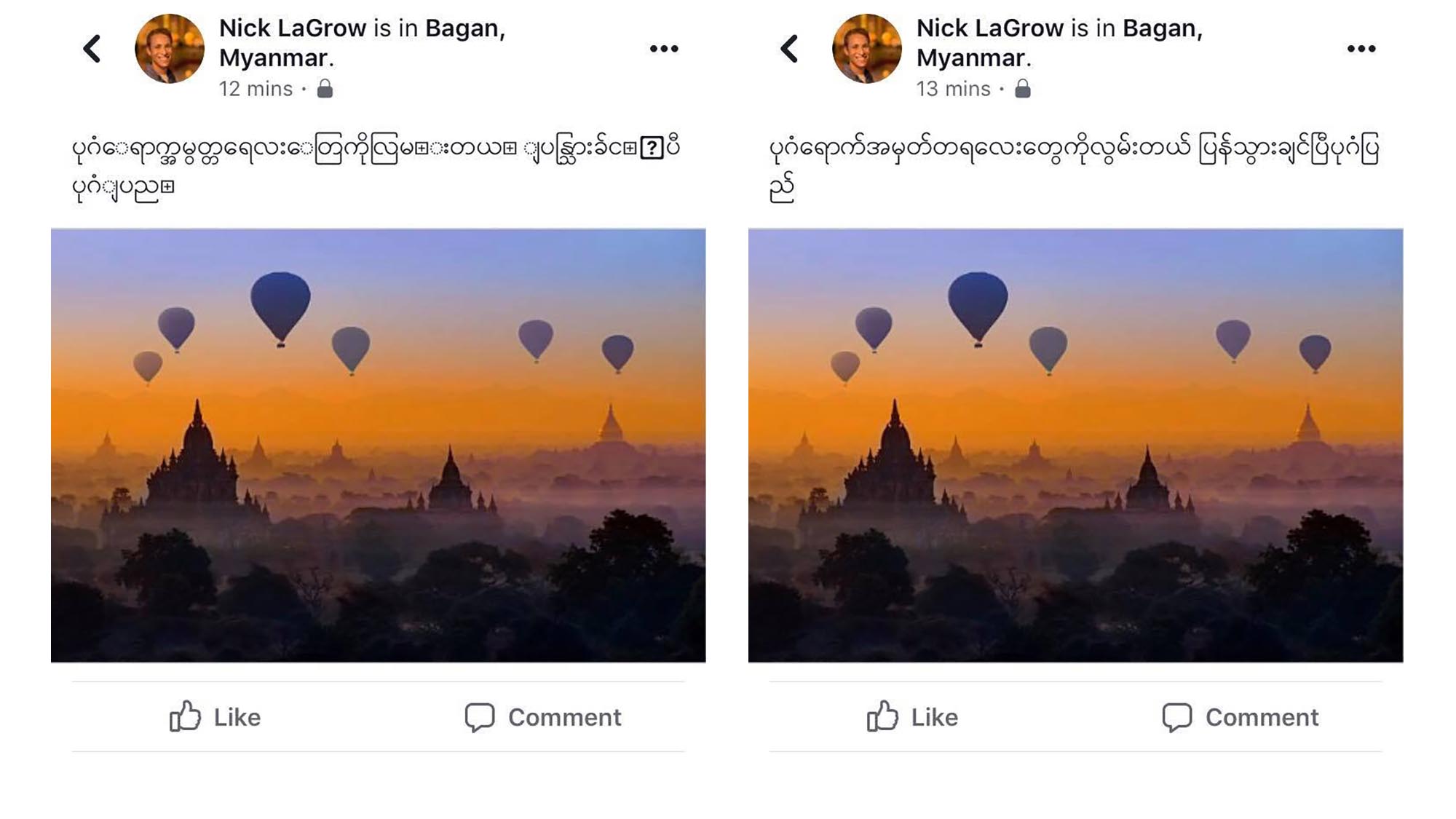
De ce Unicode?
Unicode a fost conceput ca un sistem global pentru a permite tuturor persoanelor din lume să folosească propria limbă pe dispozitivele lor. Dar majoritatea dispozitivelor din Myanmar folosesc încă Zawgyi, care este incompatibilă cu Unicode. Ceea ce înseamnă că persoanele care folosesc aceste dispozitive se confruntă acum cu probleme de compatibilitate între platforme, sisteme de operare și limbaje de programare. Pentru a ajunge mai bine la publicul lor, producătorii de conținut din Myanmar postează adesea atât în Zawgyi, cât și în Unicode într-o singură postare, ca să nu mai vorbim de engleză sau de alte limbi. Codificarea Zawgyi utilizează mai multe puncte de cod pentru caractere și interpretări combinate; necesită de două ori mai multe puncte de cod pentru a reprezenta doar un subset al alfabetului; iar punctele de cod ale vocalelor pot apărea înainte sau după o consoană (astfel încât CAT sau CTA se citesc la fel), ceea ce duce la probleme de căutare și comparare, chiar și în cadrul unui singur document. Acest lucru face ca orice fel de comunicare între sisteme să fie o provocare uriașă.
Facebook susține Unicode pentru că oferă suport și un standard consistent pentru fiecare limbă. În Myanmar, în special, susținem tranziția la Unicode deoarece:
- Le permite oamenilor din Myanmar să utilizeze aplicațiile și serviciile noastre în alte limbi decât birmaneza. Zawgyi acceptă introducerea doar a textului în birmaneză, în timp ce Unicode permite introducerea limbilor minoritare vorbite în Myanmar, cum ar fi Shan și Mon.
- Oferă o formă normalizată pentru limbile din Myanmar, ceea ce ne ajută să protejăm persoanele care utilizează aplicațiile noastre prin detectarea conținutului care încalcă politicile și îmbunătățește considerabil performanța instrumentelor de căutare.
- Ne face mai eficientă examinarea rapoartelor privind conținutul potențial dăunător de pe Facebook, iar cei care analizează conținutul vor putea examina problemele fără a fi nevoie să știe cum a fost codificat conținutul.
O abordare în trei direcții
Când am început să analizăm codificarea Myanmar, prioritatea noastră principală a fost să ne asigurăm că sistemele noastre care detectează conținutul dăunător, cum ar fi discursul instigator la ură, nu se împiedică de Zawgyi. Am explicat obiectivele noastre în acest sens în această postare pe blog. Aceleași provocări (cum ar fi mai multe puncte de codare și interpretări combinate) care fac dificilă comunicarea sistemelor care utilizează Zawgyi, fac dificilă și antrenarea clasificatorilor noștri și a sistemelor de inteligență artificială pentru a detecta eficient conținutul care încalcă politicile.
Din fericire, nu suntem singura companie care lucrează la această problemă și am reușit să folosim biblioteca open source myanmar-tools a Google pentru a implementa soluția noastră. Biblioteca myanmar-tools a reprezentat un upgrade major, în ceea ce privește acuratețea detectării și a conversiei, față de biblioteca bazată pe regex pe care o foloseam. Cu aproximativ un an în urmă, am integrat detectarea și conversia fonturilor pentru a converti tot conținutul în Unicode înainte de a trece prin clasificatorii noștri. Implementarea conversiei automate în toate produsele noastre nu a fost o sarcină simplă. Fiecare dintre cerințele pentru autoconversie – detectarea codificării conținutului, detectarea codificării dispozitivelor și conversia – a avut propriile provocări.
Detectarea codificării conținutului
Pentru a efectua autoconversia, trebuie mai întâi să cunoaștem codificarea conținutului, adică codificarea utilizată atunci când textul a fost introdus pentru prima dată. Din păcate, Zawgyi și Unicode folosesc aceeași gamă de puncte de cod pentru a reprezenta caracterele din birmaneză și din alte limbi. Din această cauză, nu putem spune dacă o listă de puncte de cod care reprezintă un șir de caractere ar trebui să fie redată cu Zawgyi sau Unicode. De asemenea, nu orice șir de puncte de cod are sens în ambele codificări. Cu un model antrenat pe text creat în Zawgyi și Unicode, putem evalua probabilitatea ca un anumit șir de caractere să fi fost creat cu o tastatură Zawgyi sau Unicode.

Detecția noastră se bazează pe abordarea bibliotecii myanmar-tools. Antrenăm un model de învățare automată (ML) pe eșantioane de conținut public de pe Facebook pentru care cunoaștem deja codificarea conținutului. Acest model ține evidența probabilității ca o serie de puncte de cod să apară în Unicode față de Zawgyi pentru fiecare eșantion. Ulterior, atunci când determinăm codificarea conținutului cuiva, ne uităm la predicția modelului pentru a vedea dacă este mai probabil ca acea secvență de puncte de cod să fi fost introdusă în Unicode sau în Zawgyi – și folosim acest rezultat ca și codificare a conținutului.
Detectarea codificării dispozitivului
În continuare, trebuie să știm ce codificare a fost folosită de telefonul unei persoane (adică codificarea dispozitivului) pentru a înțelege dacă trebuie să efectuăm o conversie a codificării fontului. Pentru a face acest lucru, putem profita de faptul că, într-o codificare, combinarea mai multor puncte de cod va combina fragmente de text pentru a crea un singur caracter, în timp ce în cealaltă codificare acele două puncte de cod ar putea reprezenta caractere separate. Dacă creăm un șir de caractere pe dispozitiv și verificăm lățimea acelui șir, ne putem da seama ce codificare de font folosește dispozitivul pentru a reda șirul. Odată ce avem aceste informații, putem spune serverului, în viitoarele cereri web, că dispozitivul utilizează Zawgyi sau Unicode și ne putem asigura că orice conținut preluat corespunde. În Myanmar, logica noastră din partea clientului determină dacă dispozitivul în cauză folosește Zawgyi sau Unicode și trimite această codificare ca parte a câmpului locale din cererea web (de exemplu, my_Qaag_MM).
Conversie
În continuare, serverul verifică dacă încarcă conținut în limba birmană. Dacă codificarea conținutului și codificarea dispozitivului nu corespund, trebuie să convertim conținutul într-un format pe care dispozitivul cititorului îl va reda corect. De exemplu, dacă o postare a fost introdusă cu o codificare de conținut Unicode, dar este citită pe un dispozitiv codificat Zawgyi, convertim textul postării în Zawgyi înainte de a-l reda pe dispozitivul Zawgyi.
Este important să antrenați acest model pe conținutul Facebook și nu pe alt conținut accesibil publicului de pe web. Oamenii scriu diferit pe Facebook față de cum ar scrie pe o pagină web sau într-o lucrare științifică: Postările și mesajele de pe Facebook sunt, în general, mai scurte și mai puțin formale și conțin abrevieri, argou și greșeli de scriere. Dorim ca predicțiile noastre să fie cât mai exacte pentru conținutul pe care oamenii îl partajează și îl citesc pe aplicațiile noastre.
Integrarea conversiei automate la scara Facebook
Provocarea următoare a fost să integrăm această conversie în diferitele tipuri de conținut pe care oamenii le pot crea pe aplicațiile noastre. Textul Zawgyi a fost introdus atât pentru actualizări de stare, cât și pentru nume de utilizator, comentarii, subtitrări video, mesaje private și multe altele. Executarea detecției și a conversiei noastre de fiecare dată când cineva aduce orice tip de conținut ar fi prohibitivă din punct de vedere al timpului și al resurselor necesare. Nu există o singură conductă prin care să treacă tot conținutul posibil de pe Facebook, ceea ce face dificilă capturarea conținutului Zawgyi peste tot pe unde ar putea intra cineva. În plus, nu toate solicitările web sunt făcute de pe dispozitivul unei persoane. De exemplu, atunci când notificările și mesajele sunt împinse către dispozitive, nu putem rula logica de codificare a dispozitivului. De asemenea, mesajele și comentariile sunt adesea foarte scurte, ceea ce scade precizia de detectare.
Convertorul de fonturi este acum complet implementat pe Facebook și Messenger. Aceste instrumente vor face o mare diferență pentru milioanele de persoane din Myanmar care utilizează aplicațiile noastre pentru a comunica cu prietenii și familia. Pentru a continua să sprijinim populația din Myanmar în această tranziție la Unicode, analizăm posibilitatea de a extinde instrumentele noastre de conversie automată la mai multe produse din familia Facebook, precum și de a îmbunătăți calitatea detecției și a conversiei automate. De asemenea, intenționăm să continuăm să contribuim la biblioteca open source myanmar-tools pentru a-i ajuta pe alții să construiască instrumente care să sprijine această tranziție.
.