Myanmar jest obecnie jedynym krajem na świecie o znaczącej obecności w Internecie, który nie ustandaryzował się na Unicode, międzynarodowy standard kodowania tekstu. Zamiast tego, Zawgyi jest dominującym krojem pisma używanym do kodowania znaków języka birmańskiego. Brak jednego standardu spowodował problemy techniczne dla wielu firm, które dostarczają aplikacje i usługi mobilne w Birmie. Utrudnia to komunikację na platformach cyfrowych, ponieważ treści napisane w Unicode wydają się zniekształcone użytkownikom Zawgyi i vice versa. Jest to problem dla aplikacji takich jak Facebook i Messenger, ponieważ posty, wiadomości i komentarze napisane w jednym kodowaniu są nieczytelne w innym. Brak standaryzacji wokół Unicode utrudnia automatyzację i proaktywne wykrywanie treści naruszających prawo, może osłabić bezpieczeństwo konta, sprawia, że zgłaszanie potencjalnie szkodliwych treści na Facebooku jest mniej efektywne i oznacza mniejsze wsparcie dla języków w Myanmarze poza birmańskim.
W zeszłym roku, aby wesprzeć przejście Myanmaru na Unicode, usunęliśmy Zawgyi jako opcję języka interfejsu dla nowych użytkowników Facebooka. Następnie pracowaliśmy nad zapewnieniem, że nasze klasyfikatory mowy nienawiści i innych treści naruszających zasady nie będą się potykać o treści Zawgyi i rozpoczęliśmy prace nad integracją konwerterów czcionek, aby poprawić wrażenia z treści na urządzeniach Unicode. Dziś, aby pomóc krajowi w przejściu na Unicode, ogłaszamy, że wdrożyliśmy konwertery czcionek w Facebooku i Messengerze. Ponieważ wiemy, że przejście na Unicode wymaga czasu, nasz konwerter z Zawgyi na Unicode pozwoli osobom przechodzącym na Unicode czytać posty, wiadomości i komentarze, nawet jeśli ich znajomi i rodzina nie przestawili jeszcze swoich urządzeń na Unicode. Ten post będzie opisywał wyzwania techniczne związane z integracją tych konwerterów, w tym jak odróżnić tekst Zawgyi od Unicode, jak stwierdzić czy urządzenie używa Zawgyi czy Unicode, i jak konwertować między nimi, jak również kilka lekcji, których nauczyliśmy się po drodze.
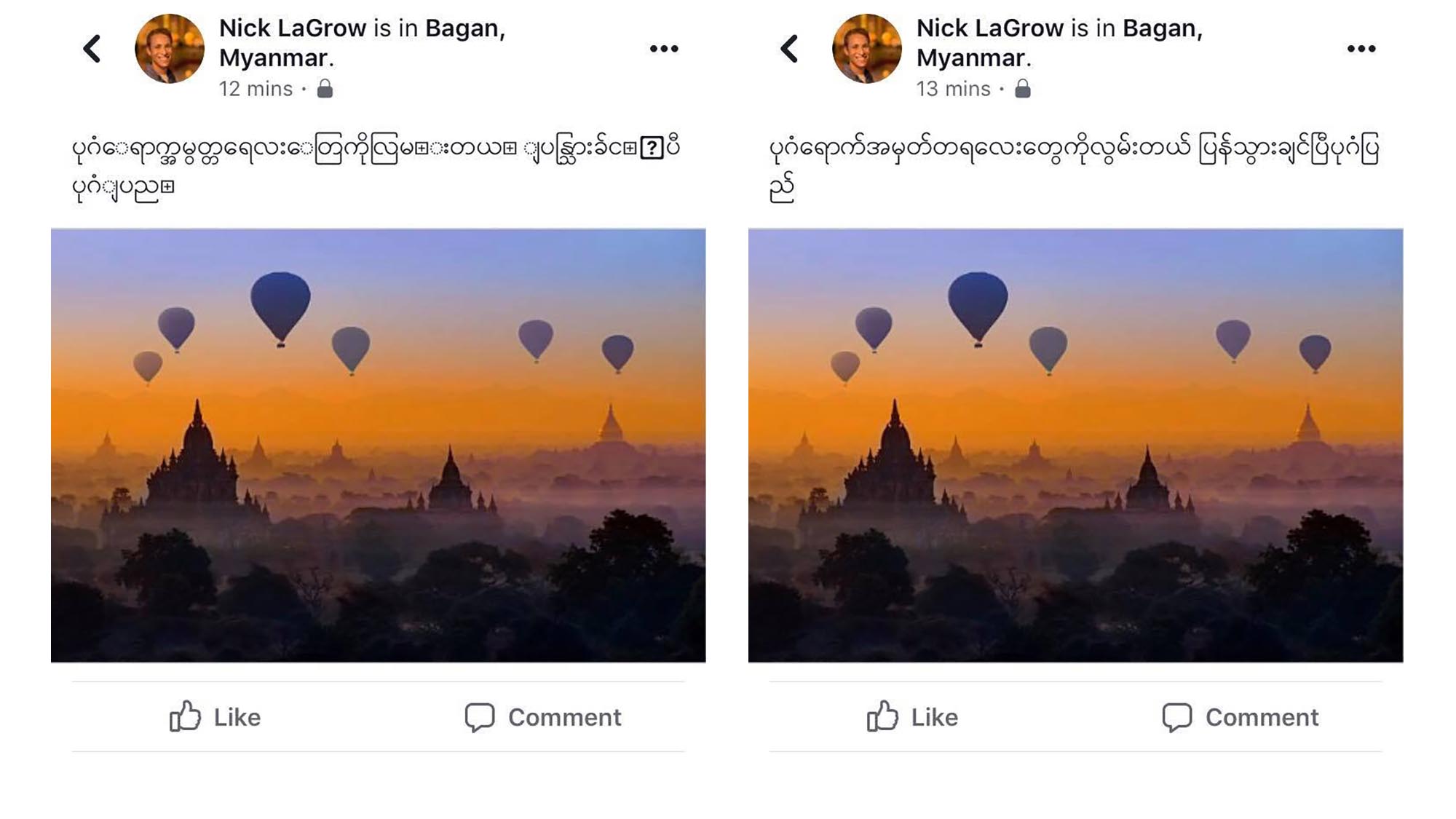
Dlaczego Unicode?
Unicode został zaprojektowany jako globalny system, aby umożliwić każdemu na świecie używanie własnego języka na swoich urządzeniach. Ale większość urządzeń w Myanmarze nadal używa języka Zawgyi, który jest niekompatybilny z Unicode. Oznacza to, że ludzie korzystający z tych urządzeń mają teraz do czynienia z problemami z kompatybilnością na różnych platformach, w różnych systemach operacyjnych i językach programowania. Aby lepiej dotrzeć do swoich odbiorców, producenci treści w Myanmarze często publikują w jednym poście zarówno w Zawgyi, jak i Unicode, nie wspominając już o języku angielskim czy innych językach. Kodowanie Zawgyi wykorzystuje wiele punktów kodowych dla znaków i połączonych renderingów; wymaga dwukrotnie większej liczby punktów kodowych, aby reprezentować tylko podzbiór pisma; a punkty kodowe samogłosek mogą pojawiać się przed lub po spółgłosce (więc CAT lub CTA czyta się tak samo), co prowadzi do problemów z wyszukiwaniem i porównywaniem, nawet w obrębie jednego dokumentu. To sprawia, że jakikolwiek rodzaj komunikacji między systemami jest ogromnym wyzwaniem.
Facebook wspiera Unicode, ponieważ oferuje on wsparcie i spójny standard dla każdego języka. W Myanmarze w szczególności popieramy przejście na Unicode, ponieważ:
- To pozwala ludziom w Myanmarze korzystać z naszych aplikacji i usług w językach innych niż birmański. Zawgyi umożliwia wprowadzanie wyłącznie tekstu birmańskiego, natomiast Unicode umożliwia wprowadzanie tekstów w językach mniejszości używanych w Myanmarze, takich jak Shan i Mon.
- Oferuje znormalizowaną formę dla języków w Myanmarze, co pomaga nam chronić ludzi korzystających z naszych aplikacji poprzez wykrywanie treści naruszających politykę i znacznie poprawia wydajność narzędzi wyszukiwania.
- Dzięki temu możemy skuteczniej sprawdzać zgłoszenia potencjalnie szkodliwych treści na Facebooku, a osoby zajmujące się przeglądaniem treści będą mogły analizować problemy bez konieczności znajomości sposobu kodowania treści.
Podejście oparte na trzech elementach
Gdy po raz pierwszy zaczęliśmy przyglądać się kodowaniu w języku Myanmar, naszym głównym priorytetem było upewnienie się, że nasze systemy wykrywające szkodliwe treści, takie jak mowa nienawiści, nie potykają się o język Zawgyi. Nasze cele w tym zakresie wyjaśniliśmy w tym wpisie na blogu. Te same wyzwania (takie jak wiele punktów kodu i połączone renderowanie), które utrudniają systemom komunikację za pomocą Zawgyi, utrudniają również szkolenie naszych klasyfikatorów i systemów sztucznej inteligencji w celu skutecznego wykrywania treści naruszających zasady.
Na szczęście nie jesteśmy jedyną firmą pracującą nad tym zagadnieniem i udało nam się wykorzystać bibliotekę myanmar-tools Google’a open source, aby wdrożyć nasze rozwiązanie. Biblioteka myanmar-tools była dużym usprawnieniem, jeśli chodzi o dokładność wykrywania i konwersji, w stosunku do biblioteki opartej na regex, której używaliśmy. Około rok temu zintegrowaliśmy wykrywanie i konwersję czcionek, aby przekonwertować całą zawartość na Unicode przed przejściem przez nasze klasyfikatory. Wdrożenie autokonwersji we wszystkich naszych produktach nie było prostym zadaniem. Każdy z wymogów autokonwersji – wykrywanie kodowania treści, wykrywanie kodowania urządzeń i konwersja – miał swoje własne wyzwania.
Wykrywanie kodowania treści
Aby przeprowadzić autokonwersję, musimy najpierw poznać kodowanie treści, czyli kodowanie użyte podczas wprowadzania tekstu. Niestety, Zawgyi i Unicode używają tego samego zakresu punktów kodowych do reprezentowania znaków w birmańskim i innych językach. Z tego powodu nie jesteśmy w stanie stwierdzić, czy lista punktów kodowych reprezentująca łańcuch znaków powinna być renderowana w Zawgyi czy Unicode. Ponadto, nie każdy ciąg punktów kodowych ma sens w obu kodowaniach.

Nasza detekcja opiera się na podejściu zastosowanym w bibliotece myanmar-tools. Trenujemy model uczenia maszynowego (ML) na publicznych próbkach treści na Facebooku, dla których znamy już kodowanie treści. Model ten śledzi prawdopodobieństwo wystąpienia serii punktów kodowych w Unicode i w Zawgyi dla każdej próbki. Później, podczas określania kodowania zawartości czyjejś treści, patrzymy na przewidywania modelu dotyczące tego, czy ta sekwencja punktów kodowych była bardziej prawdopodobna do wprowadzenia w Unicode czy w Zawgyi – i używamy tego wyniku jako kodowania zawartości.
Detekcja kodowania urządzenia
Następnie, musimy wiedzieć, jakie kodowanie zostało użyte przez telefon danej osoby (tj. kodowanie urządzenia), aby zrozumieć, czy musimy wykonać konwersję kodowania czcionki. Aby to zrobić, możemy skorzystać z faktu, że w jednym kodowaniu połączenie kilku punktów kodowych połączy fragmenty tekstu w jeden znak, podczas gdy w innym kodowaniu te dwa punkty kodowe mogą reprezentować oddzielne znaki. Jeśli utworzymy ciąg znaków na urządzeniu i sprawdzimy jego szerokość, możemy stwierdzić, jakiego kodowania czcionek używa urządzenie do renderowania tego ciągu. Mając te informacje, możemy poinformować serwer, że urządzenie używa Zawgyi lub Unicode i upewnić się, że pobierana treść jest do nich dopasowana. W Myanmar, nasza logika po stronie klienta określa czy dane urządzenie używa Zawgyi czy Unicode i wysyła to kodowanie jako część pola locale w żądaniu sieciowym (np. my_Qaag_MM).
Konwersja
Następnie, serwer sprawdza, czy ładuje zawartość birmańską. Jeśli kodowanie treści i kodowanie urządzenia nie pasują do siebie, musimy przekonwertować treść do formatu, który urządzenie czytelnika będzie renderować poprawnie. Na przykład, jeśli post został wprowadzony z kodowaniem zawartości Unicode, ale jest czytany na urządzeniu z kodowaniem Zawgyi, konwertujemy tekst postu na Zawgyi przed wyrenderowaniem go na urządzeniu Zawgyi.
Ważne jest, aby trenować ten model na treściach z Facebooka, a nie na innych publicznie dostępnych treściach w sieci. Na Facebooku ludzie piszą inaczej niż na stronie internetowej czy w pracy naukowej: Posty i wiadomości na Facebooku są zazwyczaj krótsze i mniej formalne, zawierają skróty, slang i literówki. Chcemy, aby nasze przewidywania były jak najdokładniejsze dla treści, które ludzie udostępniają i czytają w naszych aplikacjach.
Integracja autokonwersji w skali Facebooka
Kolejnym wyzwaniem było zintegrowanie tej konwersji w różnych typach treści, które ludzie mogą tworzyć w naszych aplikacjach. Tekst Zawgyi został wprowadzony do aktualizacji statusu, jak również do nazw użytkowników, komentarzy, napisów wideo, prywatnych wiadomości i innych. Przeprowadzanie wykrywania i konwersji za każdym razem, gdy ktoś pobiera jakikolwiek typ treści, byłoby zbyt czasochłonne i wymagałoby dużych zasobów. Nie ma jednego potoku, przez który przechodzi cała możliwa zawartość Facebooka, co sprawia, że trudno jest wychwycić zawartość Zawgyi wszędzie tam, gdzie ktoś może ją wprowadzić. Ponadto, nie każde żądanie internetowe jest wykonywane z urządzenia danej osoby. Na przykład, gdy powiadomienia i wiadomości są wysyłane na urządzenia, nie możemy uruchomić logiki kodowania na urządzeniach. Również wiadomości i komentarze są często bardzo krótkie, co obniża dokładność wykrywania.
Konwerter czcionek jest teraz w pełni zaimplementowany na Facebooku i Messengerze. Te narzędzia zrobią wielką różnicę dla milionów ludzi w Myanmarze, którzy używają naszych aplikacji do komunikacji z przyjaciółmi i rodziną. Aby nadal wspierać mieszkańców Myanmaru w przejściu na Unicode, rozważamy rozszerzenie naszych narzędzi do automatycznej konwersji na więcej produktów z rodziny Facebooka, a także poprawę jakości naszego automatycznego wykrywania i konwersji. Zamierzamy również nadal przyczyniać się do rozwoju biblioteki open source myanmar-tools, aby pomóc innym w tworzeniu narzędzi wspierających to przejście.