Locality-sensitive hashing
Obiettivo: trovare documenti con similarità Jaccard di almeno t
L’idea generale di LSH è di trovare un algoritmo tale che se inseriamo le firme di 2 documenti, ci dice che quei 2 documenti formano una coppia candidata o no, cioè la loro similarità è maggiore di una soglia t. Ricordate che stiamo prendendo la somiglianza delle firme come proxy della somiglianza Jaccard tra i documenti originali.
Specificamente per la matrice di firma min-hash:
- Hash delle colonne della matrice di firma M usando diverse funzioni hash
- Se 2 documenti si hashano nello stesso bucket per almeno una delle funzioni hash possiamo prendere i 2 documenti come coppia candidata
Ora la questione è come creare diverse funzioni hash. Per questo facciamo la partizione della banda.
Band partition

Ecco l’algoritmo:
- Dividere la matrice della firma in b bande, ogni banda ha r righe
- Per ogni banda, fare l’hash della sua porzione di ogni colonna in una tabella hash con k bucket
- Le coppie di colonne candidate sono quelle che fanno l’hash nello stesso bucket per almeno 1 banda
- Tune b e r per catturare la maggior parte delle coppie simili ma poche coppie non simili
Ci sono alcune considerazioni qui. Idealmente per ogni banda vogliamo prendere k per essere uguale a tutte le possibili combinazioni di valori che una colonna può assumere all’interno di una banda. Questo sarà equivalente alla corrispondenza di identità. Ma in questo modo k sarà un numero enorme che è computazionalmente impossibile. Per esempio: se per una banda abbiamo 5 righe in essa. Ora se gli elementi nella firma sono 32 bit interi allora k in questo caso sarà (2³²)⁵ ~ 1.4615016e+48. Puoi vedere qual è il problema qui. Normalmente k è preso intorno a 1 milione.
L’idea è che se 2 documenti sono simili allora appariranno come coppia di candidati in almeno una delle bande.
Scelta di b & r
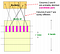
Se prendiamo b grande cioè più numero di funzioni hash, allora riduciamo r poiché b*r è una costante (numero di righe nella matrice di firma). Intuitivamente significa che stiamo aumentando la probabilità di trovare una coppia di candidati. Questo caso è equivalente a prendere un piccolo t (soglia di somiglianza)
Diciamo che la tua matrice di firma ha 100 righe. Consideriamo 2 casi:
b1 = 10 → r = 10
b2 = 20 → r = 5
Nel secondo caso, c’è una maggiore possibilità per 2 documenti di apparire nello stesso bucket almeno una volta poiché hanno più opportunità (20 vs 10) e meno elementi della firma vengono confrontati (5 vs 10).
Un b più alto implica una soglia di similarità più bassa (più alti falsi positivi) e un b più basso implica una soglia di similarità più alta (più alti falsi negativi)
Cerchiamo di capire questo attraverso un esempio.
Setup:
- 100k documenti memorizzati come firma di lunghezza 100
- Matrice di firma: 100*100000
- Confronto a forza bruta delle firme risulterà in 100C2 confronti = 5 miliardi (un bel po’!)
- Prendiamo b = 20 → r = 5
soglia di somiglianza (t) : 80%
Vogliamo che 2 documenti (D1 & D2) con 80% di somiglianza siano hashati nello stesso secchio per almeno una delle 20 bande.
P(D1 & D2 identici in una particolare banda) = (0,8)⁵ = 0,328
P(D1 & D2 non sono simili in tutte le 20 bande) = (1-0,328)^20 = 0,00035
Questo significa che in questo scenario abbiamo ~.035% di possibilità di un falso negativo @ 80% documenti simili.
Anche noi vogliamo che 2 documenti (D3 & D4) con il 30% di somiglianza non siano hashed nello stesso bucket per nessuna delle 20 bande (soglia = 80%).
P(D3 & D4 identici in una particolare banda) = (0.3)⁵ = 0.00243
P(D3 & D4 sono simili in almeno una delle 20 bande) = 1 – (1-0.00243)^20 = 0.0474
Questo significa che in questo scenario abbiamo ~4.74% di possibilità di un falso positivo @ 30% di documenti simili.
Quindi possiamo vedere che abbiamo alcuni falsi positivi e pochi falsi negativi. Queste proporzioni varieranno con la scelta di b e r.
Quello che vogliamo qui è qualcosa come sotto. Se abbiamo 2 documenti che hanno una somiglianza maggiore della soglia, allora la probabilità che condividano lo stesso secchio in almeno una delle bande dovrebbe essere 1, altrimenti 0.

Il caso peggiore sarà se abbiamo b = numero di righe nella matrice della firma come mostrato sotto.

Caso generalizzato per qualsiasi b e r è mostrato sotto.

Scegliere b e r per ottenere la migliore curva S i.e minimo tasso di falsi negativi e falsi positivi

Sommario LSH
- Tune M, b, r per ottenere quasi tutte le coppie di documenti con firme simili, ma elimina la maggior parte delle coppie che non hanno firme simili
- Controlla nella memoria principale che le coppie candidate abbiano davvero firme simili