
Organizația dumneavoastră dorește să adune și să analizeze date pentru a afla tendințele, dar într-un mod care să protejeze confidențialitatea? Sau poate că folosiți deja instrumente diferențiale de confidențialitate, dar doriți să vă extindeți (sau să vă împărtășiți) cunoștințele? În ambele cazuri, această serie de bloguri este pentru dumneavoastră.
De ce facem această serie? Anul trecut, NIST a lansat un Spațiu de colaborare în domeniul ingineriei confidențialității pentru a agrega instrumente, soluții și procese cu sursă deschisă care sprijină ingineria confidențialității și gestionarea riscurilor. În calitate de moderatori ai Spațiului de colaborare, am ajutat NIST să reunească instrumente diferențiate de confidențialitate în cadrul domeniului tematic al de-identificării. NIST a publicat, de asemenea, Cadrul de confidențialitate: A Tool for Improving Privacy through Enterprise Risk Management (Un instrument pentru îmbunătățirea confidențialității prin gestionarea riscurilor la nivel de întreprindere) și o foaie de parcurs însoțitoare care a recunoscut o serie de domenii de provocare pentru confidențialitate, inclusiv subiectul de-identificare. Acum am dori să ne folosim de Collaboration Space pentru a contribui la eliminarea lacunelor din foaia de parcurs în ceea ce privește de-identificarea. Scopul nostru final este de a sprijini NIST în transformarea acestei serii în orientări mai aprofundate privind confidențialitatea diferențiată.
Care post va începe cu noțiuni conceptuale de bază și cazuri de utilizare practică, cu scopul de a ajuta profesioniștii, cum ar fi proprietarii de procese de afaceri sau personalul programului de confidențialitate, să învețe doar atât cât să fie periculos (glumesc). După ce vom acoperi elementele de bază, vom examina instrumentele disponibile și abordările tehnice ale acestora pentru inginerii de confidențialitate sau profesioniștii IT interesați de detaliile de implementare. Pentru ca toată lumea să se pună la curent, această primă postare va oferi informații generale despre confidențialitatea diferențiată și va descrie câteva concepte cheie pe care le vom folosi în restul seriei.
Provocarea
Cum putem folosi datele pentru a afla despre o populație, fără a afla despre anumite persoane din cadrul populației? Luați în considerare aceste două întrebări:
- „Câte persoane locuiesc în Vermont?”
- „Câte persoane cu numele Joe Near locuiesc în Vermont?”
Prima dezvăluie o proprietate a întregii populații, în timp ce a doua dezvăluie informații despre o singură persoană. Trebuie să putem afla despre tendințele din populație, împiedicând în același timp posibilitatea de a afla ceva nou despre o anumită persoană. Acesta este obiectivul multor analize statistice ale datelor, cum ar fi statisticile publicate de Biroul de recensământ al SUA, și al învățării automate în sens mai larg. În fiecare dintre aceste contexte, modelele au scopul de a dezvălui tendințe în populații, nu de a reflecta informații despre un singur individ.
Dar cum putem răspunde la prima întrebare „Câți oameni trăiesc în Vermont?”? – la care ne vom referi ca fiind o interogare – împiedicând în același timp să se răspundă la a doua întrebare „Câte persoane cu numele Joe Near trăiesc în Vermont?”. Soluția cea mai utilizată pe scară largă se numește de-identificare (sau anonimizare), care elimină informațiile de identificare din setul de date. (În general, vom presupune că un set de date conține informații colectate de la mai multe persoane). O altă opțiune este de a permite doar interogări agregate, cum ar fi o medie a datelor. Din păcate, înțelegem acum că niciuna dintre aceste abordări nu oferă de fapt o protecție puternică a confidențialității. Seturile de date neidentificate sunt supuse atacurilor de corelare a bazelor de date. Agregarea protejează confidențialitatea numai în cazul în care grupurile care sunt agregate sunt suficient de mari și, chiar și atunci, atacurile asupra confidențialității sunt încă posibile.
Confidențialitatea diferențială
Confidențialitatea diferențială este o definiție matematică a ceea ce înseamnă să ai confidențialitate. Nu este un proces specific, cum ar fi de-identificarea, ci o proprietate pe care o poate avea un proces. De exemplu, este posibil să se demonstreze că un algoritm specific „satisface” confidențialitatea diferențială.
Informal, confidențialitatea diferențială garantează următoarele pentru fiecare persoană care contribuie cu date pentru analiză: rezultatul unei analize cu confidențialitate diferențială va fi aproximativ același, indiferent dacă contribuiți sau nu cu datele dumneavoastră. O analiză diferențiat privată este adesea numită mecanism, iar noi o notăm ℳ.
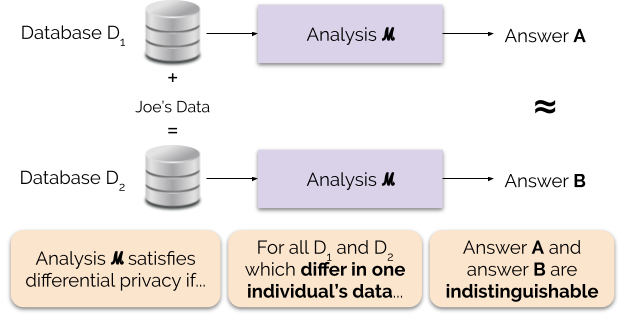
Figura 1 ilustrează acest principiu. Răspunsul „A” este calculat fără datele lui Joe, în timp ce răspunsul „B” este calculat cu datele lui Joe. Confidențialitatea diferențială spune că cele două răspunsuri ar trebui să fie imposibil de distins. Acest lucru implică faptul că oricine vede rezultatul nu va putea spune dacă au fost folosite sau nu datele lui Joe sau ce conțineau datele lui Joe.
Controlăm puterea garanției de confidențialitate prin reglarea parametrului de confidențialitate ε, numit și pierdere de confidențialitate sau buget de confidențialitate. Cu cât valoarea parametrului ε este mai mică, cu atât rezultatele sunt mai nediferențiate și, prin urmare, cu atât mai mult sunt protejate datele fiecărui individ în parte.
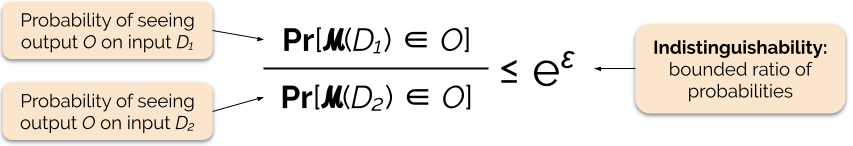
Potem răspunde adesea la o interogare cu confidențialitate diferențială prin adăugarea unui zgomot aleatoriu la răspunsul interogării. Provocarea constă în a determina unde se adaugă zgomotul și cât de mult se adaugă. Unul dintre cele mai frecvent utilizate mecanisme de adăugare a zgomotului este mecanismul Laplace .
Întrebările cu o sensibilitate mai mare necesită adăugarea mai mult zgomot pentru a satisface o anumită cantitate `epsilon` de confidențialitate diferențială, iar acest zgomot suplimentar are potențialul de a face rezultatele mai puțin utile. Vom descrie sensibilitatea și acest compromis între confidențialitate și utilitate mai detaliat în postările viitoare de pe blog.
Beneficii ale confidențialității diferențiale
Confidențialitatea diferențială are mai multe avantaje importante față de tehnicile de confidențialitate anterioare:
- Se presupune că toate informațiile sunt informații de identificare, eliminând sarcina dificilă (și uneori imposibilă) de a ține cont de toate elementele de identificare ale datelor.
- Este rezistentă la atacurile asupra confidențialității bazate pe informații auxiliare, astfel încât poate preveni în mod eficient atacurile de legătură care sunt posibile asupra datelor dezidentificate.
- Este compozițională – putem determina pierderea de confidențialitate a executării a două analize cu confidențialitate diferențiată pe aceleași date prin simpla însumare a pierderilor individuale de confidențialitate pentru cele două analize. Compoziționalitatea înseamnă că putem oferi garanții semnificative cu privire la confidențialitate chiar și atunci când eliberăm rezultatele mai multor analize din aceleași date. Tehnici precum de-identificarea nu sunt compoziționale, iar difuzările multiple în cadrul acestor tehnici pot duce la o pierdere catastrofală de confidențialitate.
Aceste avantaje sunt principalele motive pentru care un practician ar putea alege confidențialitatea diferențiată în locul unei alte tehnici de confidențialitate a datelor. Un dezavantaj actual al confidențialității diferențiale este faptul că este destul de nouă, iar instrumentele, standardele și cele mai bune practici solide nu sunt ușor accesibile în afara comunităților de cercetare academică. Cu toate acestea, preconizăm că această limitare poate fi depășită în viitorul apropiat datorită cererii din ce în ce mai mari de soluții robuste și ușor de utilizat pentru confidențialitatea datelor.
Coming Up Next
Stay tuned: următoarea noastră postare se va baza pe aceasta prin explorarea problemelor de securitate implicate în implementarea sistemelor pentru confidențialitatea diferențială, inclusiv diferența dintre modelele centrale și locale ale confidențialității diferențiale.
Înainte de a pleca – ne dorim ca această serie și orientările ulterioare ale NIST să contribuie la creșterea accesibilității confidențialității diferențiale. Puteți ajuta. Fie că aveți întrebări cu privire la aceste postări, fie că puteți împărtăși cunoștințele dumneavoastră, sperăm că vă veți implica alături de noi, astfel încât să putem avansa această disciplină împreună.
Garfinkel, Simson, John M. Abowd și Christian Martindale. „Understanding database reconstruction attacks on public data” (Înțelegerea atacurilor de reconstrucție a bazelor de date asupra datelor publice). Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. „When the signal is in the noise: exploiting diffix’s sticky noise”. Al 28-lea Simpozion de securitate USENIX (USENIX Security 19). 2019.
Dinur, Irit, și Kobbi Nissim. „Revealing information while preserving privacy” (Dezvăluirea informațiilor în timp ce se păstrează confidențialitatea). Proceedings of the twenty-second ACMMOD-SIGACT-SIGART symposium on Principles of database systems (Proceedings of the twenty-second ACMMOD-SIGACT-SIGART symposium on Principles of database systems). 2003.
Sweeney, Latanya. „Datele demografice simple identifică adesea oamenii în mod unic”. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. „Calibrating noise to sensitivity in private data analysis”. Conferința Theory of cryptography. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke și Salil Vadhan. „Confidențialitate diferențială: A primer for a non-technical audience”. Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia și Aaron Roth. „Bazele algoritmice ale confidențialității diferențiale”. Foundations and Trends in Theoretical Computer Science 9, nr. 3-4 (2014): 211-407.