Ciao gente! In questo articolo, descriverò un algoritmo utilizzato nell’elaborazione del linguaggio naturale: Latent Semantic Analysis ( LSA ).
Le principali applicazioni di questo metodo sono di ampia portata in linguistica: Confrontare i documenti in spazi bidimensionali (Document Similarity), trovare argomenti ricorrenti nei documenti (Topic Modeling), trovare relazioni tra termini (Text Synoymity).

Introduzione
Il modello di Analisi Semantica Latente è una teoria su come le rappresentazioni di significato
possano essere apprese dall’incontro con grandi campioni di linguaggio senza indicazioni esplicite su come è strutturato.
Il problema alla mano non è supervisionato, cioè non abbiamo etichette fisse o categorie assegnate al corpus.
Per estrarre e capire i modelli dai documenti, LSA segue intrinsecamente alcuni presupposti:
1) Il significato delle frasi o dei documenti è una somma del significato di tutte le parole che vi si trovano. Complessivamente, il significato di una certa parola è una media di tutti i documenti in cui compare.
2) LSA presuppone che le associazioni semantiche tra le parole siano presenti non esplicitamente, ma solo in modo latente nel grande campione di linguaggio.
Prospettiva matematica
Latent Semantic Analysis (LSA) comprende alcune operazioni matematiche per ottenere una visione su un documento. Questo algoritmo costituisce la base del Topic Modeling. L’idea centrale è di prendere una matrice di ciò che abbiamo – documenti e termini – e decomporla in una matrice documento-argomento separata e una matrice argomento-termine.
Il primo passo è generare la nostra matrice documento-termine usando Tf-IDF Vectorizer. Può anche essere costruita usando un modello Bag-of-Words, ma i risultati sono scarsi e non forniscono alcun significato alla questione.
Dati m documenti e n parole nel nostro vocabolario, possiamo costruire una matrice
m × n A in cui ogni riga rappresenta un documento e ogni colonna rappresenta una parola.
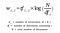
Intuitivamente, un termine ha un grande peso quando ricorre frequentemente nel documento ma raramente nel corpus.
Formiamo una matrice documento-termine, A usando questo metodo di trasformazione (tf-IDF) per vettorizzare il nostro corpus. (In un modo che il nostro ulteriore modello può elaborare o valutare poiché non lavoriamo ancora su stringhe!)
Ma c’è un sottile inconveniente, non possiamo dedurre nulla osservando A, poiché è una matrice rumorosa e sparsa. (A volte troppo grande anche per essere calcolata per ulteriori processi).
Siccome il Topic Modeling è intrinsecamente un algoritmo non supervisionato, dobbiamo specificare gli argomenti latenti prima. E’ analogo al K-Means Clustering in modo da specificare il numero di cluster in anticipo.
In questo caso, eseguiamo un Low-Rank Approximation usando una tecnica di riduzione della dimensionalità mediante una Decomposizione tronca del valore singolare (SVD).
La decomposizione del valore singolare è una tecnica in algebra lineare che fattorizza qualsiasi matrice M nel prodotto di 3 matrici separate: M=U*S*V, dove S è una matrice diagonale dei valori singolari di M.
La SVD troncata riduce la dimensionalità selezionando solo i t valori singolari più grandi, e mantenendo solo le prime t colonne di U e V. In questo caso, t è un iperparametro che possiamo selezionare e regolare per riflettere il numero di argomenti che vogliamo trovare.
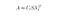
Nota: Truncated SVD fa la riduzione della dimensionalità e non la SVD!

Con questi vettori di documenti e vettori di termini, possiamo ora facilmente applicare misure come la similarità del coseno per valutare:
- la somiglianza di documenti diversi
- la somiglianza di parole diverse
- la somiglianza di termini (o “query”) e documenti (che diventa utile nell’information retrieval, quando vogliamo recuperare i passaggi più pertinenti alla nostra query di ricerca).
Riservazioni conclusive
Questo algoritmo è usato principalmente in vari compiti basati su NLP ed è la base per metodi più robusti come LSA probabilistico e Latent Dirichlet Allocation (LDA).
Kushal Vala, Junior Data Scientist presso Datametica Solutions Pvt Ltd