Zrzeczenie się odpowiedzialności 1 : Ten artykuł jest tylko wprowadzeniem do funkcji MFCC i jest przeznaczony dla tych, którzy potrzebują łatwego i szybkiego zrozumienia tego samego. Szczegółowa matematyka i zawiłości nie są omawiane.
Nigdy nie pracowałem w dziedzinie przetwarzania mowy sam, harking na słowo „MFCC” (dość często używane przez rówieśników) zostawił mnie z nieodpowiednim zrozumieniem, że jest to nazwa nadana szczególnemu rodzajowi „cechy” wyodrębnionej z sygnałów audio (podobne do krawędzi, które stanowią rodzaj cechy wyodrębnionej z obrazów).


Zajęło mi sporo czytania z wielu źródeł, aby uchwycić zrozumienie nowicjusza, czym są cechy MFCC. Więc zdecydowałem się pomóc kolegom w potrzebie poprzez kompilację informacji, które zebrałem w łatwy do zrozumienia sposób.
Zacznijmy od rozwinięcia akronimu MFCC – Mel Frequency Cepstral Co-efficients.
Czy kiedykolwiek słyszałeś słowo cepstral przed? Prawdopodobnie nie. Jest to spektralne z odwróconą specyfikacją! Dlaczego jednak? Dla bardzo podstawowego zrozumienia, cepstrum jest informacją o szybkości zmian w pasmach spektralnych. W konwencjonalnej analizie sygnałów czasowych, każdy składnik okresowy (np. echo) pokazuje się jako ostre szczyty w odpowiadającym mu widmie częstotliwości (tj. widmie Fouriera). Jest ono uzyskiwane poprzez zastosowanie transformaty Fouriera na sygnale czasowym). Można to zobaczyć na poniższym obrazku.

Po wykonaniu logu wielkości tego widma Fouriera, a następnie ponownym wykonaniu widma tego logu przez transformację kosinusową (wiem, że brzmi to skomplikowanie, ale wytrzymaj ze mną proszę!), obserwujemy pik wszędzie tam, gdzie jest element okresowy w oryginalnym sygnale czasowym. Ponieważ stosujemy transformatę na samym widmie częstotliwości, otrzymane widmo nie jest ani w dziedzinie częstotliwości, ani w dziedzinie czasu i dlatego Bogert et al. zdecydowali się nazwać je dziedziną kwefaliczną. I to widmo logu widma sygnału czasu zostało nazwane cepstrum (ta-da!).
Poniższy obraz jest podsumowaniem wyżej wyjaśnionych kroków.

Cepstrum zostało po raz pierwszy wprowadzone do charakteryzowania ech sejsmicznych powstających w wyniku trzęsień ziemi.
Pitch jest jedną z cech sygnału mowy i jest mierzony jako częstotliwość sygnału. Skala Mel to skala, która odnosi postrzeganą częstotliwość tonu do rzeczywistej zmierzonej częstotliwości. Skaluje ona częstotliwość w celu lepszego dopasowania do tego, co może usłyszeć ludzkie ucho (ludzie są w stanie lepiej zidentyfikować małe zmiany w mowie przy niższych częstotliwościach). Skala ta została wyprowadzona na podstawie zestawów eksperymentów na ludziach. Pozwól mi dać ci intuicyjne wyjaśnienie tego, co skala mel ujmuje.
Zakres ludzkiego słuchu wynosi od 20Hz do 20kHz. Wyobraź sobie melodię na 300 Hz. To brzmiałoby coś jak standardowy ton dialera telefonu stacjonarnego. Teraz wyobraź sobie melodię o częstotliwości 400 Hz (nieco wyższy ton dialera). Teraz porównaj odległość pomiędzy tymi dwoma sygnałami, jakkolwiek może to być postrzegane przez Twój mózg. Teraz wyobraź sobie sygnał o częstotliwości 900 Hz (podobny do dźwięku sprzężenia zwrotnego z mikrofonu) oraz dźwięk o częstotliwości 1kHz. Postrzegana odległość między tymi dwoma dźwiękami może wydawać się większa niż między pierwszymi dwoma, chociaż rzeczywista różnica jest taka sama (100Hz). Skala mel próbuje uchwycić takie różnice. Częstotliwość mierzona w hercach (f) może być przeliczona na skalę Mel za pomocą następującego wzoru :
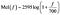
Każdy dźwięk generowany przez człowieka jest określany przez kształt jego traktu głosowego (włączając w to język, zęby, itp.). Jeśli ten kształt może być określony poprawnie, każdy wyprodukowany dźwięk może być dokładnie reprezentowany. Obwiednia czasowego spektrum mocy sygnału mowy jest reprezentatywna dla traktu głosowego, a MFCC (który jest niczym innym jak współczynnikami, które tworzą cepstrum częstotliwości Mel) dokładnie reprezentuje tę obwiednię. Poniższy schemat blokowy jest krokowym podsumowaniem tego, jak doszliśmy do MFCC:
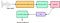
Tutaj, Filter Bank odnosi się do filtrów Mel (pokrywających się ze skalą Mel) a Cepstral Coefficients są niczym innym jak MFCC.
TL; DR – cechy MFCC reprezentują fonemy (odrębne jednostki dźwięku), ponieważ kształt traktu głosowego (który jest odpowiedzialny za generowanie dźwięku) jest w nich manifestowany.
Zrzeczenie się odpowiedzialności 2 : Wszystkie obrazy pochodzą z Google images.
.