Disclaimer 1 : Questo articolo è solo un’introduzione alle caratteristiche MFCC ed è destinato a coloro che hanno bisogno di una facile e veloce comprensione delle stesse. La matematica dettagliata e le complessità non sono discusse.
Non avendo mai lavorato nell’area dell’elaborazione del parlato, la parola “MFCC” (molto spesso usata dai colleghi) mi ha lasciato con la comprensione inadeguata che è il nome dato a un particolare tipo di “caratteristica” estratta dai segnali audio (simile ai bordi che costituiscono un tipo di caratteristica estratta dalle immagini).


Mi ci è voluto un bel po’ di letture da più fonti per capire cosa sono le caratteristiche MFCC. Così ho deciso di aiutare i colleghi in difficoltà compilando le informazioni che ho raccolto in un modo facile da capire.
Iniziamo espandendo l’acronimo MFCC – Mel Frequency Cepstral Co-efficients.
Hai mai sentito la parola cepstral prima? Probabilmente no. È spettrale con la specifica invertita! Ma perché? Per una comprensione molto elementare, il cepstrum è l’informazione del tasso di cambiamento nelle bande spettrali. Nell’analisi convenzionale dei segnali temporali, qualsiasi componente periodica (per esempio, gli echi) si presenta come picchi acuti nello spettro di frequenza corrispondente (cioè, lo spettro di Fourier. Questo si ottiene applicando una trasformata di Fourier sul segnale temporale). Questo può essere visto nell’immagine seguente.

Prendendo il log della grandezza di questo spettro di Fourier, e poi ancora prendendo lo spettro di questo log con una trasformazione del coseno (so che sembra complicato, ma abbiate pazienza!), osserviamo un picco ovunque ci sia un elemento periodico nel segnale temporale originale. Poiché applichiamo una trasformazione sullo spettro della frequenza stessa, lo spettro risultante non è né nel dominio della frequenza né nel dominio del tempo e quindi Bogert et al. hanno deciso di chiamarlo dominio del quefrency. E questo spettro del log dello spettro del segnale temporale è stato chiamato cepstrum (ta-da!).
L’immagine seguente è un riassunto dei passi spiegati sopra.

Il cepstrum fu introdotto per la prima volta per caratterizzare gli echi sismici dovuti ai terremoti.
Il pitch è una delle caratteristiche di un segnale vocale e si misura come frequenza del segnale. La scala Mel è una scala che mette in relazione la frequenza percepita di un tono con la frequenza reale misurata. Scala la frequenza in modo da corrispondere più da vicino a ciò che l’orecchio umano può sentire (gli esseri umani sono più bravi a identificare piccoli cambiamenti nel discorso a frequenze più basse). Questa scala è stata derivata da una serie di esperimenti su soggetti umani. Lasciate che vi dia una spiegazione intuitiva di ciò che la scala mel cattura.
La gamma dell’udito umano è da 20Hz a 20kHz. Immaginate una melodia a 300 Hz. Questo suonerebbe qualcosa come il tono standard di un telefono fisso. Ora immagina una melodia a 400 Hz (un tono di chiamata un po’ più alto). Ora confronta la distanza tra questi due, in qualsiasi modo questo possa essere percepito dal tuo cervello. Ora immaginate un segnale a 900 Hz (simile al suono di feedback di un microfono) e un suono a 1kHz. La distanza percepita tra questi due suoni può sembrare maggiore dei primi due anche se la differenza reale è la stessa (100Hz). La scala mel cerca di catturare queste differenze. Una frequenza misurata in Hertz (f) può essere convertita nella scala Mel usando la seguente formula :
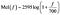
Ogni suono generato dagli esseri umani è determinato dalla forma del loro tratto vocale (compresi lingua, denti, ecc). Se questa forma può essere determinata correttamente, qualsiasi suono prodotto può essere rappresentato accuratamente. L’inviluppo dello spettro di potenza temporale del segnale vocale è rappresentativo del tratto vocale e l’MFCC (che non è altro che i coefficienti che compongono il cepstrum di Mel-frequenza) rappresenta accuratamente questo inviluppo. Il seguente schema a blocchi è un riassunto a tappe di come siamo arrivati agli MFCC:
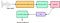
Qui, Filter Bank si riferisce ai filtri mel (che coprono la scala mel) e i Coefficienti Cepstrali non sono altro che gli MFCC.
TL; DR – Le caratteristiche MFCC rappresentano fonemi (unità distinte di suono) poiché la forma del tratto vocale (che è responsabile della generazione del suono) si manifesta in esse.
Disclaimer 2 : Tutte le immagini provengono da Google images.
.