
Does your organization want to aggregate and analyze data to learn trends, but in a way that protect privacy? Vagy talán már használ különböző adatvédelmi eszközöket, de szeretné bővíteni (vagy megosztani) a tudását? Mindkét esetben ez a blogsorozat Önnek szól.
Miért csináljuk ezt a sorozatot? Tavaly a NIST elindította a Privacy Engineering Collaboration Space-t, hogy összegyűjtse az adatvédelmi tervezést és kockázatkezelést támogató nyílt forráskódú eszközöket, megoldásokat és folyamatokat. A Collaboration Space moderátoraiként segítettünk a NIST-nek összegyűjteni a különböző adatvédelmi eszközöket a de-identifikáció tématerülete alá. A NIST közzétette az adatvédelmi keretrendszert is: A Tool for Improving Privacy through Enterprise Risk Management (Eszköz az adatvédelem javítására a vállalati kockázatkezelésen keresztül) című dokumentumot és a hozzá tartozó ütemtervet, amely felismerte az adatvédelem számos kihívást jelentő területét, köztük a de-identifikáció témakörét. Most szeretnénk kihasználni a Collaboration Space-t, hogy segítsünk megszüntetni az ütemtervben a de-identifikációval kapcsolatos hiányosságokat. A végcélunk az, hogy támogassuk a NIST-et abban, hogy ezt a sorozatot a differenciált adatvédelemmel kapcsolatos mélyebb iránymutatássá alakítsa át.
Minden bejegyzés a fogalmi alapokkal és gyakorlati felhasználási esetekkel kezdődik, és célja, hogy segítse az olyan szakembereket, mint az üzleti folyamatok tulajdonosai vagy az adatvédelmi programok munkatársai, hogy éppen eleget tanuljanak ahhoz, hogy veszélyesek legyenek (csak vicceltem). Az alapok tárgyalása után a rendelkezésre álló eszközöket és azok technikai megközelítéseit tekintjük át az adatvédelmi mérnökök vagy a megvalósítás részletei iránt érdeklődő informatikai szakemberek számára. Annak érdekében, hogy mindenki felkészüljön, ez az első bejegyzés a differenciált adatvédelemmel kapcsolatos háttérismereteket nyújtja, és ismertet néhány kulcsfogalmat, amelyeket a sorozat további részében használni fogunk.
A kihívás
Hogyan használhatjuk az adatokat egy populáció megismerésére anélkül, hogy a populáción belül konkrét egyénekről tanulnánk? Gondoljunk erre a két kérdésre:
- “Hány ember él Vermontban?”
- “Hány Joe Near nevű ember él Vermontban?”
Az első a teljes populáció egy tulajdonságát tárja fel, míg a második egy személyre vonatkozó információt tár fel. Képesnek kell lennünk arra, hogy megismerjük a populáció tendenciáit, miközben megakadályozzuk, hogy egy adott egyénről bármi újat megtudjunk. Ez a célja számos statisztikai adatelemzésnek, például az amerikai népszámlálási hivatal által közzétett statisztikáknak, és tágabb értelemben a gépi tanulásnak. Mindegyik esetben a modellek célja, hogy a populációban megfigyelhető tendenciákat tárják fel, nem pedig az egyes egyénekre vonatkozó információkat tükrözik.
De hogyan válaszolhatunk az első kérdésre: “Hány ember él Vermontban?”. – amit lekérdezésnek fogunk nevezni – miközben megakadályozzuk, hogy a második kérdésre “Hány Joe Near nevű ember él Vermontban?” választ kapjunk. A legszélesebb körben használt megoldás az úgynevezett azonosítástalanítás (vagy anonimizálás), amely eltávolítja az azonosító információkat az adatkészletből. (Általában feltételezzük, hogy egy adatkészlet sok egyéntől gyűjtött információt tartalmaz.) Egy másik lehetőség az, hogy csak aggregált lekérdezéseket engedélyezünk, például az adatok átlagát. Sajnos ma már tudjuk, hogy egyik megközelítés sem nyújt erős adatvédelmet. A nem azonosított adatkészletek ki vannak téve az adatbázis-összekapcsolási támadásoknak. Az összesítés csak akkor védi az adatvédelmet, ha az összesített csoportok elég nagyok, és még akkor is lehetségesek az adatvédelmet érintő támadások.
Differenciális adatvédelem
A differenciális adatvédelem egy matematikai definíciója annak, hogy mit jelent az adatvédelem. Ez nem egy konkrét folyamat, mint az azonosítástalanítás, hanem egy olyan tulajdonság, amellyel egy folyamat rendelkezhet. Például bebizonyítható, hogy egy adott algoritmus “kielégíti” a differenciális adatvédelem követelményeit.
Informálisan a differenciális adatvédelem a következőket garantálja minden egyes egyén számára, aki adatokat szolgáltat az elemzéshez: a differenciálisan privát elemzés kimenete nagyjából ugyanaz lesz, függetlenül attól, hogy Ön hozzájárul-e az adataihoz vagy sem. A differenciálisan privát elemzést gyakran mechanizmusnak nevezik, és ℳ-nak jelöljük.
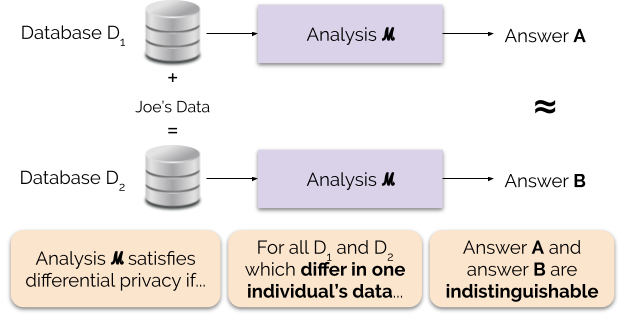
Az 1. ábra szemlélteti ezt az elvet. Az “A” válasz Joe adatai nélkül, míg a “B” válasz Joe adataival kerül kiszámításra. A differenciális adatvédelem azt mondja ki, hogy a két válasznak megkülönböztethetetlennek kell lennie. Ez azt jelenti, hogy bárki is látja a kimenetet, nem tudja megmondani, hogy Joe adatait használták-e, vagy hogy mit tartalmaznak Joe adatai.
Az adatvédelmi garancia erősségét az ε adatvédelmi paraméter, más néven adatvédelmi veszteség vagy adatvédelmi költségvetés beállításával szabályozzuk. Minél kisebb az ε paraméter értéke, annál megkülönböztethetetlenebbek az eredmények, és ezért annál nagyobb védelmet élveznek az egyes személyek adatai.
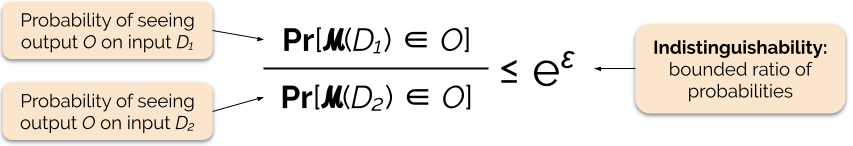
Egy lekérdezésre gyakran úgy tudunk differenciális adatvédelemmel válaszolni, hogy a lekérdezés válaszához némi véletlen zajt adunk. A kihívás annak meghatározásában rejlik, hogy hol és mennyit adjunk hozzá a zajhoz. A zaj hozzáadásának egyik leggyakrabban használt mechanizmusa a Laplace-mechanizmus .
A nagyobb érzékenységű lekérdezések több zaj hozzáadását igénylik a differenciális adatvédelem egy bizonyos `epsilon` mennyiségének kielégítése érdekében, és ez az extra zaj potenciálisan kevésbé használhatóvá teheti az eredményeket. Az érzékenységet és ezt az adatvédelem és a hasznosság közötti kompromisszumot a jövőbeli blogbejegyzésekben részletesebben fogjuk ismertetni.
A differenciális adatvédelem előnyei
A differenciális adatvédelemnek számos fontos előnye van a korábbi adatvédelmi technikákkal szemben:
- Az összes információt azonosító információnak tekinti, így kiküszöböli az adatok összes azonosító elemének számbavétele jelentette kihívást (és néha lehetetlen feladatot).
- Ez ellenáll a segédinformációkon alapuló adatvédelmi támadásoknak, így hatékonyan megakadályozhatja az azonosítatlan adatokon lehetséges összekapcsolási támadásokat.
- Ez kompozíciós – meghatározhatjuk a két különbözően privát elemzés ugyanazon adatokon történő futtatásának adatvédelmi veszteségét úgy, hogy egyszerűen összeadjuk a két elemzés egyedi adatvédelmi veszteségeit. A kompozicionalitás azt jelenti, hogy értelmes garanciákat adhatunk az adatvédelemre vonatkozóan még akkor is, ha ugyanazon adatokból több elemzési eredményt adunk ki. Az olyan technikák, mint az azonosítástalanítás, nem kompozicionálisak, és az ilyen technikák szerinti többszörös kiadás katasztrofális adatvédelmi veszteséget eredményezhet.
Ezek az előnyök az elsődleges okai annak, hogy a szakemberek a differenciált adatvédelmet válasszák más adatvédelmi technikákkal szemben. A differenciált adatvédelem egyik jelenlegi hátránya, hogy meglehetősen új, és a szilárd eszközök, szabványok és legjobb gyakorlatok az akadémiai kutatóközösségeken kívül nem könnyen hozzáférhetőek. Előrejelzésünk szerint azonban ez a korlátozás a közeljövőben leküzdhető lesz, mivel az adatvédelem robusztus és könnyen használható megoldásai iránt egyre nagyobb igény mutatkozik.
Jövőre
Következzenek: a következő bejegyzésünk erre a bejegyzésre épít, és a differenciális adatvédelem rendszereinek telepítésével kapcsolatos biztonsági kérdéseket vizsgálja, beleértve a differenciális adatvédelem központi és helyi modelljei közötti különbséget.
Előtte – szeretnénk, ha ez a sorozat és a későbbi NIST-iránymutatások hozzájárulnának a differenciális adatvédelem hozzáférhetőbbé tételéhez. Ön is segíthet. Akár kérdései vannak ezekkel a bejegyzésekkel kapcsolatban, akár meg tudja osztani a tudását, reméljük, hogy részt vesz velünk, hogy együtt fejleszthessük ezt a tudományágat.
Garfinkel, Simson, John M. Abowd és Christian Martindale. “A nyilvános adatokra irányuló adatbázis-rekonstrukciós támadások megértése”. Communications of the ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “When the signal is in the noise: exploiting diffix’s sticky noise”. 28. USENIX biztonsági szimpózium (USENIX Security 19). 2019.
Dinur, Irit és Kobbi Nissim. “Információ feltárása az adatvédelem megőrzése mellett”. Proceedings of the twenty-second ACM SIGMOD-SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
Sweeney, Latanya. “Az egyszerű demográfiai adatok gyakran egyedileg azonosítják az embereket”. Health (San Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis”. A kriptográfia elmélete konferencia. Springer, Berlin, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke és Salil Vadhan. “Differenciális adatvédelem: A primer for a non-technical audience.” Vand. J. Ent. & Tech. L. 21 (2018): 209.
Dwork, Cynthia és Aaron Roth. “A differenciális adatvédelem algoritmikus alapjai”. Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.