Locality-sensitive Hashing
Cél: Olyan dokumentumok keresése, amelyek Jaccard hasonlósága legalább t
Az LSH általános lényege, hogy olyan algoritmust találjunk, amely ha 2 dokumentum aláírását adjuk meg, akkor megmondja, hogy a 2 dokumentum egy jelölt párt alkot-e vagy sem, azaz hasonlóságuk nagyobb, mint egy t küszöbérték. Ne feledjük, hogy az aláírások hasonlóságát az eredeti dokumentumok közötti Jaccard-hasonlóság helyettesítőjének tekintjük.
Kifejezetten a min-hash aláírásmátrix esetében:
- Az M aláírásmátrix oszlopait több hash függvény segítségével hash-eljük
- Ha 2 dokumentum legalább az egyik hash függvény esetében ugyanabba a vödörbe hash-ozik, akkor a 2 dokumentumot jelölt párnak tekinthetjük
A kérdés most az, hogyan hozzunk létre különböző hash függvényeket. Ehhez sávos particionálást végzünk.
Sávos felosztás

Itt az algoritmus:
- Az aláírásmátrixot b sávra osztjuk, minden sávnak r sora van
- Minden sávhoz, hash-eljük az egyes oszlopok részét egy k vödörből álló hash-táblába
- A jelölt oszloppárok azok, amelyek legalább 1 sávban ugyanabba a vödörbe hash-elnek
- Hangoljuk a b és r értékeket úgy, hogy a legtöbb hasonló, de kevés nem hasonló pár legyen
Ezzel kapcsolatban van néhány szempont. Ideális esetben minden sáv esetében azt akarjuk, hogy k egyenlő legyen az összes lehetséges értékkombinációval, amelyet egy oszlop egy sávon belül felvehet. Ez az azonossági megfeleltetéssel lesz egyenértékű. De így k egy hatalmas szám lesz, ami számítási szempontból kivitelezhetetlen. Például: Ha egy sávban 5 sor van. Ha az aláírás elemei 32 bites egész számok, akkor k ebben az esetben (2³²)⁵ ~ 1.4615016e+48 lesz. Itt láthatjuk, hogy mi a probléma. Általában k-t 1 millió körül szokták venni.
Az elképzelés az, hogy ha 2 dokumentum hasonló, akkor legalább az egyik sávban jelölt párként fognak megjelenni.
A b választása & r
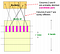
Ha b-t nagynak vesszük, azaz több hash függvényt, akkor csökkentjük az r-t, mivel b*r egy konstans (az aláírásmátrix sorainak száma). Intuitíve ez azt jelenti, hogy növeljük a jelöltpár megtalálásának valószínűségét. Ez az eset egyenértékű egy kis t (hasonlósági küszöb)
Tegyük fel, hogy az aláírásmátrixunk 100 soros. Tekintsünk 2 esetet:
b1 = 10 → r = 10
b2 = 20 → r = 5
A 2. esetben nagyobb az esélye annak, hogy 2 dokumentum legalább egyszer megjelenik ugyanabban a vödörben, mivel több lehetőségük van (20 vs. 10) és az aláírás kevesebb elemét hasonlítják össze (5 vs. 10).
A magasabb b alacsonyabb hasonlósági küszöbértéket jelent (magasabb hamis pozitívumok), az alacsonyabb b pedig magasabb hasonlósági küszöbértéket (magasabb hamis negatívumok)
Próbáljuk ezt egy példán keresztül megérteni.
Felállítás:
- 100k dokumentumot tárolunk 100 hosszúságú aláírásként
- Aláírásmátrix:
- Az aláírások brutális összehasonlítása 100C2 összehasonlítást fog eredményezni = 5 milliárd (elég sok!)
- Tegyük b = 20 → r = 5
hasonlósági küszöb (t) : 80%
Azt akarjuk, hogy 2 dokumentum (D1 & D2) 80%-os hasonlósággal ugyanabba a vödörbe legyen hashelve a 20 sáv közül legalább az egyikben.
P(D1 & D2 azonos egy adott sávban) = (0,8)⁵ = 0,328
P(D1 & D2 nem hasonló mind a 20 sávban) = (1-0,328)^20 = 0,00035
Ez azt jelenti, hogy ebben a forgatókönyvben ~.035% az esélye a hamis negatívnak 80%-ban hasonló dokumentumok esetén.
Ezért azt akarjuk, hogy 2 dokumentum (D3 & D4) 30%-os hasonlósággal ne kerüljön hashelésre ugyanabban a vödörben a 20 sáv bármelyikében (küszöbérték = 80%).
P(D3 & D4 azonos egy adott sávban) = (0,3)⁵ = 0.00243
P(D3 & D4 hasonló a 20 sáv legalább egyikében) = 1 – (1-0,00243)^20 = 0,0474
Ez azt jelenti, hogy ebben a forgatókönyvben ~4,74% esélyünk van a hamis pozitív eredményre 30% hasonló dokumentum esetén.
Azt látjuk tehát, hogy van néhány hamis pozitív és kevés hamis negatív eredmény. Ezek az arányok a b és az r értékek megválasztásától függően változnak.
Az alábbiakban leírtakhoz hasonlót szeretnénk. Ha van 2 dokumentumunk, amelyek hasonlósága nagyobb, mint a küszöbérték, akkor annak valószínűsége, hogy legalább az egyik sávban ugyanazt a vödröt használják, 1, egyébként 0.

A legrosszabb eset az lesz, ha b = az aláírásmátrix sorainak száma az alábbiak szerint.

Az általános eset bármely b és r esetén az alábbiakban látható.

Válasszuk ki b-t és r-t úgy, hogy a legjobb S-görbét i.e minimális hamis negatív és hamis pozitív arány

LSH összegzés
- Az M, b beállítása, r úgy, hogy majdnem az összes hasonló aláírású dokumentumpárt megkapjuk, de a legtöbb olyan párt, amelynek nincs hasonló aláírása, kizárjuk
- A főmemóriában ellenőrizzük, hogy a jelölt párok valóban hasonló aláírással rendelkeznek-e
.