
La vostra organizzazione vuole aggregare e analizzare i dati per conoscere le tendenze, ma in modo da proteggere la privacy? O forse stai già usando strumenti di privacy differenziale, ma vuoi espandere (o condividere) le tue conoscenze? In entrambi i casi, questa serie di blog è per voi.
Perché stiamo facendo questa serie? L’anno scorso, il NIST ha lanciato un Privacy Engineering Collaboration Space per aggregare strumenti, soluzioni e processi open source che supportano l’ingegneria della privacy e la gestione del rischio. Come moderatori dello spazio di collaborazione, abbiamo aiutato il NIST a raccogliere diversi strumenti di privacy sotto l’area tematica della de-identificazione. Il NIST ha anche pubblicato il Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management e una roadmap di accompagnamento che ha riconosciuto una serie di aree di sfida per la privacy, incluso l’argomento della de-identificazione. Ora vorremmo sfruttare lo spazio di collaborazione per aiutare a colmare la lacuna della tabella di marcia sulla de-identificazione. Il nostro obiettivo finale è quello di supportare il NIST nel trasformare questa serie in linee guida più approfondite sulla privacy differenziale.
Ogni post inizierà con le basi concettuali e i casi d’uso pratici, con l’obiettivo di aiutare i professionisti come i proprietari dei processi aziendali o il personale dei programmi sulla privacy a imparare quanto basta per essere pericolosi (scherzo). Dopo aver coperto le basi, esamineremo gli strumenti disponibili e i loro approcci tecnici per gli ingegneri della privacy o i professionisti IT interessati ai dettagli di implementazione. Per mettere tutti al corrente, questo primo post fornirà un background sulla privacy differenziale e descriverà alcuni concetti chiave che useremo nel resto della serie.
La sfida
Come possiamo usare i dati per conoscere una popolazione, senza conoscere individui specifici all’interno della popolazione? Consideriamo queste due domande:
- “Quante persone vivono nel Vermont?”
- “Quante persone di nome Joe Near vivono nel Vermont?”
La prima rivela una proprietà dell’intera popolazione, mentre la seconda rivela informazioni su una persona. Dobbiamo essere in grado di conoscere le tendenze nella popolazione, impedendo allo stesso tempo di imparare qualcosa di nuovo su un particolare individuo. Questo è l’obiettivo di molte analisi statistiche di dati, come le statistiche pubblicate dal Census Bureau degli Stati Uniti, e l’apprendimento automatico più in generale. In ognuna di queste impostazioni, i modelli hanno lo scopo di rivelare tendenze nelle popolazioni, non di riflettere informazioni su ogni singolo individuo.
Ma come possiamo rispondere alla prima domanda “Quante persone vivono nel Vermont?” – a cui ci riferiremo come una query – impedendo allo stesso tempo di rispondere alla seconda domanda “Quante persone di nome Joe Near vivono nel Vermont?” La soluzione più utilizzata è chiamata de-identificazione (o anonimizzazione), che rimuove le informazioni identificative dal set di dati. (Generalmente assumiamo che un set di dati contenga informazioni raccolte da molti individui). Un’altra opzione è quella di permettere solo query aggregate, come una media dei dati. Sfortunatamente, ora capiamo che nessuno dei due approcci fornisce effettivamente una forte protezione della privacy. I set di dati de-identificati sono soggetti ad attacchi di collegamento al database. L’aggregazione protegge la privacy solo se i gruppi che vengono aggregati sono sufficientemente grandi, e anche allora, gli attacchi alla privacy sono ancora possibili.
Privacy differenziale
La privacy differenziale è una definizione matematica di ciò che significa avere privacy. Non è un processo specifico come la de-identificazione, ma una proprietà che un processo può avere. Per esempio, è possibile dimostrare che uno specifico algoritmo “soddisfa” la privacy differenziale.
Informalmente, la privacy differenziale garantisce quanto segue per ogni individuo che contribuisce ai dati per l’analisi: l’output di un’analisi differentemente privata sarà più o meno lo stesso, che si contribuisca o meno con i propri dati. Un’analisi differentemente privata è spesso chiamata meccanismo, e noi la indichiamo con ℳ.
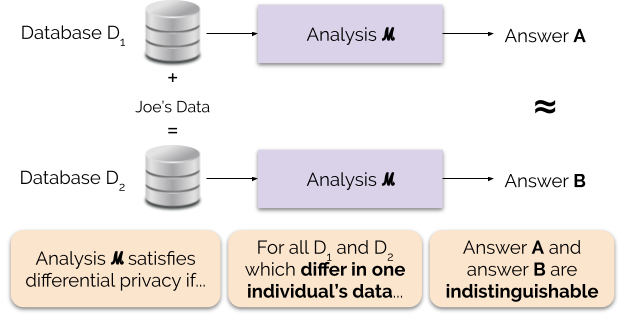
La figura 1 illustra questo principio. La risposta “A” è calcolata senza i dati di Joe, mentre la risposta “B” è calcolata con i dati di Joe. La privacy differenziale dice che le due risposte dovrebbero essere indistinguibili. Questo implica che chiunque veda l’output non sarà in grado di dire se i dati di Joe sono stati usati o meno, o cosa contenevano i dati di Joe.
Controlliamo la forza della garanzia di privacy regolando il parametro di privacy ε, chiamato anche perdita di privacy o privacy budget. Più basso è il valore del parametro ε, più indistinguibili sono i risultati, e quindi più protetti sono i dati di ciascun individuo.
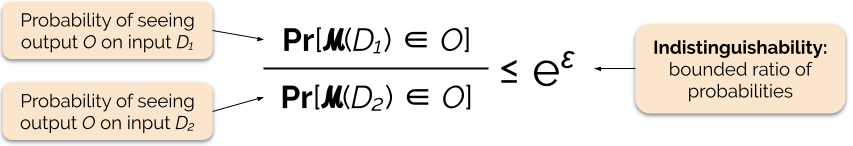
Possiamo spesso rispondere a una domanda con privacy differenziale aggiungendo del rumore casuale alla risposta della domanda. La sfida sta nel determinare dove aggiungere il rumore e quanto aggiungerne. Uno dei meccanismi più comunemente usati per aggiungere rumore è il meccanismo di Laplace.
Le query con maggiore sensibilità richiedono l’aggiunta di più rumore per soddisfare una particolare quantità `epsilon` di privacy differenziale, e questo rumore extra ha il potenziale di rendere i risultati meno utili. Descriveremo la sensibilità e questo compromesso tra privacy e utilità in modo più dettagliato nei prossimi post del blog.
Benefici della privacy differenziale
La privacy differenziale ha diversi importanti vantaggi rispetto alle precedenti tecniche di privacy:
- Prevede che tutte le informazioni siano informazioni identificative, eliminando il difficile (e talvolta impossibile) compito di rendere conto di tutti gli elementi identificativi dei dati.
- È resistente agli attacchi alla privacy basati su informazioni ausiliarie, quindi può prevenire efficacemente gli attacchi di collegamento che sono possibili sui dati de-identificati.
- È composizionale – possiamo determinare la perdita di privacy dell’esecuzione di due analisi differentemente private sugli stessi dati semplicemente sommando le perdite di privacy individuali per le due analisi. La composizionalità significa che possiamo dare garanzie significative sulla privacy anche quando si rilasciano più risultati di analisi dagli stessi dati. Tecniche come la de-identificazione non sono compositive, e rilasci multipli con queste tecniche possono risultare in una perdita catastrofica di privacy.
Questi vantaggi sono le ragioni principali per cui un professionista potrebbe scegliere la privacy differenziale rispetto a qualche altra tecnica di privacy dei dati. Uno svantaggio attuale della privacy differenziale è che è piuttosto nuovo, e strumenti robusti, standard e best-practice non sono facilmente accessibili al di fuori delle comunità di ricerca accademica. Tuttavia, prevediamo che questa limitazione possa essere superata nel prossimo futuro a causa della crescente domanda di soluzioni robuste e facili da usare per la privacy dei dati.
Coming Up Next
Starete sintonizzati: il nostro prossimo post si baserà su questo esplorando i problemi di sicurezza coinvolti nell’implementazione di sistemi per la privacy differenziale, compresa la differenza tra i modelli centrale e locale della privacy differenziale.
Prima di andare – vogliamo che questa serie e le successive linee guida del NIST contribuiscano a rendere la privacy differenziale più accessibile. Voi potete aiutare. Sia che abbiate domande su questi post o che possiate condividere le vostre conoscenze, speriamo che vi impegniate con noi in modo da poter far progredire questa disciplina insieme.
Garfinkel, Simson, John M. Abowd, e Christian Martindale. “Comprensione degli attacchi di ricostruzione di database su dati pubblici”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “Quando il segnale è nel rumore: sfruttare il rumore appiccicoso di diffix.” 28° USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, e Kobbi Nissim. “Rivelare le informazioni preservando la privacy”. Atti del ventiduesimo simposio ACM SIGMOD-SIGACT-SIGART sui principi dei sistemi di database. 2003.
Sweeney, Latanya. “I semplici dati demografici spesso identificano le persone in modo univoco”. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis.” Conferenza sulla teoria della crittografia. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan. “Privacy differenziale: Un’introduzione per un pubblico non tecnico”. Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia, e Aaron Roth. “Le basi algoritmiche della privacy differenziale”. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.