
Czy Twoja organizacja chce agregować i analizować dane w celu poznania trendów, ale w sposób, który chroni prywatność? A może już korzystasz z różnych narzędzi ochrony prywatności, ale chcesz poszerzyć (lub podzielić się) swoją wiedzą? W obu przypadkach, ta seria blogów jest dla Ciebie.
Dlaczego robimy tę serię? W zeszłym roku NIST uruchomił Przestrzeń współpracy w zakresie inżynierii prywatności (Privacy Engineering Collaboration Space), aby zebrać narzędzia, rozwiązania i procesy open source, które wspierają inżynierię prywatności i zarządzanie ryzykiem. Jako moderatorzy Przestrzeni Współpracy pomogliśmy NIST zebrać różne narzędzia do ochrony prywatności w obszarze tematycznym deidentyfikacji. NIST opublikował również Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management oraz towarzyszącą jej mapę drogową, która rozpoznała szereg obszarów wyzwań dla prywatności, w tym temat de-identyfikacji. Teraz chcielibyśmy wykorzystać przestrzeń współpracy, aby pomóc w wypełnieniu luki w mapie drogowej dotyczącej de-identyfikacji. Naszym celem jest wsparcie NIST w przekształceniu tej serii w bardziej dogłębne wytyczne dotyczące prywatności różnicowej.
Każdy post rozpocznie się od podstaw koncepcyjnych i praktycznych przypadków użycia, mających na celu pomoc profesjonalistom, takim jak właściciele procesów biznesowych lub personel programów ochrony prywatności, w nauczeniu się wystarczająco dużo, aby być niebezpiecznym (tylko żartuję). Po omówieniu podstaw, przyjrzymy się dostępnym narzędziom i ich podejściu technicznemu dla inżynierów ds. ochrony prywatności lub informatyków zainteresowanych szczegółami wdrożenia. Aby wprowadzić wszystkich w temat, w tym pierwszym poście przedstawimy podstawy prywatności różnicowej i opiszemy kilka kluczowych pojęć, których będziemy używać w dalszej części serii.
Wyzwanie
Jak możemy wykorzystać dane, aby dowiedzieć się czegoś o populacji, nie poznając konkretnych osób w tej populacji? Rozważmy te dwa pytania:
- „Ile osób mieszka w Vermont?”
- „Ile osób o nazwisku Joe Near mieszka w Vermont?”
Pierwsze ujawnia właściwość całej populacji, podczas gdy drugie ujawnia informacje o jednej osobie. Musimy być w stanie dowiedzieć się o trendach w populacji, jednocześnie zapobiegając możliwości dowiedzenia się czegoś nowego o konkretnej osobie. Jest to cel wielu statystycznych analiz danych, takich jak statystyki publikowane przez U.S. Census Bureau, a także szerzej pojętego uczenia maszynowego. W każdym z tych ustawień modele mają na celu ujawnienie trendów w populacjach, a nie odzwierciedlenie informacji o pojedynczej osobie.
Ale jak możemy odpowiedzieć na pierwsze pytanie „Ile osób mieszka w Vermont?” – które będziemy nazywać zapytaniem – jednocześnie uniemożliwiając odpowiedź na drugie pytanie „Ile osób o nazwisku Joe Near mieszka w Vermont?”. Najczęściej stosowanym rozwiązaniem jest tzw. de-identyfikacja (lub anonimizacja), która usuwa informacje identyfikujące ze zbioru danych. (Zazwyczaj zakładamy, że zbiór danych zawiera informacje zebrane od wielu osób). Inną opcją jest zezwolenie tylko na zapytania zagregowane, takie jak średnia z danych. Niestety, obecnie rozumiemy, że żadne z tych podejść nie zapewnia silnej ochrony prywatności. Zbiory danych pozbawione identyfikacji są narażone na ataki typu „database-linkage”. Agregacja chroni prywatność tylko wtedy, gdy agregowane grupy są wystarczająco duże, a nawet wtedy ataki na prywatność są nadal możliwe.
Odmienność prywatności
Odmienność prywatności jest matematyczną definicją tego, co to znaczy mieć prywatność. Nie jest to konkretny proces, taki jak de-identyfikacja, ale właściwość, którą proces może mieć. Na przykład, możliwe jest udowodnienie, że określony algorytm „spełnia” zróżnicowaną prywatność.
Informalnie, zróżnicowana prywatność gwarantuje następującą rzecz dla każdej osoby, która wnosi dane do analizy: wynik różnie prywatnej analizy będzie mniej więcej taki sam, niezależnie od tego, czy wnosisz swoje dane, czy nie. Różnicowo prywatna analiza jest często nazywana mechanizmem, a my oznaczamy ją ℳ.
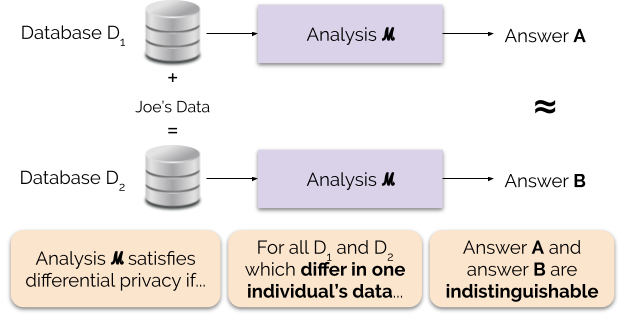
Rysunek 1 ilustruje tę zasadę. Odpowiedź „A” jest obliczana bez danych Joe, podczas gdy odpowiedź „B” jest obliczana z danymi Joe. Różnicowa prywatność mówi, że te dwie odpowiedzi nie powinny być rozróżnialne. Oznacza to, że ktokolwiek zobaczy dane wyjściowe nie będzie w stanie powiedzieć, czy dane Joe zostały użyte, czy nie, lub co dane Joe zawierały.
Kontrolujemy siłę gwarancji prywatności poprzez dostrajanie parametru prywatności ε, zwanego również stratą prywatności lub budżetem prywatności. Im niższa wartość parametru ε, tym bardziej nierozróżnialne są wyniki, a zatem tym bardziej chronione są dane każdej osoby.
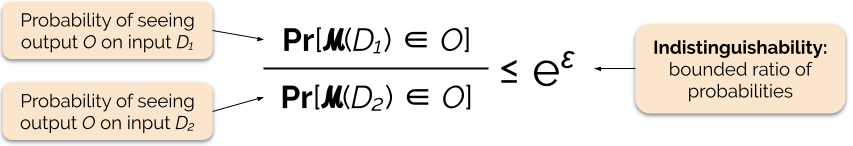
Często możemy odpowiedzieć na zapytanie z zachowaniem prywatności różnicowej poprzez dodanie losowego szumu do odpowiedzi na zapytanie. Wyzwanie polega na określeniu, gdzie dodać szum i ile go dodać. Jednym z najczęściej używanych mechanizmów dodawania szumu jest mechanizm Laplace’a.
Zapytania o wyższej czułości wymagają dodania więcej szumu w celu spełnienia określonej `epsilon` wielkości prywatności różnicowej, a ten dodatkowy szum może potencjalnie uczynić wyniki mniej użytecznymi. Opiszemy czułość i ten kompromis między prywatnością a użytecznością bardziej szczegółowo w przyszłych wpisach na blogu.
Korzyści z różnicowej prywatności
Różnicowa prywatność ma kilka ważnych zalet w porównaniu z poprzednimi technikami prywatności:
- Zakłada, że wszystkie informacje są informacjami identyfikującymi, eliminując trudne (i czasami niemożliwe) zadanie rozliczania wszystkich identyfikujących elementów danych.
- Jest odporna na ataki na prywatność oparte na informacjach pomocniczych, więc może skutecznie zapobiegać atakom na łączenie, które są możliwe w przypadku danych pozbawionych identyfikacji.
- Jest kompozycyjna – możemy określić utratę prywatności wynikającą z przeprowadzenia dwóch analiz o różnym stopniu prywatności na tych samych danych, po prostu sumując indywidualne straty prywatności dla tych dwóch analiz. Kompozycyjność oznacza, że możemy udzielić sensownych gwarancji prywatności nawet w przypadku udostępniania wyników wielu analiz na tych samych danych. Techniki takie jak de-identyfikacja nie są kompozycyjne, a wielokrotne udostępnianie w ramach tych technik może skutkować katastrofalną utratą prywatności.
Te zalety są głównymi powodami, dla których praktycy mogą wybrać zróżnicowaną prywatność zamiast jakiejś innej techniki ochrony danych. Obecną wadą różnicowej ochrony prywatności jest to, że jest ona dość nowa, a solidne narzędzia, standardy i najlepsze praktyki nie są łatwo dostępne poza akademickimi społecznościami badawczymi. Przewidujemy jednak, że to ograniczenie może zostać przezwyciężone w najbliższej przyszłości ze względu na rosnące zapotrzebowanie na solidne i łatwe w użyciu rozwiązania w zakresie prywatności danych.
Następny wpis
Zostańcie z nami: nasz następny wpis będzie opierał się na tym, badając kwestie bezpieczeństwa związane z wdrażaniem systemów dla prywatności różnicowej, w tym różnicę pomiędzy centralnym i lokalnym modelem prywatności różnicowej.
Zanim odejdziemy – chcemy, aby ta seria i kolejne wytyczne NIST przyczyniły się do uczynienia prywatności różnicowej bardziej dostępną. Możesz pomóc. Niezależnie od tego, czy masz pytania dotyczące tych postów, czy możesz podzielić się swoją wiedzą, mamy nadzieję, że zaangażujesz się z nami, abyśmy mogli wspólnie rozwijać tę dyscyplinę.
Garfinkel, Simson, John M. Abowd, and Christian Martindale. „Understanding database reconstruction attacks on public data”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. „When the signal is in the noise: exploiting diffix’s sticky noise.” 28 USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, and Kobbi Nissim. „Revealing information while preserving privacy.” Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. „Proste dane demograficzne często jednoznacznie identyfikują ludzi”. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. „Calibrating noise to sensitivity in private data analysis.” Konferencja Theory of cryptography. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan. „Zróżnicowana prywatność: Elementarz dla nietechnicznej publiczności.” Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, and Aaron Roth. „The algorithmic foundations of differential privacy.” Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.