Disclaimer 1 : Este artigo é apenas uma introdução às características do MFCC e destina-se a quem necessita de uma compreensão fácil e rápida das mesmas. Matemática detalhada e complexidades não são discutidas.
Nunca tendo trabalhado na área de processamento da fala eu próprio, ao usar a palavra “MFCC” (muitas vezes usada por pares) deixou-me com a compreensão inadequada de que é o nome dado a um tipo particular de “característica” extraída de sinais de áudio (semelhante a arestas que constituem um tipo de característica extraída de imagens).


Foi preciso um pouco de leitura de múltiplas fontes para compreender o que são as características do MFCC. Então eu decidi ajudar os companheiros em necessidade, compilando as informações que coletei de uma maneira fácil de entender.
Vamos começar por expandir a sigla MFCC – Mel Frequency Cepstral Co-efficients.
Ever ouviu a palavra cepstral antes? Provavelmente não. É espectral com as especificações invertidas! Mas porquê? Para um entendimento muito básico, cepstrum é a informação da taxa de mudança nas bandas espectrais. Na análise convencional de sinais de tempo, qualquer componente periódico (por exemplo, ecos) aparece como picos agudos no espectro de frequência correspondente (ou seja, espectro de Fourier. Isto é obtido aplicando uma transformada de Fourier no sinal de tempo). Isto pode ser visto na imagem seguinte.

Ao tomarmos o log da magnitude deste espectro de Fourier, e depois novamente tomando o espectro deste log por uma transformação cosseno (sei que parece complicado, mas por favor, tenham paciência!), observamos um pico onde quer que exista um elemento periódico no sinal de tempo original. Como aplicamos uma transformação no próprio espectro de frequência, o espectro resultante não está nem no domínio da frequência nem no domínio do tempo e por isso Bogert et al. decidiram chamar-lhe o domínio da quefrência. E este espectro do log do espectro do sinal de tempo foi nomeado cepstrum (ta-da!).
A imagem seguinte é um resumo dos passos acima explicados.

Cepstrum foi introduzido pela primeira vez para caracterizar os ecos sísmicos resultantes dos terramotos.
Pitch é uma das características de um sinal de fala e é medido como a frequência do sinal. A escala Mel é uma escala que relaciona a freqüência percebida de um tom com a freqüência real medida. Escala a frequência de modo a corresponder mais estreitamente ao que o ouvido humano pode ouvir (os humanos são melhores na identificação de pequenas alterações na fala em frequências mais baixas). Esta escala tem sido derivada de conjuntos de experiências em sujeitos humanos. Deixe-me dar-lhe uma explicação intuitiva do que a escala de mel capta.
A gama da audição humana é de 20Hz a 20kHz. Imagine uma melodia a 300 Hz. Isto soaria algo como o tom de discagem padrão de um telefone de linha fixa. Agora imagine uma melodia a 400 Hz (um tom de discador um pouco mais alto). Agora compare a distância entre estes dois como isto pode ser percebido pelo seu cérebro. Agora imagine um sinal de 900 Hz (semelhante a um som de feedback de microfone) e um som de 1kHz. A distância percebida entre estes dois sons pode parecer maior do que os dois primeiros, embora a diferença real seja a mesma (100Hz). A escala da melodia tenta captar tais diferenças. Uma frequência medida em Hertz (f) pode ser convertida para a escala de Mel usando a seguinte fórmula :
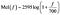
Um som gerado pelos humanos é determinado pela forma do seu tracto vocal (incluindo língua, dentes, etc). Se esta forma puder ser determinada correctamente, qualquer som produzido pode ser representado com precisão. O envelope do espectro de potência temporal do sinal de fala é representativo do trato vocal e o MFCC (que nada mais é do que os coeficientes que compõem o ceptro de Mel-frequência) representa com precisão este envelope. O seguinte diagrama de blocos é um resumo passo-a-passo de como chegamos ao MFCCs:
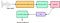
Aqui, o Banco de Filtros refere-se aos filtros de mel (cobertura à escala de mel) e os Coeficientes Cepstral não são nada mais que MFCCs.
TL; DR – As características de MFCC representam fonemas (unidades distintas de som) como a forma do trato vocal (que é responsável pela geração do som) se manifesta neles.
Disclaimer 2 : Todas as imagens são do Google images.