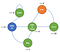
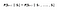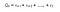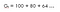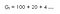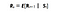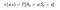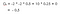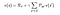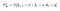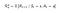Egy tipikus Reinforcement Learning (RL) problémában van egy tanuló és egy döntéshozó, az úgynevezett ágens, és a környezetet, amellyel kölcsönhatásba lép, környezetnek nevezzük. A környezet cserébe jutalmakat és új állapotot biztosít az ágens cselekedetei alapján. A megerősítéses tanulás során tehát nem azt tanítjuk meg az ágensnek, hogy hogyan kell tennie valamit, hanem a cselekedetei alapján pozitív vagy negatív jutalmakat adunk neki. A blog alapkérdése tehát az, hogy hogyan fogalmazzuk meg matematikailag az RL bármely problémáját. Itt jön a képbe a Markov-döntési folyamat(MDP).
Típusos megerősítéses tanulási ciklus
Mielőtt válaszolnánk a gyökérkérdésünkre, azaz. Hogyan fogalmazzuk meg az RL problémákat matematikailag (MDP segítségével), ki kell alakítanunk intuíciónkat a :
Az ágens-környezet kapcsolat
Markov tulajdonság
Markov-folyamat és Markov-láncok
Markov jutalmazási folyamat (MRP)
Bellman egyenlet
Markov jutalmazási folyamat
Kávézz és ne hagyd abba, amíg nem vagy büszke!🧐
Az ágens-környezet kapcsolat
Először nézzünk néhány formális definíciót :
Agent : Szoftverprogramok, amelyek intelligens döntéseket hoznak, és ők a tanulók az RL-ben. Ezek az ágensek cselekvésekkel lépnek kölcsönhatásba a környezettel, és a cselekvéseik alapján jutalmakat kapnak.
Környezet :A megoldandó probléma bemutatása.Nos, lehet egy valós környezetünk vagy egy szimulált környezet, amellyel az ágensünk kölcsönhatásba lép.
Egy olyan környezet demonstrálása, amellyel az ágensek kölcsönhatásba lépnek.
State : Ez az ágensek helyzete egy adott időlépésnél a környezetben.tehát,amikor egy ágens végrehajt egy cselekvést,a környezet jutalmat ad az ágensnek és egy új állapotot,ahová az ágens a cselekvés végrehajtásával jutott.
Minden,amit az ágens nem tud önkényesen megváltoztatni,a környezet részének tekintjük. Egyszerűbben fogalmazva, akció lehet bármilyen döntés, amit az ágensnek meg akarunk tanulni, állapot pedig bármi, ami hasznos lehet az akciók kiválasztásában. Nem feltételezzük, hogy a környezetből minden ismeretlen az ágens számára, például a jutalom kiszámítását a környezet részének tekintjük, még akkor is, ha az ágens egy kicsit tudja, hogy a jutalmát hogyan számítják ki a cselekvései és az állapotok függvényében, amelyekben azokat végrehajtja. Ez azért van így, mert a jutalmakat az ágens nem változtathatja meg önkényesen. Néha előfordulhat, hogy az ágens teljesen tisztában van a környezetével, de mégis nehéznek találja a jutalom maximalizálását, mintha tudnánk, hogyan kell játszani a Rubik-kockával, de mégsem tudjuk megoldani. Tehát nyugodtan mondhatjuk, hogy az ágens-környezet kapcsolat az ágens irányításának határát jelenti, nem pedig a tudását.
A Markov-tulajdonság
Átmenet : Az egyik állapotból a másikba való átmenetet átmenetnek nevezzük.
Átmenet valószínűsége: Annak a valószínűségét, hogy az ágens egyik állapotból a másikba lép, átmenet valószínűségének nevezzük.
A Markov-tulajdonság szerint :
“A jövő független a múlttól, ha a jelen adott”
Matematikailag ezt az állítást így fejezhetjük ki: :
Markov-tulajdonság
S az ágens jelenlegi állapotát, s pedig a következő állapotot jelöli. Ez az egyenlet azt jelenti, hogy az S állapotból S-be való átmenet teljesen független a múlttól. Tehát az egyenlet RHS-je ugyanazt jelenti, mint az LHS, ha a rendszer Markov-tulajdonsággal rendelkezik. Intuitíve azt jelenti, hogy az aktuális állapotunk már magába foglalja a múltbeli állapotok információit.
Átmeneti valószínűség :
Mivel már ismerjük az átmeneti valószínűséget, az alábbiak szerint definiálhatjuk az állapotátmenet valószínűségét :
A Markov-állapotra S-ből S-be azaz. bármely más utódállapotra , az állapotátmenet valószínűsége a következő:
Államátmenet valószínűsége
Az állapotátmenet valószínűségét egy állapotátmenet valószínűségi mátrixban fogalmazhatjuk meg: :
Állapátmeneti valószínűségi mátrix
A mátrix minden sora az eredeti vagy kiinduló állapotunkból bármelyik utódállapotba való átlépés valószínűségét jelenti.Minden sor összege egyenlő 1.
Markov-folyamat vagy Markov-lánc
A Markov-folyamat a memória nélküli véletlen folyamat, azaz S,S,….S véletlen állapotok Markov-tulajdonsággal rendelkező sorozata.Tehát alapvetően állapotok Markov-tulajdonsággal rendelkező sorozata.Meghatározható egy állapothalmaz(S) és egy átmeneti valószínűségi mátrix (P) segítségével.A környezet dinamikája teljes mértékben definiálható az állapotok(S) és az átmeneti valószínűségi mátrix(P) segítségével.
De mit jelent a véletlen folyamat ?
A kérdés megválaszolásához nézzünk egy példát:
Markov-lánc
A fa élei az átmeneti valószínűséget jelölik. Ebből a láncból vegyünk néhány mintát. Most tegyük fel, hogy aludtunk, és a valószínűségeloszlás szerint 0,6 esély van arra, hogy futni fogunk, és 0,2 esély van arra, hogy többet alszunk, és ismét 0,2 esély van arra, hogy fagylaltot eszünk. Hasonlóképpen gondolhatunk más szekvenciákra is, amelyekből mintát vehetünk ebből a láncból.
Egy pár minta a láncból :
Sleep – Run – Ice-cream – Sleep
Sleep – Ice-cream – Ice-cream – Run
A fenti két szekvenciában azt látjuk, hogy minden alkalommal, amikor a láncot lefuttatjuk, véletlenszerűen kapjuk az állapotok(S) (azaz Sleep,Ice-cream,Sleep ) halmazát.Remélem, most már világos, hogy miért nevezik a Markov-folyamatot véletlenszerű sorozatok halmazának.
Mielőtt rátérnénk a Markov jutalmazási folyamatra, nézzünk meg néhány fontos fogalmat, amelyek segítenek az MRP-k megértésében.
Jutalom és visszatérés
A jutalom az a számérték, amelyet az ágens kap, ha a környezet valamely állapot(ok)ban végrehajt valamilyen cselekvést. A számérték lehet pozitív vagy negatív az ágens cselekedetei alapján.
A megerősítéses tanulásban a kumulatív jutalom (az összes jutalom, amit az ágens a környezettől kap) maximalizálásával törődünk, nem pedig azzal a jutalommal, amit az ágens az aktuális állapotból (más néven azonnali jutalom) kap. Ezt a teljes jutalomösszeget, amelyet az ágens a környezettől kap, hozamnak nevezzük.
A Returns-t a következőképpen definiálhatjuk :
Returns (Összes jutalom a környezettől)
r az a jutalom, amelyet az ágens a t időlépésben kap, miközben végrehajt egy cselekvést(a), hogy egyik állapotból a másikba lépjen. Hasonlóképpen, r az a jutalom, amelyet az ágens a t időlépésben egy olyan cselekvés végrehajtásakor kap, amellyel egy másik állapotba lép. És r az a jutalom, amelyet az ágens az utolsó időlépésben egy másik állapotba való átlépésre irányuló cselekvés végrehajtásakor kap.
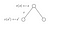
Epizodikus és folyamatos feladatok
Epizodikus feladatok: Ezek azok a feladatok, amelyeknek van egy végállapotuk (végállapot). mondhatjuk, hogy véges állapotokkal rendelkeznek. Például a versenyjátékokban elindítjuk a játékot (verseny indul), és addig játszunk, amíg a játék véget nem ér (verseny véget ér!). Ezt epizódnak nevezzük. Ha újraindítjuk a játékot, az egy kezdeti állapotból indul, ezért minden epizód független.
Folyamatos feladatok : Ezek azok a feladatok, amelyeknek nincs vége, azaz nincs végállapotuk. az ilyen típusú feladatoknak soha nem lesz vége. például: Megtanulni, hogyan kell kódolni!
Most, könnyű kiszámítani az epizodikus feladatok hozamát, mivel ezek egyszer véget érnek, de mi a helyzet a folyamatos feladatokkal, mivel ez örökké fog tartani. A megtérülések összege a végtelen! Hogyan határozzuk meg tehát a folyamatos feladatok hozamát?
Itt van szükségünk a Kedvezménytényezőre (ɤ).
Kedvezménytényező (ɤ): Meghatározza, hogy mekkora jelentőséget kell tulajdonítani az azonnali jutalomnak és a jövőbeli jutalmaknak. Ez alapvetően abban segít, hogy a folyamatos feladatokban elkerüljük a végtelent jutalomként. Értéke 0 és 1 között van. 0 érték azt jelenti, hogy nagyobb jelentőséget tulajdonítunk az azonnali jutalomnak, 1 érték pedig azt, hogy nagyobb jelentőséget tulajdonítunk a jövőbeli jutalmaknak. A gyakorlatban egy 0 értékű diszkontfaktor soha nem fog tanulni, mivel csak az azonnali jutalmat veszi figyelembe, egy 1 értékű diszkontfaktor pedig a jövőbeni jutalmakat veszi figyelembe, ami a végtelenhez vezethet. Ezért a diszkontfaktor optimális értéke 0,2 és 0,8 között van.
Így a következőképpen határozhatjuk meg a hozamokat a diszkontfaktor segítségével :(Mondjuk, hogy ez az 1. egyenlet ,mivel a későbbiekben ezt az egyenletet fogjuk használni a Bellman-egyenlet levezetéséhez)
Returns using discount factor
Egy példán keresztül értsük meg,Tegyük fel, hogy olyan helyen élsz, ahol vízhiánnyal kell szembenézned, így ha valaki odajön hozzád és azt mondja, hogy ad neked 100 liter vizet!(tegyük fel kérem!) a következő 15 órában valamilyen paraméter (ɤ) függvényében.Nézzünk két lehetőséget : (Mondjuk, hogy ez az 1. egyenlet ,mivel ezt az egyenletet fogjuk használni a későbbiekben a Bellman-egyenlet levezetéséhez)
Egyik (ɤ) 0 diszkontfaktorral.8 :
Diszkontfaktor (0.8)
Ez azt jelenti, hogy érdemes várni a 15. óráig, mert a csökkenés nem túl jelentős , így még mindig érdemes a végéig menni.ez azt jelenti, hogy a jövőbeni jutalmak is érdekelnek minket.Tehát, ha a diszkontfaktor közel 1, akkor igyekszünk a végéig menni, mivel a jutalom jelentős jelentőséggel bír.
Második, diszkontfaktorral (ɤ) 0,2 :
Diszkontfaktor (0.2)
Ez azt jelenti, hogy jobban érdekel minket a korai jutalom, mivel a jutalom óránként jelentősen csökken.Így nem biztos, hogy szeretnénk megvárni a végét (a 15. órát), mert akkor már nem ér semmit.
Ha tehát a diszkontfaktor közel nulla, akkor az azonnali jutalom fontosabb, mint a jövőbeli.
A diszkontfaktor melyik értékét használjuk?
Az attól függ, hogy milyen feladatra szeretnénk kiképezni az ügynököt. Tegyük fel, hogy egy sakkjátszmában a cél az ellenfél királyának legyőzése. Ha fontosnak tartjuk az azonnali jutalmakat, például a gyalogos legyőzéséért járó jutalmat bármelyik ellenfél játékosának, akkor az ágens meg fogja tanulni, hogy ezeket a részcélokat teljesítse, függetlenül attól, hogy az ő játékosait is legyőzik. Tehát ebben a feladatban a jövőbeli jutalmak fontosabbak. Néhány esetben előnyben részesíthetjük az azonnali jutalmak használatát, mint például a korábban látott vízpélda.
Markov jutalomfolyamat
Mostanáig láttuk, hogy a Markov-lánc hogyan határozza meg a környezet dinamikáját az állapotok halmazával (S) és az átmenet valószínűségi mátrixával (P).De tudjuk, hogy a megerősítő tanulás a jutalom maximalizálásának céljáról szól.Tehát adjunk hozzá jutalmat a Markov-láncunkhoz.Ez adja a Markov jutalomfolyamatot.
Markov jutalmazási folyamat : Ahogy a neve is mutatja, az MDP-k a Markov-láncok értékítéletekkel. alapvetően minden állapotból, amelyben az ágensünk van, kapunk egy értéket.
Matematikailag a Markov jutalmazási folyamatot a következőképpen definiáljuk :
Markov jutalmazási folyamat
Az egyenlet azt jelenti, hogy mennyi jutalmat (Rs) kapunk egy adott S állapotból. Ez megadja nekünk az adott állapot közvetlen jutalmát, amelyben az ágensünk van. Mint a következő történetben látni fogjuk, hogyan maximalizáljuk ezeket a jutalmakat minden egyes állapotból, amelyben az ágensünk van. Egyszerűbben fogalmazva, maximalizáljuk a kumulatív jutalmat, amit az egyes állapotokból kapunk.
Az MRP-t a következőképpen definiáljuk: (S,P,R,ɤ) ,ahol :
S az állapotok halmaza,
P az átmeneti valószínűségi mátrix,
R a jutalomfüggvény , amit korábban láttunk,
ɤ a diszkontfaktor
Markov-döntési folyamat
Most fejlesszük a Bellman-egyenlet és a Markov-döntési folyamat intuícióját.
Politikai függvény és értékfüggvény
Az értékfüggvény határozza meg, hogy mennyire jó az ágensnek egy adott állapotban lenni. Természetesen annak meghatározásához, hogy mennyire jó egy adott állapotban lenni, függnie kell bizonyos cselekvésektől, amelyeket meg fog tenni. Itt jön a képbe a politika. A politika meghatározza, hogy egy adott s állapotban milyen cselekvéseket hajtson végre.
A politika egy egyszerű függvény, amely minden egyes állapotra (s ∈ S) egy valószínűségi eloszlást határoz meg a cselekvések (a∈ A) felett. Ha egy ágens t időpontban egy π politikát követ, akkor π(a|s) annak a valószínűsége, hogy az ágens adott időlépésben (t) az (a ) akciót végrehajtja.A megerősítéses tanulásban az ágens tapasztalata határozza meg a politika változását. Matematikailag a politika a következőképpen definiálható :
Policy Function
Most, hogyan találjuk meg egy állapot értékét.Az s állapot értéke, amikor az ágens egy π politikát követ, amit vπ(s) jelöl, az s állapotból kiindulva és a π politikát követve a következő állapotokban várható hozam,amíg el nem érjük a végállapotot.Ezt a következőképpen fogalmazhatjuk meg :(Ezt a függvényt állapot-érték függvénynek is nevezik)
értékfüggvény
Ez az egyenlet megadja az s állapotból kiinduló és az utána következő állapotokba tartó várható hozamot a π politikával. Egy dolgot kell megjegyezni: a kapott hozam sztochasztikus, míg az állapot értéke nem sztochasztikus. Ez az s kezdőállapotból és az azt követő bármely más állapotból származó hozamok várakozása. Azt is megjegyezzük, hogy a végállapot értéke (ha van ilyen) nulla. Nézzünk egy példát :
Példa
Tegyük fel, hogy a kezdőállapotunk a 2. osztály, és a 3. osztályba lépünk, majd Pass majd Sleep. röviden: 2. osztály > 3. osztály > Pass > Sleep.
A várható hozamunk 0,5 diszkontfaktorral:
A 2. osztály értékének kiszámítása
Megjegyzés:Ez -2 + (-2 * 0.5) + 10 * 0,25 + 0 helyett -2 * -2 * 0,5 + 10 * 0,25 + 0.Akkor a 2. osztály értéke -0,5 .
Bellman-egyenlet az értékfüggvényhez
A Bellman-egyenlet segít megtalálni az optimális politikákat és értékfüggvényt.Tudjuk, hogy a politikánk a tapasztalattal változik, így a különböző politikáknak megfelelően különböző értékfüggvényeink lesznek.Az optimális értékfüggvény az, amely az összes többi értékfüggvényhez képest maximális értéket ad.
A Bellman-egyenlet szerint az értékfüggvény két részre bontható:
közvetlen jutalom, R
az utódállapotok diszkontált értéke,
Matematikailag a Bellman-egyenletet így definiálhatjuk: :
Bellman-egyenlet az értékfüggvényre
Egy példa segítségével értsük meg, mit mond ez az egyenlet :
Tegyük fel, hogy van egy robot valamilyen állapotban (s), majd ebből az állapotból egy másik állapotba (s’) lép. Most az a kérdés, hogy mennyire volt jó a robotnak abban az állapot(ok)ban lenni. A Bellman-egyenletet használva megállapíthatjuk, hogy ez a jutalom várakozása, amit az állapot(s) elhagyásakor kapott, plusz annak az állapotnak (s’) az értéke, ahová átment.
Nézzünk egy másik példát :
Háttérdiagram
Az s állapot értékét szeretnénk megtudni.Az s állapot(ok) értéke az a jutalom, amit az adott állapot elhagyásakor kaptunk, plusz a leszálló állapot diszkontált értéke szorozva annak az átmenetnek a valószínűségével, hogy abba az állapotba lépünk.
értékszámítás
A fenti egyenletet mátrix formájában a következőképpen fejezhetjük ki :
Bellman lineáris egyenlet
Hol v az az állapot értéke, amelyben voltunk, ami egyenlő az azonnali jutalom plusz a következő állapot diszkontált értéke szorozva az adott állapotba lépés valószínűségével.
A számítás futási időbonyolultsága O(n³). Ezért ez egyértelműen nem praktikus megoldás nagyobb MRP-k megoldására (ugyanez vonatkozik az MDP-kre is). a későbbi Blogokban olyan hatékonyabb módszereket fogunk megvizsgálni, mint a dinamikus programozás (érték-iteráció és policy-iteráció), a Monte-Claro módszerek és a TD-tanulás.
A következő történetben sokkal részletesebben fogunk beszélni a Bellman-egyenletről.
Mi az a Markov-döntési folyamat?
Markov-döntési folyamat : Ez egy Markov jutalmazási folyamat döntésekkel.Minden ugyanolyan, mint az MRP, de most már van tényleges ügynökségünk, amely döntéseket hoz vagy akciókat hajt végre.
Ez a (S, A, P, P, R, 𝛾) halmaz, ahol:
S az állapotok halmaza,
A az ágens által választható cselekvések halmaza,
P az átmenet valószínűségi mátrixa,
R az ágens cselekvései által felhalmozott jutalom,
𝛾 a diszkontfaktor.
P és R kismértékben változik a cselekvések függvényében az alábbiak szerint :
Átmeneti valószínűségi mátrix
Átmeneti valószínűségi mátrix w.r.t action
Reward Function
Reward Function w.r.t akció
Most a jutalomfüggvényünk a cselekvéstől függ.
Az eddigiekben arról beszéltünk, hogy jutalmat (r) kapunk, ha ágensünk egy π politikát követve végigmegy egy állapothalmazon (s).Valójában a Markov-döntési folyamatban (MDP) a politika a döntések meghozatalának mechanizmusa.Tehát most már van egy mechanizmusunk, amely egy cselekvés mellett dönt.
A politika egy MDP-ben az aktuális állapottól függ.Nem függ az előzményektől.Ez a Markov-tulajdonság.Tehát az aktuális állapot, amelyben vagyunk, jellemzi az előzményeket.
Már láttuk, hogy mennyire jó az ágensnek egy adott állapotban lenni(Állapot-érték függvény).most nézzük meg, hogy mennyire jó az s állapotból π politikát követve egy adott akciót végrehajtani (Akció-érték függvény).
Állapot-akció-érték függvény vagy Q-függvény
Ez a függvény megadja, hogy mennyire jó az ágensnek π politikával egy (s) állapotban (a) akciót végrehajtani.
Matematikailag így definiálhatjuk az Állapot-akció értékfüggvényt :
Állapot-akció értékfüggvény
Gyakorlatilag azt mondja meg, hogy egy bizonyos akció(a) végrehajtása mennyire értékes egy π politikával rendelkező állapotban(s).
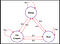
Nézzünk egy példát a Markov-döntési folyamatra :
Példa MDP
Most láthatjuk, hogy nincs több valószínűség.Valójában most az ágensünknek választási lehetőségei vannak, mint például ébredés után ,választhatjuk, hogy Netflixet nézünk vagy kódolunk és hibakeresést végzünk.Természetesen az ágens cselekedetei valamilyen π politika alapján vannak meghatározva és ennek megfelelően kapja a jutalmat.